贝特雷金
自我介绍
我在信息技术领域工作超 10 年的时间里,在不同领域积累了丰富的技能和经验。
虚拟化和云计算:
- 熟练使用 VMware 技术,包括 vCenter、HA(高可用性)、vSAN(分布式存储)、虚拟机备份等。
- 在公有云环境中,有丰富的使用经验,如:Aliyun、QingCloud、 AWS or GCP。
服务器和网络管理:
- 熟练使用各 Linux 发行版 Os,以及常用服务器应用如 DHCP、DNS、NFS、SMB 和 iSCSI、NTP/Chronyd。
- Centos/Redhat/Rocklinux
- Ubantu/Linux Mint
- 网络配置和故障排除经验,确保服务器间、应用程序的连通性。
容器化和编排:
- 熟练使用 Kubernetes 和 Cri,能够协助容器化改造、部署、维护。
- docker、podman、containerd、jenkins
- 熟练使用 Helm 等工具来简化 Kubernetes 应用部署更新。
监控和性能优化:
- 熟练使用 Prometheus 和 Grafana 进行监控和性能分析,及通过 Alermanger 及时告警通知,来确保系统的稳定和性能。
- 通过日志分析和指标监控实施自动化故障检测和预防措施。
- 轻度使用 efk、loki、skywallking
持续集成和持续交付(CI/CD):
- 在 Jenkins 和 ArgoCD 中拥有经验,以构建自动化的应用发布流程。
- 整合 GitLab 作为代码管理和协作工具,促进开发团队的协作。
总结而言,我是一名经验丰富的 IT 运维专业人员,擅长虚拟化、云计算、容器化、监控和自动化等多个领域。我的目标是确保系统的高可用性、性能和安全性,并通过持续改进和自动化流程来提高效率。我更热爱学习和不断发展,始终追求在不断变化的 IT 领域中保持竞争力。
使用 GitHub Pages 快速发布
建站 参考链接
Git 安装、初始化
- Mac 中 Git 安装与 GitHub 基本使用
- 生成新的 SSH-key 并且添加到 ssh-agent
- 每年需要更新下 token,在个人用户 setting 中 dev开发这里面创建 token,并设置某个 repo 的访问权限,然后 git clone 时使用 https,git push 提交时提示输入用户密码/密码就是我们创建的 token
记 Kubernetes 1.28.1 之 Kubeadm 安装过程 - 单 master 集群
节点初始化配置
-
更改主机名配置
hostshostnamectl set-hostname --static k8s-master hostnamectl set-hostname --static k8s-worker01 echo '10.2x.2x9.6x k8s-master' >> /etc/hosts echo '10.2x.2x9.6x k8s-worker01' >> /etc/hosts -
禁用
firewalld、selinux、swapsystemctl stop firewalld && systemctl disable firewalld sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config && setenforce 0 && getenforce swapoff -a && sed -i 's@/dev/mapper/centos-swap@#/dev/mapper/centos-swap@g' /etc/fstab -
系统优化
- 加载模块 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack_ipv4 EOF modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 modprobe -- overlay modprobe -- br_netfilter - 检查是否生效 lsmod | grep ip_vs && lsmod | grep nf_conntrack_ipv4 - 配置 ipv4 转发内核参数 cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness = 0 EOF sysctl -p && sysctl --system - 检查内核参数是否生效 sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward -
其余配置
- 根分区扩容 # 可选步骤 lsblk pvcreate /dev/sdb vgextend centos /dev/sdb lvextend -L +99G /dev/mapper/centos-root xfs_growfs /dev/mapper/centos-root - 配置阿里源 wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo - 安装常用工具 yum install -y ipvsadm ipset sysstat conntrack libseccomp wget git net-tools bash-completion
安装必要组件
-
-
cgroup
-
cgroupfs 驱动:是 kubelet 中默认的 cgroup 驱动。 当使用 cgroupfs 驱动时, kubelet 和容器运行时将直接对接 cgroup 文件系统来配置 cgroup
-
systemd 驱动:某个 Linux 系统发行版使用 systemd 作为其初始化系统时,初始化进程会生成并使用一个 root 控制组(cgroup),并充当 cgroup 管理器
-
同时存在两个 cgroup 管理器将造成系统中针对可用的资源和使用中的资源出现两个视图。某些情况下, 将 kubelet 和容器运行时配置为使用
cgroupfs、但为剩余的进程使用systemd的那些节点将在资源压力增大时变得不稳定,所以我们要保证 kubelet 和 docker 的驱动跟系统保持一致,均为 systemd
-
-
安装 containerd
- 解压并将二进制文件放入 /usr/local/ 目录下 tar Cxzvf /usr/local containerd-1.7.5-linux-amd64.tar.gz bin/ bin/containerd-shim-runc-v2 bin/containerd-shim bin/ctr bin/containerd-shim-runc-v1 bin/containerd bin/containerd-stress - 配置systemd # 默认会生成 vi /usr/lib/systemd/system/containerd.service [Unit] Description=containerd container runtime Documentation=https://containerd.io After=network.target local-fs.target [Service] #uncomment to enable the experimental sbservice (sandboxed) version of containerd/cri integration #Environment="ENABLE_CRI_SANDBOXES=sandboxed" ExecStartPre=-/sbin/modprobe overlay ExecStart=/usr/local/bin/containerd Type=notify Delegate=yes KillMode=process Restart=always RestartSec=5 # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNPROC=infinity LimitCORE=infinity LimitNOFILE=infinity # Comment TasksMax if your systemd version does not supports it. # Only systemd 226 and above support this version. TasksMax=infinity OOMScoreAdjust=-999 [Install] WantedBy=multi-user.target - 生成默认配置文件 mkdir -p /etc/containerd/ containerd config default >> /etc/containerd/config.toml - cgroup 驱动更改为 systemd vi /etc/containerd/config.toml [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] ... [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true - 修改 containerd 默认的 pause 镜像 # 默认为境外镜像由于网络问题需要更改为国内源 vi /etc/containerd/config.toml [plugins."io.containerd.grpc.v1.cri"] sandbox_image = "k8s.m.daocloud.io/pause:3.9" # 更改为 k8s.m.daocloud.io,默认为 registry.k8s.io - 重启 containerd systemctl daemon-reload && systemctl restart containerd- 安装 runc
install -m 755 runc.amd64 /usr/local/sbin/runc- 安装 cni - 建议不执行、安装 kubelet 时会自动安装(使用最新的 cni,可能会出现兼容性问题)
mkdir -p /opt/cni/bin tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.3.0.tgz ./ ./macvlan ./static ./vlan ./portmap ./host-local ./vrf ./bridge ./tuning ./firewall ./host-device ./sbr ./loopback ./dhcp ./ptp ./ipvlan ./bandwidth -
-
安装 kubeadm、kubelet、kubectl kubelet 配置文件
- 配置 kubernests 源并安装
[root@k8s-master yum.repos.d]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF - 查看对应组件版本并指定安装版本 # 可选 [root@k8s-master yum.repos.d]# yum list kubeadm --showduplicates [root@k8s-master yum.repos.d]# yum list kubectl --showduplicates [root@k8s-master yum.repos.d]# yum install --setopt=obsoletes=0 kubeadm-1.17.4-0 kubelet-1.17.4-0 kubectl-1.17.4-0 -y - 安装 kubeadm、kubectl 组件 [root@k8s-master yum.repos.d]# yum install --setopt=obsoletes=0 kubeadm-1.28.2-0 kubelet-1.28.2-0 kubectl-1.28.2-0 -y Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.ustc.edu.cn * extras: mirrors.ustc.edu.cn * updates: ftp.sjtu.edu.cn base | 3.6 kB 00:00:00 extras | 2.9 kB 00:00:00 kubernetes | 1.4 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/5): base/7/x86_64/group_gz | 153 kB 00:00:00 (2/5): extras/7/x86_64/primary_db | 250 kB 00:00:00 (3/5): kubernetes/primary | 136 kB 00:00:00 (4/5): updates/7/x86_64/primary_db | 22 MB 00:00:02 (5/5): base/7/x86_64/primary_db | 6.1 MB 00:00:13 kubernetes 1010/1010 Resolving Dependencies --> Running transaction check ---> Package kubeadm.x86_64 0:1.28.1-0 will be installed --> Processing Dependency: kubernetes-cni >= 0.8.6 for package: kubeadm-1.28.1-0.x86_64 --> Processing Dependency: cri-tools >= 1.19.0 for package: kubeadm-1.28.1-0.x86_64 ---> Package kubectl.x86_64 0:1.28.1-0 will be installed ---> Package kubelet.x86_64 0:1.28.1-0 will be installed --> Processing Dependency: socat for package: kubelet-1.28.1-0.x86_64 --> Processing Dependency: conntrack for package: kubelet-1.28.1-0.x86_64 --> Running transaction check ---> Package conntrack-tools.x86_64 0:1.4.4-7.el7 will be installed --> Processing Dependency: libnetfilter_cttimeout.so.1(LIBNETFILTER_CTTIMEOUT_1.1)(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 --> Processing Dependency: libnetfilter_cttimeout.so.1(LIBNETFILTER_CTTIMEOUT_1.0)(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 --> Processing Dependency: libnetfilter_cthelper.so.0(LIBNETFILTER_CTHELPER_1.0)(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 --> Processing Dependency: libnetfilter_queue.so.1()(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 --> Processing Dependency: libnetfilter_cttimeout.so.1()(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 --> Processing Dependency: libnetfilter_cthelper.so.0()(64bit) for package: conntrack-tools-1.4.4-7.el7.x86_64 ---> Package cri-tools.x86_64 0:1.26.0-0 will be installed ---> Package kubernetes-cni.x86_64 0:1.2.0-0 will be installed ---> Package socat.x86_64 0:1.7.3.2-2.el7 will be installed --> Running transaction check ---> Package libnetfilter_cthelper.x86_64 0:1.0.0-11.el7 will be installed ---> Package libnetfilter_cttimeout.x86_64 0:1.0.0-7.el7 will be installed ---> Package libnetfilter_queue.x86_64 0:1.0.2-2.el7_2 will be installed --> Finished Dependency Resolution Dependencies Resolved ================================================================================================================================================================ Package Arch Version Repository Size ================================================================================================================================================================ Installing: kubeadm x86_64 1.28.1-0 kubernetes 11 M kubectl x86_64 1.28.1-0 kubernetes 11 M kubelet x86_64 1.28.1-0 kubernetes 21 M Installing for dependencies: conntrack-tools x86_64 1.4.4-7.el7 base 187 k cri-tools x86_64 1.26.0-0 kubernetes 8.6 M kubernetes-cni x86_64 1.2.0-0 kubernetes 17 M # cni 会安装 /opt/cni/bin/ 网络插件,也就是当前 k8s 版本所兼容的 libnetfilter_cthelper x86_64 1.0.0-11.el7 base 18 k libnetfilter_cttimeout x86_64 1.0.0-7.el7 base 18 k libnetfilter_queue x86_64 1.0.2-2.el7_2 base 23 k socat x86_64 1.7.3.2-2.el7 base 290 k Transaction Summary ================================================================================================================================================================ Install 3 Packages (+7 Dependent packages) Total download size: 69 M Installed size: 292 M Is this ok [y/d/N]: y # y 进行安装即可⚠️:由于官网未开放同步方式, 可能会有 gpg 检查失败的情况, 请用
yum install -y --nogpgcheck kubelet kubeadm kubectl安装来规避 gpg-key 的检查- 启动 kubelet
- 启动 kubelet 服务 [root@k8s-master ~]# systemctl enable kubelet && systemctl start kubelet && systemctl status kubelet Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service. ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: active (running) since Thu 2023-08-31 16:00:25 CST; 11ms ago Docs: https://kubernetes.io/docs/ Main PID: 3011 (kubelet) CGroup: /system.slice/kubelet.service └─3011 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/...
初始化集群配置
-
- 拉取必要镜像 Daocloud-镜像源
- 确认现有版本 kubeadm、kubelet 所需要的镜像版本 [root@k8s-master ~]# kubeadm config images list registry.k8s.io/kube-apiserver:v1.28.1 registry.k8s.io/kube-controller-manager:v1.28.1 registry.k8s.io/kube-scheduler:v1.28.1 registry.k8s.io/kube-proxy:v1.28.1 registry.k8s.io/pause:3.9 registry.k8s.io/etcd:3.5.9-0 registry.k8s.io/coredns/coredns:v1.10.1 - 拉取指定的镜像版本(Daocloud源) [root@k8s-master ~]# kubeadm config images pull --image-repository k8s.m.daocloud.io --kubernetes-version v1.28.1 [config/images] Pulled k8s.m.daocloud.io/kube-apiserver:v1.28.1 [config/images] Pulled k8s.m.daocloud.io/kube-controller-manager:v1.28.1 [config/images] Pulled k8s.m.daocloud.io/kube-scheduler:v1.28.1 [config/images] Pulled k8s.m.daocloud.io/kube-proxy:v1.28.1 [config/images] Pulled k8s.m.daocloud.io/pause:3.9 [config/images] Pulled k8s.m.daocloud.io/etcd:3.5.9-0 [config/images] Pulled k8s.m.daocloud.io/coredns:v1.10.1 - 拉取指定镜像版本() [root@k8s-master ~]# kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.28.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.28.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.28.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.28.1 [config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.9 [config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.9-0 [config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.10.1 -
生成初始化集群配置文件 kubeadm init kubelet
- 打印一个默认的集群配置文件 [root@k8s-master ~]# kubeadm config print init-defaults - 打印一个默认的集群配置文件 - 关于 kubelet 默认配置 kubeadm config print init-defaults --component-configs KubeletConfiguration# clusterConfigfile apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 10.2x.20x.6x # 更改为节点 ip bindPort: 6443 nodeRegistration: criSocket: unix:///var/run/containerd/containerd.sock imagePullPolicy: IfNotPresent name: k8s-master # 更改为节点主机名 taints: null --- apiServer: timeoutForControlPlane: 4m0s # kubeadm install 集群时的超市时间 apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: k8s.m.daocloud.io # 更改为 k8s.m.daocloud.io,默认 registry.k8s.io kind: ClusterConfiguration kubernetesVersion: 1.28.1 # 修改 k8s 版本 networking: dnsDomain: cluster.local podSubnet: 172.16.15.0/22 # 集群的 pod ip 段,冲突的话需要更改 serviceSubnet: 10.96.0.0/12 # 集群的 service ip 段,冲突的话需要更改 scheduler: {} --- kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd # 与系统和 containerd 使用一致的 cgroup 驱动
部署集群
-
使用
mawb-ClusterConfig.yaml安装集群[root@k8s-master ~]# kubeadm init --config mawb-ClusterConfig.yaml [init] Using Kubernetes version: v1.28.1 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' W0831 17:52:06.298929 9686 checks.go:835] detected that the sandbox image "registry.k8s.io/pause:3.8" of the container runtime is inconsistent with that used by kubeadm. It is recommended that using "k8s.m.daocloud.io/pause:3.9" as the CRI sandbox image. [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.2x.2x9.6x] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master localhost] and IPs [10.2x.2x9.6x 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master localhost] and IPs [10.2x.2x9.6x 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [apiclient] All control plane components are healthy after 10.507981 seconds I0831 20:19:17.452642 9052 uploadconfig.go:112] [upload-config] Uploading the kubeadm ClusterConfiguration to a ConfigMap [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace I0831 20:19:17.498585 9052 uploadconfig.go:126] [upload-config] Uploading the kubelet component config to a ConfigMap [kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster I0831 20:19:17.536230 9052 uploadconfig.go:131] [upload-config] Preserving the CRISocket information for the control-plane node I0831 20:19:17.536386 9052 patchnode.go:31] [patchnode] Uploading the CRI Socket information "unix:///var/run/containerd/containerd.sock" to the Node API object "k8s-master" as an annotation [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node k8s-master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule] [bootstrap-token] Using token: abcdef.0123456789abcdef [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace I0831 20:19:19.159977 9052 clusterinfo.go:47] [bootstrap-token] loading admin kubeconfig I0831 20:19:19.160881 9052 clusterinfo.go:58] [bootstrap-token] copying the cluster from admin.conf to the bootstrap kubeconfig I0831 20:19:19.161567 9052 clusterinfo.go:70] [bootstrap-token] creating/updating ConfigMap in kube-public namespace I0831 20:19:19.182519 9052 clusterinfo.go:84] creating the RBAC rules for exposing the cluster-info ConfigMap in the kube-public namespace I0831 20:19:19.209727 9052 kubeletfinalize.go:90] [kubelet-finalize] Assuming that kubelet client certificate rotation is enabled: found "/var/lib/kubelet/pki/kubelet-client-current.pem" [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key I0831 20:19:19.215469 9052 kubeletfinalize.go:134] [kubelet-finalize] Restarting the kubelet to enable client certificate rotation [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: #当前用户执行,使 kubectl 可以访问/管理集群 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.2x.20x.6x:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:3c96533e9c86dcb7fc4b1998716bff804685ef6d40a6635e3357cb92eb4645ed -
配置 kubectl client 使其可以访问、管理集群
To start using your cluster, you need to run the following as a regular user: #当前用户执行,使 kubectl 可以访问/管理集群 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf
接入 worker 节点
-
cri 安装请参考上面步骤
-
kubelet 安装请参考上面步骤
-
节点接入
[root@k8s-worker01 ~]# kubeadm join 10.2x.20x.6x:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:3c96533e9c86dcb7fc4b1998716bff804685ef6d40a6635e3357cb92eb4645ed [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
安装网络插件calico calicoctl
-
⚠️:修改
custom-resources.yamlcidr: 172.16.15.0/22 跟cluster podsubnet一致- 安装 crd kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/tigera-operator.yaml - 修改 image 地址 kubectl edit deployment -n tigera-operator tigera-operator quay.m.daocloud.io/tigera/operator:v1.30.4 - 节点中也要确保可以 pull pause 镜像 ctr image pull k8s.m.daocloud.io/pause:3.9 - 安装 calico kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/custom-resources.yaml installation.operator.tigera.io/default created apiserver.operator.tigera.io/default created - 检查 calico 组件状态 [root@k8s-master ~]# kubectl get pod -A NAMESPACE NAME READY STATUS RESTARTS AGE calico-apiserver calico-apiserver-9bc7d894-5l6m7 1/1 Running 0 2m28s calico-apiserver calico-apiserver-9bc7d894-v7jjm 1/1 Running 0 2m28s calico-system calico-kube-controllers-f44dcdd85-kgfwn 1/1 Running 0 10m calico-system calico-node-655zj 1/1 Running 0 10m calico-system calico-node-8qplv 1/1 Running 0 10m calico-system calico-typha-dd7d8479d-xgb7v 1/1 Running 0 10m calico-system csi-node-driver-cv5sx 2/2 Running 0 10m calico-system csi-node-driver-pd2v7 2/2 Running 0 10m kube-system coredns-56bd89c8d6-d4sgh 1/1 Running 0 15h kube-system coredns-56bd89c8d6-qjfm6 1/1 Running 0 15h kube-system etcd-k8s-master 1/1 Running 0 15h kube-system kube-apiserver-k8s-master 1/1 Running 0 15h kube-system kube-controller-manager-k8s-master 1/1 Running 0 15h kube-system kube-proxy-nqx46 1/1 Running 0 68m kube-system kube-proxy-q6m9r 1/1 Running 0 15h kube-system kube-scheduler-k8s-master 1/1 Running 0 15h tigera-operator tigera-operator-56d54674b6-lbzzf 1/1 Running 1 (30m ago) 36m - 安装 calicoctl as a kubectl plugin on a single host [root@k8s-master01 ~]# curl -L https://github.com/projectcalico/calico/releases/download/v3.26.4/calicoctl-linux-amd64 -o kubectl-calico [root@k8s-master01 ~]# chmod +x kubectl-calico [root@k8s-master01 ~]# kubectl calico -h [root@k8s-master01 ~]# mv kubectl-calico /usr/local/bin/ [root@k8s-master01 ~]# kubectl calico -h Usage: kubectl-calico [options] <command> [<args>...] create Create a resource by file, directory or stdin. replace Replace a resource by file, directory or stdin. apply Apply a resource by file, directory or stdin. This creates a resource if it does not exist, and replaces a resource if it does exists. patch Patch a pre-exisiting resource in place. delete Delete a resource identified by file, directory, stdin or resource type and name. get Get a resource identified by file, directory, stdin or resource type and name. label Add or update labels of resources. convert Convert config files between different API versions. ipam IP address management. node Calico node management. version Display the version of this binary. datastore Calico datastore management. Options: -h --help Show this screen. -l --log-level=<level> Set the log level (one of panic, fatal, error, warn, info, debug) [default: panic] --context=<context> The name of the kubeconfig context to use. --allow-version-mismatch Allow client and cluster versions mismatch. Description: The calico kubectl plugin is used to manage Calico network and security policy, to view and manage endpoint configuration, and to manage a Calico node instance. See 'kubectl-calico <command> --help' to read about a specific subcommand. - 安装 helm 组件 [root@k8s-master01 ~]# twget https://get.helm.sh/helm-v3.13.3-linux-amd64.tar.gz [root@k8s-master01 ~]# tar -zxvf helm-v3.13.3-linux-amd64.tar.gz linux-amd64/ linux-amd64/LICENSE linux-amd64/README.md linux-amd64/helm [root@k8s-master01 ~]# mv linux-amd64/helm /usr/local/bin/helmmv linux-amd64/helm /usr/local/bin/helm^C [root@k8s-master01 ~]# mv linux-amd64/helm /usr/local/bin/helm
client 工具使用与优化
-
containerd 自带
ctr cli工具- containerd 运行时工具 ctr ctr -n k8s.io images export hangzhou_pause:3.4.1.tar.gz registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.4.1 ctr -n k8s.io images import hangzhou_pause:3.4.1.tar.gz ctr -n k8s.io images list -
k8s 社区维护的
crictl工具- crictl 工具 vi /etc/crictl.yaml #请根据实际情况进行更改 runtime-endpoint: unix:///var/run/containerd/containerd.sock image-endpoint: unix:///var/run/containerd/containerd.sock timeout: 10 -
nerdctl 安装
- nerdctl 工具 [root@k8s-master01 ~]# wget https://github.com/containerd/nerdctl/releases/download/v1.7.2/nerdctl-1.7.2-linux-amd64.tar.gz [root@k8s-master01 ~]# tar Cxzvvf /usr/local/bin nerdctl-1.7.2-linux-amd64.tar.gz -rwxr-xr-x root/root 24838144 2023-12-12 19:00 nerdctl -rwxr-xr-x root/root 21618 2023-12-12 18:59 containerd-rootless-setuptool.sh -rwxr-xr-x root/root 7187 2023-12-12 18:59 containerd-rootless.sh - nerdctl 报错 [root@k8s-master01 pig-register]# nerdctl build -t 10.10.1.75:5000:/pig/pig-registry:latest . ERRO[0000] `buildctl` needs to be installed and `buildkitd` needs to be running, see https://github.com/moby/buildkit error="failed to ping to host unix:///run/buildkit-default/buildkitd.sock: exec: \"buildctl\": executable file not found in $PATH\nfailed to ping to host unix:///run/buildkit/buildkitd.sock: exec: \"buildctl\": executable file not found in $PATH" FATA[0000] no buildkit host is available, tried 2 candidates: failed to ping to host unix:///run/buildkit-default/buildkitd.sock: exec: "buildctl": executable file not found in $PATH failed to ping to host unix:///run/buildkit/buildkitd.sock: exec: "buildctl": executable file not found in $PATH - 安装 buildkit(支持 runc 和 containerd 及 非 root 运行) [root@k8s-master01 ~]# wget https://github.com/moby/buildkit/releases/download/v0.12.4/buildkit-v0.12.4.linux-amd64.tar.gz [root@k8s-master01 ~]# tar Cxzvvf /usr/local/ buildkit-v0.12.4.linux-amd64.tar.gz [root@k8s-master01 ~]# vi /usr/lib/systemd/system/buildkit.service [Unit] Description=BuildKit Requires=buildkit.socket After=buildkit.socket Documentation=https://github.com/moby/buildkit [Service] Type=notify ExecStart=/usr/local/bin/buildkitd --addr fd:// [Install] WantedBy=multi-user.target [root@k8s-master01 ~]# vi /usr/lib/systemd/system/buildkit.socket [Unit] Description=BuildKit Documentation=https://github.com/moby/buildkit [Socket] ListenStream=%t/buildkit/buildkitd.sock SocketMode=0660 [Install] WantedBy=sockets.target [root@k8s-master01 ~]# systemctl daemon-reload && systemctl restart buildkitd.service - 构建镜像 [root@k8s-master01 pig-register]# nerdctl build -t pig-registry:latest -f Dockerfile . [+] Building 14.9s (4/7) => [internal] load build definition from Dockerfile 0.0s => => transferring dockerfile: 384B 0.0s => [internal] load metadata for docker.io/alibabadragonwell/dragonwell:17-anolis 2.8s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [1/3] FROM docker.io/alibabadragonwell/dragonwell:17-anolis@sha256:2d31fb3915436ed9f15b4cda936d233419a45a8e35c696d324d6ceadab3d30cc 12.1s => => resolve docker.io/alibabadragonwell/dragonwell:17-anolis@sha256:2d31fb3915436ed9f15b4cda936d233419a45a8e35c696d324d6ceadab3d30cc 0.0s => => sha256:4f4c4e7d1e14aae42ec5ae94c49838c5be9130315ae3e41d56a8670383c0a727 18.39MB / 18.39MB 4.9s => => sha256:1eb01ecdf1afb7abdb39b396b27330b94d3f6b571d766986e2d91916fedad4d1 126B / 126B 1.0s => => sha256:54273d8675f329a1fbcaa73525f4338987bd8e81ba06b9ba72ed9ca63246c834 58.72MB / 82.82MB 12.0s => => sha256:2c5d3d4cbdcb00ce7c1aec91f65faeec72e3676dcc042131f7ec744c371ada32 26.21MB / 193.44MB 12.0s => [internal] load build context 1.1s => => transferring context: 160.19MB 1.1s -
kubectl 自动补全
# 节点需要安装 bash-completion、节点初始化配置已包含 source <(kubectl completion bash) echo "source <(kubectl completion bash)" >> ~/.bashrc
附录
-
kubeadm init 过程中报错
Unfortunately, an error has occurred: timed out waiting for the condition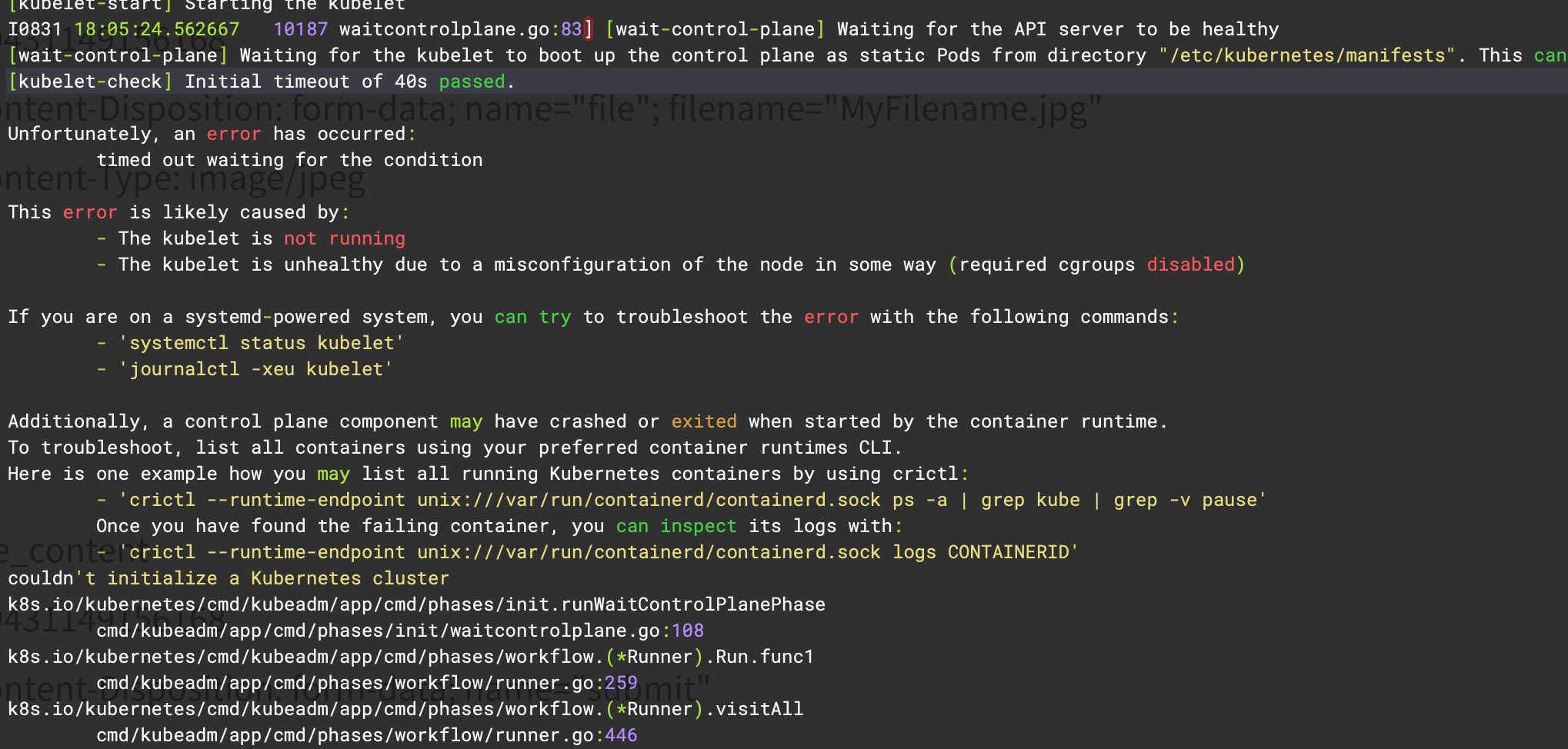
-
现象
- 🈚️任何 pod 创建,kubelet、containerd 没有任何日志且服务运行正常
- 以为是超时导致,更改了 init 时使用的集群配置文件
timeoutForControlPlane: 10m0s无效
-
解决
- 重启节点后,init 集群成功 # 怀疑时 selinux 配置导致的
-
Ingress-nginx
安装 dashabord
[root@controller-node-1 ~]# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
检查状态
[root@controller-node-1 ~]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-7bc864c59-lwlnf 0/1 ContainerCreating 0 10s
kubernetes-dashboard-6c7ccbcf87-55jln 0/1 ContainerCreating 0 10s
[root@controller-node-1 ~]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-7bc864c59-lwlnf 1/1 Running 0 76s
kubernetes-dashboard-6c7ccbcf87-55jln 1/1 Running 0 76s
使用 nodeport/ingress 暴露出来
[root@controller-node-1 ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.233.52.164 <none> 8000/TCP 2m52s
kubernetes-dashboard ClusterIP 10.233.18.137 <none> 443/TCP 2m52s
[root@controller-node-1 ~]# kubectl edit svc -n kubernetes-dashboard kubernetes-dashboard
apiVersion: v1
kind: Service
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"labels":{"k8s-app":"kubernetes-dashboard"},"name":"kubernetes-dashboard","namespace":"kubernetes-dashboard"},"spec":{"ports":[{"port":443,"targetPort":8443}],"selector":{"k8s-app":"kubernetes-dashboard"}}}
creationTimestamp: "2023-12-12T07:58:58Z"
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
resourceVersion: "18237823"
uid: 4d121aa7-791e-4f31-98f9-0b33d8b91d09
spec:
clusterIP: 10.233.18.137
clusterIPs:
- 10.233.18.137
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 443
protocol: TCP
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
annotations: ""
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"networking.k8s.io/v1","kind":"Ingress","metadata":{"annotations":{},"name":"kubernetes-dashboard-ingress","namespace":"kubernetes-dashboard"},"spec":{"ingressClassName":"nginx","rules":[{"host":"mawb.kubernetes.com","http":{"paths":[{"backend":{"service":{"name":"kubernetes-dashboard","port":{"number":443}}},"path":"/","pathType":"Prefix"}]}}]}}
nginx.ingress.kubernetes.io/backend-protocol: HTTPS
creationTimestamp: "2023-12-16T09:17:13Z"
generation: 2
name: kubernetes-dashboard-ingress
namespace: kubernetes-dashboard
resourceVersion: "21457"
uid: 78e57486-96d1-4496-a517-f8382bc53cbf
spec:
ingressClassName: nginx
rules:
- host: mawb.kubernetes.com
http:
paths:
- backend:
service:
name: kubernetes-dashboard
port:
number: 443
path: /
pathType: Prefix
status:
loadBalancer: {}
访问
https://10.29.17.83:32764/#/login
创建 admin 用户
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin
namespace: kubernetes-dashboard
---- 创建 token
[root@controller-node-1 ~]# kubectl -n kubernetes-dashboard create token admin
eyJhbGciOiJSUzI1NiIsImtpZCI6IndhQTNza3VaX0dtTmpOQU84TVNyaDRCaGlRNUVIbmVIXzNzVVc3VnVDaWsifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzAyMzcyMTQ5LCJpYXQiOjE3MDIzNjg1NDksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbiIsInVpZCI6ImIyNGMyZDc0LTkyMTMtNGMyZi04YmQyLWRiMWY3NzdjMzgzMSJ9fSwibmJmIjoxNzAyMzY4NTQ5LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4ifQ.onk5Pu6dieQUvi57mQ18_T942eUHZnE7viqUAklE_Ol3n8dv3uCoP6ieUal98NMEEtjfMinU4Kgn2d9iKnBB0wH8dwLSqawM114Y7GzhndX2XlCQKp55umb3v9wVyfYguqC3Q3F2nV23VjvLzuLoUXLeVU7jrkLEj1wPc7uRk1jMAoCqP5sSZBPFhcO2SduJBWZSEvkq3xJDK_nFYW37wNI3Zs3dglCzAN2RYC_cDjL6u6Mmzys3mFV9vCD41EkOkcAOcvXIkkVEFM52yDBG44LPSCZrYtJLFMwCEsmAisn8UZxBhDKOGebewyyh-cU1bCd8-QYaJWoY5GPQI1y9kQ
---- 创建带时间戳的 token
[root@controller-node-1 ~]# kubectl -n kubernetes-dashboard create token admin --duration 3600m
eyJhbGciOiJSUzI1NiIsImtpZCI6IndhQTNza3VaX0dtTmpOQU84TVNyaDRCaGlRNUVIbmVIXzNzVVc3VnVDaWsifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzAyNjQ2OTc5LCJpYXQiOjE3MDI0MzA5NzksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbiIsInVpZCI6ImIyNGMyZDc0LTkyMTMtNGMyZi04YmQyLWRiMWY3NzdjMzgzMSJ9fSwibmJmIjoxNzAyNDMwOTc5LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4ifQ.XzEqLRNDq2lHE1M_3wRhQTt0V1JgsoKE_iSFASyfDqEkuMa7V8l4YXKWoD-7TAevfObVHavGR19nTqQ8DPQ2jD3MfJGxpEZMkJ3A8HdQ1KLEwf-A_9kbh5gBviNdukhFspLtx7n9P1T9a3otztVwQTf6RqP-VAdBB-6iZfKXzf-zK7jUAbS7eAR--LJ1Wx5lukcUSguyHnZ0kHS1hRH6rUfxeaNLF3Tuk5W4clfPmufOnRT2ocWmfkvyEE5SSJQJd_odludGjx6Yu-ZB5t5OM1AsQDCNNQ7fNxYRdrDWRJCDkBg5UILMjSULCZ2k--VZXTmtxZAPm51j3y4pmt3Yqw
再次登录 UI
开源 UI 调研
- kubeapps:看起来是管理 helm-chart 的一个页面工具,来方便应用的部署和升级,调研下是否有中文界面,使用上需要用户学习 helm 打包,难度中级、页面风格有点类似 vmware 的登录首页
- octant:vmware 开源的 dashboard 页面,和原生提供的页面类似,界面简洁、资源配置丰富,重点调研下
安装神器
- kubean:daocloud 公司开源的一个集群生命周期管理工具
- kubeesz:github 社区挺活跃的
- kubespary:k8s 维护的一个工具,国内大多都是套壳这个
参考文件
CronJob、Job 资源示例
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
suspend: true # 挂起 cronjob,不会影响已经开始的任务
schedule: "* * * * *" # 每分钟执行一次
successfulJobsHistoryLimit: 2 # 保留历史成功数量
failedJobsHistoryLimit: 3 # 保留历史失败数量
jobTemplate: # kind: job
spec:
suspend: true # 挂起 job (true 时运行中 pod 被终止,恢复时 activeDeadlineSeconds 也会重新计时)
completions: 5 # 完成次数 (default: 1)
parallelism: 2 # 并行个数 (default: 1)
backoffLimit: 2 # 重试次数 (default : 1 重启时间按指数曾长<10、20、30>.最多6m)
activeDeadlineSeconds: 20 # job 最大的生命周期,时间到停止所有相关 pod (Job 状态更新为 type: Failed、reason: DeadlineExceeded)
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure # 控制 pod 异常时的动作,重启、异常重启、从不重启
- 有关时区问题如果 cronjob 没有明确指定,那么就按照 kube-controller-manger 指定的时区
探针使用
探针交互
- 容器中配置探针后,kubelet 会按指定配置对 pod 进行健康检查
探针种类
- 存活探针:决定什么时候重启 容器。如:pod 运行正常,但容器内进程启动时需要的依赖条件异常<db、nfs> 导致启动时夯住。
- 就绪探针:决定是否将 pod 相关 service 的 endpoint 摘除。容器运行且进程启动正常才算就绪
- 启动探针:决定容器的启动机制,以及容器启动后进行存活探针/就绪探针的检查。如容器启动耗时较长
探针检查结果
- Success:通过检查
- Failure:未通过检查
- Unknown:探测失败,不会采取任何行动
探针编写层级
- Pod: .spec.contaiers.livenessProbe
- Pod: .spec.contaiers.readinessProbe
- Pod: .spec.contaiers.startupProbe
探针检查方法
-
exec:相当于 command / shell 进行检查,支持 initialDelaySeconds / periodSeconds
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: registry.k8s.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5 -
httpGet:相当于 http 请求,支持 initialDelaySeconds / periodSeconds / Headers / port: .ports.name
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-http spec: containers: - name: liveness image: registry.k8s.io/liveness args: - /server livenessProbe: httpGet: path: /healthz port: 8080 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 3 periodSeconds: 3 -
tcpSocket: 相当于 telnet 某个端口(kubelet 建立套接字链接),支持 initialDelaySeconds / periodSeconds / Headers / port: .spec.containers.ports.name
apiVersion: v1 kind: Pod metadata: name: goproxy labels: app: goproxy spec: containers: - name: goproxy image: registry.k8s.io/goproxy:0.1 ports: - containerPort: 8080 readinessProbe: tcpSocket: port: 8080 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: tcpSocket: port: 8080 initialDelaySeconds: 15 periodSeconds: 20 --- port 支持使用 ports.name ports: - name: liveness-port containerPort: 8080 hostPort: 8080 livenessProbe: httpGet: path: /healthz port: liveness-port -
grpc:首先应用要支持该方法,且 grpc 的话,pod 中必须要定义 .spec.containers.ports 字段
apiVersion: v1 kind: Pod metadata: name: etcd-with-grpc spec: containers: - name: etcd image: registry.k8s.io/etcd:3.5.1-0 command: [ "/usr/local/bin/etcd", "--data-dir", "/var/lib/etcd", "--listen-client-urls", "http://0.0.0.0:2379", "--advertise-client-urls", "http://127.0.0.1:2379", "--log-level", "debug"] ports: - containerPort: 2379 livenessProbe: grpc: port: 2379 initialDelaySeconds: 10 -
启动探针、存活探针使用
ports: - name: liveness-port containerPort: 8080 hostPort: 8080 livenessProbe: httpGet: path: /healthz port: liveness-port failureThreshold: 1 periodSeconds: 10 startupProbe: httpGet: path: /healthz port: liveness-port failureThreshold: 30 #次数 periodSeconds: 10 - startupProbe 检查通过时,才会执行所配置的存活探针和就绪探针。 - startupProbe 探测配置建议:failureThreshold * periodSeconds(案例是5m,后执行就绪检查)
探针配置
Pod 生命周期
ConfigMaps
ConfigMap 是什么?
- 非 🔐 数据以
key:value的形式保存 - Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件
- 将你的环境配置信息和 容器镜像 进行解耦,便于应用配置的修改及多云场景下应用的部署
- 与 ConfigMap 所对应的就是 Secret (加密数据)
ConfigMap 的特性
- 名字必须是一个合法的 DNS 子域名
data或binaryData字段下面的键名称必须由字母数字字符或者-、_或.组成、键名不可有重叠- v1.19 开始,可以添加
immutable字段到 ConfigMap 定义中,来创建 不可变更的 ConfigMap - ConfigMap 需要跟引用它的资源在同一命名空间下
- ConfigMap 更新新,应用会自动更新,kubelet 会定期检索配置是否最新
- SubPath 卷挂载的容器将不会收到 ConfigMap 的更新,需要重启应用
如何使用 ConfigMap
-
创建一个 ConfigMap 资源或者使用现有的 ConfigMap,多个 Pod 可以引用同一个 ConfigMap 资源
-
修改 Pod 定义,在
spec.volumes[]下添加一个卷。 为该卷设置任意名称,之后将 -
为每个需要该 ConfigMap 的容器添加一个 volumeMount
-
设置
.spec.containers[].volumeMounts[].name定义卷挂载点的名称 -
设置
.spec.containers[].volumeMounts[].readOnly=true -
设置
.spec.containers[].volumeMounts[].mountPath定义一个未使用的目录
-
-
更改你的 Yaml 或者命令行,以便程序能够从该目录中查找文件。ConfigMap 中的每个
data键会变成mountPath下面的一个文件名
场景
基于文件创建 ConfigMap
使用 kubectl create configmap 基于单个文件或多个文件创建 ConfigMap
# 文件如下:
[root@master01 ~]# cat /etc/resolv.conf
nameserveer 1.1.1.1
# 创建 ConfigMap
[root@master01 ~]# kubectl create configmap dnsconfig --from-file=resolve.conf
[root@master01 ~]# kubectl get configmap dnsconfig -o yaml
apiVersion: v1
data:
resolve.conf: |
nameserveer 1.1.1.1
kind: ConfigMap
metadata:
name: dnsconfig
namespace: default
Deployment 使用所创建的 ConfigMap 资源 Configure a Pod to Use a ConfigMap
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: dao-2048-2-test
name: dao-2048-2-test-dao-2048
namespace: default
spec:
replicas: 1
selector:
matchLabels:
component: dao-2048-2-test-dao-2048
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: dao-2048-2-test
name: dao-2048-2-test-dao-2048
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
- key: kubernetes.io/arch
operator: In
values:
- amd64
containers:
- image: x.x.x.x/dao-2048/dao-2048:latest
imagePullPolicy: Always
name: dao-2048-2-test-dao-2048
resources:
limits:
cpu: 100m
memory: "104857600"
requests:
cpu: 100m
memory: "104857600"
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/resolv.conf
name: configmap-dns
subPath: resolv.conf
dnsConfig:
nameservers:
- 192.0.2.1
dnsPolicy: None
imagePullSecrets:
- name: dao-2048-2-test-dao-2048-10.29.140.12
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
items:
- key: resolve.conf
path: resolv.conf
name: dnsconfig
name: configmap-dns
配置说明
# volumeMounts
volumeMounts:
- mountPath: /etc/resolv.conf # 定义容器内挂载路径
name: configmap-dns # 定义卷挂载点名称,以便 volumes 使用该名称挂载 configmap 资源
subPath: resolv.conf # 指定所引用的卷内的子文件/子路径,而不是其根路径
# volumes
volumes:
- name: configmap-dns
configMap:
name: dnsconfig # 引用所创建的 configmap 资源 dnsconfig
defaultMode: 420
items: # 引用对应的 key,将其创建问文件
- key: resolve.conf # .data.resolve.conf
path: resolv.conf # 将 resolve.conf `key` 创建成 resolv.conf 文件
疑问 (为什么使用了 dnsConfig 的前提下,又将 resolv.conf 以 configmap 的形式注入容器中呢)
- 做测试,看 k8s 下以哪个配置生效,结果是 configmap 的形 会覆盖 yaml 定义的 dnsConfig 配置
- 在多云场景中,需要区分出应用配置的差异化,所以才考虑使用 configmap 的形式实现,在单一环境中推荐在 yaml 中直接定义 dnsCofnig
dnsPolicy: None
dnsConfig:
nameservers:
- 192.0.2.1
dnsPolicy: None
一次 kubelet PLEG is not healthy 报错事项
排查记录
-
现象:
-
节点 PLEG is not healthy 报错
Jul 03 19:59:01 xxx-worker-004 kubelet[1946644]: E0703 19:59:01.292918 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m36.462980645s ago; threshold is 3m0s Jul 03 19:59:06 xxx-worker-004 kubelet[1946644]: E0703 19:59:06.293545 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m41.463610227s ago; threshold is 3m0s Jul 03 19:59:07 xxx-worker-004 kubelet[1946644]: I0703 19:59:07.513240 1946644 setters.go:77] Using node IP: "xxxxxx" Jul 03 19:59:11 xxx-worker-004 kubelet[1946644]: E0703 19:59:11.294548 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m46.464602826s ago; threshold is 3m0s Jul 03 19:59:16 xxx-worker-004 kubelet[1946644]: E0703 19:59:16.294861 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m51.464916622s ago; threshold is 3m0s Jul 03 19:59:17 xxx-worker-004 kubelet[1946644]: I0703 19:59:17.585868 1946644 setters.go:77] Using node IP: "xxxxxx" -
节点短暂性 NotReady、且有获取 / kill container 状态失败的 log
--- container 状态失败的 log Jul 03 19:59:24 xxx-worker-004 kubelet[1946644]: E0703 19:59:24.854445 1946644 remote_runtime.go:295] ContainerStatus "bdf4dc0af526a317e248c994719eabb233a9db337d535351a277b1b324cf5fec" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jul 03 19:59:24 xxx-worker-004 kubelet[1946644]: E0703 19:59:24.854492 1946644 kuberuntime_manager.go:969] getPodContainerStatuses for pod "dss-controller-pod-658c484975-zq9mh_dss(65f4d584-88df-4fb7-bf04-d2a20a4273e3)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jul 03 19:59:25 xxx-worker-004 kubelet[1946644]: E0703 19:59:25.996630 1946644 kubelet_pods.go:1247] Failed killing the pod "dss-controller-pod-658c484975-zq9mh": failed to "KillContainer" for "dss-controller-pod" with KillContainerError: "rpc error: code = DeadlineExceeded desc = context deadline exceeded" --- PLEG is not healthy / Node became not ready 的 log Jul 03 20:02:24 xxx-worker-004 kubelet[1946644]: I0703 20:02:24.508392 1946644 kubelet.go:1948] SyncLoop (UPDATE, "api"): "dx-insight-stolon-keeper-1_dx-insight(895aded8-7556-4c00-aca5-6c6e7aacf7a2)" Jul 03 20:02:25 xxx-worker-004 kubelet[1946644]: E0703 20:02:25.989898 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.135142317s ago; threshold is 3m0s Jul 03 20:02:26 xxx-worker-004 kubelet[1946644]: E0703 20:02:26.090013 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.235263643s ago; threshold is 3m0s Jul 03 20:02:26 xxx-worker-004 kubelet[1946644]: E0703 20:02:26.290144 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.435377809s ago; threshold is 3m0s Jul 03 20:02:26 xxx-worker-004 kubelet[1946644]: E0703 20:02:26.690286 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.835524997s ago; threshold is 3m0s Jul 03 20:02:27 xxx-worker-004 kubelet[1946644]: E0703 20:02:27.490434 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m1.63566563s ago; threshold is 3m0s Jul 03 20:02:28 xxx-worker-004 kubelet[1946644]: I0703 20:02:28.903852 1946644 setters.go:77] Using node IP: "xxxxxx" Jul 03 20:02:28 xxx-worker-004 kubelet[1946644]: I0703 20:02:28.966272 1946644 kubelet_node_status.go:486] Recording NodeNotReady event message for node xxx-worker-004 Jul 03 20:02:28 xxx-worker-004 kubelet[1946644]: I0703 20:02:28.966300 1946644 setters.go:559] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2023-07-03 20:02:28.966255129 +0800 CST m=+7095087.092396567 LastTransitionTime:2023-07-03 20:02:28.966255129 +0800 CST m=+7095087.092396567 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m3.111515826s ago; threshold is 3m0s} --- 每次 pleg 都有获取 container 状态失败的 log,也有在 pleg 之前的 log Jul 03 20:03:25 xxx-worker-004 kubelet[1946644]: E0703 20:03:25.881543 1946644 remote_runtime.go:295] ContainerStatus "bdf4dc0af526a317e248c994719eabb233a9db337d535351a277b1b324cf5fec" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jul 03 20:03:25 xxx-worker-004 kubelet[1946644]: E0703 20:03:25.881593 1946644 kuberuntime_manager.go:969] getPodContainerStatuses for pod "dss-controller-pod-658c484975-zq9mh_dss(65f4d584-88df-4fb7-bf04-d2a20a4273e3)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded Jul 03 20:06:26 xxx-worker-004 kubelet[1946644]: I0703 20:06:26.220050 1946644 kubelet.go:1948] SyncLoop (UPDATE, "api"): "dx-insight-stolon-keeper-1_dx-insight(895aded8-7556-4c00-aca5-6c6e7aacf7a2)" Jul 03 20:06:26 xxx-worker-004 kubelet[1946644]: E0703 20:06:26.989827 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.108053792s ago; threshold is 3m0s Jul 03 20:06:27 xxx-worker-004 kubelet[1946644]: E0703 20:06:27.089940 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.208169468s ago; threshold is 3m0s Jul 03 20:06:27 xxx-worker-004 kubelet[1946644]: E0703 20:06:27.290060 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.408291772s ago; threshold is 3m0s Jul 03 20:06:27 xxx-worker-004 kubelet[1946644]: E0703 20:06:27.690186 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.808415818s ago; threshold is 3m0s Jul 03 20:06:28 xxx-worker-004 kubelet[1946644]: E0703 20:06:28.490307 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m1.608530704s ago; threshold is 3m0s Jul 03 20:06:30 xxx-worker-004 kubelet[1946644]: E0703 20:06:30.090657 1946644 kubelet.go:1879] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m3.208885327s ago; threshold is 3m0s Jul 03 20:06:30 xxx-worker-004 kubelet[1946644]: I0703 20:06:30.557003 1946644 setters.go:77] Using node IP: "xxxxxx" Jul 03 20:06:30 xxx-worker-004 kubelet[1946644]: I0703 20:06:30.616041 1946644 kubelet_node_status.go:486] Recording NodeNotReady event message for node xxx-worker-004 -
当前状态下,节点可以创建 、删除 pod (约 2-3 份钟一次 pleg 报错,持续 1-2 分钟左右)
-
dockerd 相关日志 (某个容器异常后,触发了 dockerd 的 stream copy error: reading from a closed fifo 错误,20分钟后开始打 Pleg 日志 )
Sep 11 15:24:35 [localhost] kubelet: I0911 15:24:35.062990 3630 setters.go:77] Using node IP: "172.21.0.9" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.535271938+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.535330354+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.536568097+08:00" level=error msg="Error running exec 18c5bcece71bee792912ff63a21b29507a597710736a131f03197fec1c44e8f7 in container: OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"ps\": executable file not found in $PATH: unknown" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.825485167+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.825494046+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:36 [localhost] dockerd: time="2023-09-11T15:24:36.826617470+08:00" level=error msg="Error running exec 6a68fb0d78ff1ec6c1c302a40f9aa80f0be692ba6971ae603316acc8f2245cf1 in container: OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"ps\": executable file not found in $PATH: unknown" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.323407978+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.323407830+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.324556918+08:00" level=error msg="Error running exec 824f974debe302cea5db269e915e3ba26e2e795df4281926909405ba8ef82f10 in container: OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"ps\": executable file not found in $PATH: unknown" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.636923557+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.636924060+08:00" level=error msg="stream copy error: reading from a closed fifo" Sep 11 15:24:38 [localhost] dockerd: time="2023-09-11T15:24:38.638120772+08:00" level=error msg="Error running exec 5bafe0da5f5240e00c2e6be99e859da7386276d49c6d907d1ac7df2286529c1e in container: OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"ps\": executable file not found in $PATH: unknown" Sep 11 15:24:39 [localhost] kubelet: W0911 15:24:39.181878 3630 kubelet_pods.go:880] Unable to retrieve pull secret n-npro-dev/harbor for n-npro-dev/product-price-frontend-846f84c5b9-cpd4q due to secret "harbor" not found. The image pull may not succeed.
-
-
排查方向
-
节点负载不高
-
cpu/memory 正常范围内
-
dockerd 文件句柄 1.9+
lsof -p $(cat /var/run/docker.pid) |wc -l
-
-
容器数量对比其他节点也没有很多
-
docker ps / info 正常输出
-
发现有残留的 container 和 pasue 容器,手动 docker rm -f 无法删除(发现 up 容器可以 inspect、残留的不行)
-
最后通过 kill -9 $pid 杀了进程,残留容器被清理
ps -elF | egrep "进程名/PID" #别杀错了呦,大兄弟!!!
-
-
后续再遇到可以看下 containerd 的日志
journalctl -f -u containerd docker stats # 看是有大量的残留容器
-
-
dockerd 开启 debug 模式 - 已搜集
-
kubelet 在 调整为 v4 重启后报错
Jul 03 20:10:48 xxx-worker-004 kubelet[465378]: I0703 20:10:48.289216 465378 status_manager.go:158] Starting to sync pod status with apiserver Jul 03 20:10:48 xxx-worker-004 kubelet[465378]: I0703 20:10:48.289245 465378 kubelet.go:1855] Starting kubelet main sync loop. Jul 03 20:10:48 xxx-worker-004 kubelet[465378]: E0703 20:10:48.289303 465378 kubelet.go:1879] skipping pod synchronization - [container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]-
查看是否由于 apiserver 限流导致的 worker 节点短暂性 NotReady
- 重启后拿的数据,没有参考意义,3*master 数据最大的 18
-
残留容器的清理过层
- 残留容器 [root@dce-worker-002 ~]# docker ps -a | grep 'dss-controller' cd99bc468028 3458637e441b "/usr/local/bin/moni…" 25 hours ago Up 25 hours k8s_dss-controller-pod_dss-controller-pod-66c79dd5ff-nvmg6_dss_e04c891f-1101-401f-bbdc-65f08c6261b5_0 ed56fd84a466 172.21.0.99/kube-system/dce-kube-pause:3.1 "/pause" 25 hours ago Up 25 hours k8s_POD_dss-controller-pod-66c79dd5ff-nvmg6_dss_e04c891f-1101-401f-bbdc-65f08c6261b5_0 1ea1fc956e08 172.21.0.99/dss-5/controller "/usr/local/bin/moni…" 2 months ago Up 2 months k8s_dss-controller-pod_dss-controller-pod-ddb8dd4-h8xff_dss_745deb5c-3aa0-4584-a627-908d9fd142fb_0 74ea748ea198 172.21.0.99/kube-system/dce-kube-pause:3.1 "/pause" 2 months ago Exited (0) 25 hours ago k8s_POD_dss-controller-pod-ddb8dd4-h8xff_dss_745deb5c-3aa0-4584-a627-908d9fd142fb_0 - 清理过程 (通过 up 的容器获取到进程名,然后 ps 检索出来) [root@dce-worker-002 ~]# ps -elF | grep "/usr/local/bin/monitor -c" 4 S root 1428645 1428619 0 80 0 - 636 poll_s 840 15 Jul10 ? 00:01:55 /usr/local/bin/monitor -c 4 S root 2939390 2939370 0 80 0 - 636 poll_s 752 5 Sep11 ? 00:00:01 /usr/local/bin/monitor -c 0 S root 3384975 3355866 0 80 0 - 28203 pipe_w 972 23 16:04 pts/0 00:00:00 grep --color=auto /usr/local/bin/monitor -c [root@dce-worker-002 ~]# ps -elF | egrep "1428619|1428645" 0 S root 1428619 1 0 80 0 - 178392 futex_ 12176 22 Jul10 ? 01:47:37 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 1ea1fc956e08ceecb1b729b2553e47ae8cb6dd954e4096afb23d604f814d3fb9 -address /run/containerd/containerd.sock # 这个是所有容器的父进程 containerd,不要杀了 4 S root 1428645 1428619 0 80 0 - 636 poll_s 840 3 Jul10 ? 00:01:55 /usr/local/bin/monitor -c 0 S root 3299955 1428619 0 80 0 - 209818 futex_ 12444 30 Aug13 ? 00:00:01 runc --root /var/run/docker/runtime-runc/moby --log /run/containerd/io.containerd.runtime.v2.task/moby/1ea1fc956e08ceecb1b729b2553e47ae8cb6dd954e4096afb23d604f814d3fb9/log.json --log-format json exec --process /tmp/runc-process119549742 --detach --pid-file /run/containerd/io.containerd.runtime.v2.task/moby/1ea1fc956e08ceecb1b729b2553e47ae8cb6dd954e4096afb23d604f814d3fb9/b1f66414652628a5e3eea0b59d7ee09c0a2a76bcb6f491e3d911536b310c430a.pid 1ea1fc956e08ceecb1b729b2553e47ae8cb6dd954e4096afb23d604f814d3fb9 0 R root 3387029 3355866 0 80 0 - 28203 - 980 30 16:05 pts/0 00:00:00 grep -E --color=auto 1428619|1428645 0 S root 3984582 1428645 0 80 0 - 838801 futex_ 36652 10 Aug13 ? 00:11:32 /usr/local/bin/controller -j dss-svc-controller.dss -a 10.202.11.63 -b 10.202.11.63 [root@dce-worker-002 ~]# kill -9 1428645 [root@dce-worker-002 ~]# kill -9 3984582
-
-
结论
-
节点中有残留的容器且 dokcer cli 无法正常删除、及 kubelet 获取容器状态时有 rpc failed 报错
-
在 kubelet 调整为 v4 level 的 log 日志后,重启 kubelet 也报 dockerd 检查异常
-
通过 kubelet 的监控来看,整个响应时间是在正常范围内的,因此 k8s 层面应该没有问题
通过以上结论,怀疑是 kubelet 调用 docker 去获取容器状态信息时异常导致的节点短暂性 NotReady,重启节点后恢复状态恢复正常
-
-
后续措施
- 监控 apiserver 性能数据,看是否有限流和响应慢的现象
- 优化集群中应用,发现应用使用了不存在 secret 来 pull 镜像,导致 pull 失败错误 1d 有 5w+条,增加了 kubelet 与 apiserver 通信的开销
-
做的不足的地方
- 没有拿 dockerd 堆栈的信息
- apiserver kubelet 的监控
- 在重启后看了 apiserver 是否有限流现象 (虽然嫌疑不大,worker 节点重启后 3*master 都不高)
- kubelet 的 relist 函数监控没有查看
环境信息搜集步骤
-
在不重启 dockerd 的情况下搜集 debug 日志和 堆栈 信息
- 开启 dockerd debug 模式 [root@worker03 ~]# vi /etc/docker/daemon.json { "storage-driver": "overlay2", "log-opts": { "max-size": "100m", "max-file": "3" }, "storage-opts": [ "overlay2.size=10G" ], "insecure-registries": [ "0.0.0.0/0" ], "debug": true, # 新增 "log-driver": "json-file" } kill -SIGHUP $(pidof dockerd) journalctl -f -u docker > docker-devbug.info - 打印堆栈信息 kill -SIGUSR1 $(pidof dockerd) cat docker-devbug.info | grep goroutine # 检索堆栈日志文件在哪个路径下 cat docker-devbug.info | grep datastructure # 这个我的环境没有 -
查看 apiserver 是否有限流的现象
- 获取具有集群 admin 权限的 clusterrolebinding 配置、或者自行创建对应的 clusterrole、clusterrolebinding、serviceaccount kubectl get clusterrolebindings.rbac.authorization.k8s.io | grep admin - 查看 clusterrolebinding 所使用的 serviceaccount 和 secret kubectl get clusterrolebindings.rbac.authorization.k8s.io xxx-admin -o yaml kubectl get sa -n kube-system xxx-admin -o yaml kubectl get secrets -n kube-system xxx-admin-token-rgqxl -o yaml echo "$token" | base64 -d > xxx-admin.token - 查看 apiserver 所有的 api 接口 、也可获取 kubelet 等其他组件的堆栈信息 curl --cacert /etc/daocloud/xxx/cert/apiserver.crt -H "Authorization: Bearer $(cat /root/xxx-admin.token)" https://$ip:16443 -k - 通过 metrics 接口查看监控数据 curl --cacert /etc/daocloud/xxx/cert/apiserver.crt -H "Authorization: Bearer $(cat /root/xxx-admin.token)" https://$ip:16443/metrics -k > apiserver_metrics.info - 查看这三个指标来看 apiserver 是否触发了限流 cat apiserver_metrics.info | grep -E "apiserver_request_terminations_total|apiserver_dropped_requests_total|apiserver_current_inflight_requests" - 通过 kubelet metrics 查看当时更新状态时卡在什么位置 curl --cacert /etc/daocloud/xxx/cert/apiserver.crt -H "Authorization: Bearer $(cat /root/xxx-admin.token)" https://127.0.0.1:10250/debug/pprof/goroutine?debug=1 -k curl --cacert /etc/daocloud/xxx/cert/apiserver.crt -H "Authorization: Bearer $(cat /root/xxx-admin.token)" https://127.0.0.1:10250/debug/pprof/goroutine?debug=2 -k -
通过 prometheus 监控查看 kubelet 性能数据
- pleg 中 relist 函数负责遍历节点容器来更新 pod 状态(relist 周期 1s,relist 完成时间 + 1s = kubelet_pleg_relist_interval_microseconds) kubelet_pleg_relist_interval_microseconds kubelet_pleg_relist_interval_microseconds_count kubelet_pleg_relist_latency_microseconds kubelet_pleg_relist_latency_microseconds_count - kubelet 遍历节点中容器信息 kubelet_runtime_operations{operation_type="container_status"} 472 kubelet_runtime_operations{operation_type="create_container"} 93 kubelet_runtime_operations{operation_type="exec"} 1 kubelet_runtime_operations{operation_type="exec_sync"} 533 kubelet_runtime_operations{operation_type="image_status"} 579 kubelet_runtime_operations{operation_type="list_containers"} 10249 kubelet_runtime_operations{operation_type="list_images"} 782 kubelet_runtime_operations{operation_type="list_podsandbox"} 10154 kubelet_runtime_operations{operation_type="podsandbox_status"} 315 kubelet_runtime_operations{operation_type="pull_image"} 57 kubelet_runtime_operations{operation_type="remove_container"} 49 kubelet_runtime_operations{operation_type="run_podsandbox"} 28 kubelet_runtime_operations{operation_type="start_container"} 93 kubelet_runtime_operations{operation_type="status"} 1116 kubelet_runtime_operations{operation_type="stop_container"} 9 kubelet_runtime_operations{operation_type="stop_podsandbox"} 33 kubelet_runtime_operations{operation_type="version"} 564 - kubelet 遍历节点中容器的耗时 kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.5"} 12117 kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.9"} 26607 kubelet_runtime_operations_latency_microseconds{operation_type="container_status",quantile="0.99"} 27598 kubelet_runtime_operations_latency_microseconds_count{operation_type="container_status"} 486 kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.5"} 29972 kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.9"} 47907 kubelet_runtime_operations_latency_microseconds{operation_type="list_containers",quantile="0.99"} 80982 kubelet_runtime_operations_latency_microseconds_count{operation_type="list_containers"} 10812 kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.5"} 18053 kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.9"} 28116 kubelet_runtime_operations_latency_microseconds{operation_type="list_podsandbox",quantile="0.99"} 68748 kubelet_runtime_operations_latency_microseconds_count{operation_type="list_podsandbox"} 10712 kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.5"} 4918 kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.9"} 15671 kubelet_runtime_operations_latency_microseconds{operation_type="podsandbox_status",quantile="0.99"} 18398 kubelet_runtime_operations_latency_microseconds_count{operation_type="podsandbox_status"} 323 -
如何通过 prometheus 监控 kube_apiserver
- 待补充 -
快速搜集节点当前性能数据信息
mkdir -p /tmp/pleg-log cd /tmp/pleg-log journalctl -f -u docker > dockerd.log journalctl -f -u containerd > dockerd.log ps -elF > ps.log top -n 1 > top.log pstree > pstree.log netstat -anltp > netsat.log sar -u > sar.cpu.log iostat > iostat.log iotop -n 2 > iotop.log top -n 1 >> top.log df -h > df.log timeout 5 docker ps -a > docker.ps.log timeout 5 docker stats --no-stream > docker.ps.log free -lm > free.log service kubelet status > kubelet.status service docker status > docker.status
podman containers 数据软链
停止 podman 容器
# 暂停容器
podman ps -q | xargs podman pause
5f375c9d1750
# 检查容器状态
podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5f375c9d1750 docker.m.daocloud.io/kindest/node:v1.26.2 2 weeks ago Paused 0.0.0.0:443->30443/tcp, 0.0.0.0:8081->30081/tcp, 0.0.0.0:9000-9001->32000-32001/tcp, 0.0.0.0:16443->6443/tcp my-cluster-installer-control-plane
备份数据
# cp 数据到 /home/kind/podman-containers/ 目录下
mkdir -p /home/kind/podman-containers
cp -rf /var/lib/containers/* /home/kind/podman-containers/
# 备份数据
cd /var/lib/
tar -zcvf /home/kind/podman-containers/containers.tgz containers
清理数据
# 检查是否有 container 的 tmp 目录在挂载
df -hT | grep containers
shm tmpfs 63M 0 63M 0% /var/lib/containers/storage/overlay-containers/5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72/userdata/shm
fuse-overlayfs fuse.fuse-overlayfs 546G 220G 326G 41% /var/lib/containers/storage/overlay/0cec29426340872d7368db0571a3fc26731040f6e7a9ccd92e2442441f44de84/merged
# 有则 umount 掉,否则 rm 时会失败
umount /var/lib/containers/storage/overlay-containers/5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72/userdata/shm
umount /var/lib/containers/storage/overlay/0cec29426340872d7368db0571a3fc26731040f6e7a9ccd92e2442441f44de84/merged
# 删除数据
cd /var/lib/
rm -rf containers/*
rm: 无法删除"containers/storage/overlay": 设备或资源忙, # 貌似要多删除几次
配置软链并恢复容器
# 软链
ln -vs /home/kind/podman-containers/storage /var/lib/containers/storage
ln -vs /home/kind/podman-containers/docker /var/lib/containers/docker
ln -vs /home/kind/podman-containers/cache /var/lib/containers/cache
# 如何删除 软链
unlink /var/lib/containers/cache
# 查看结果
ls -l
总用量 0
lrwxrwxrwx. 1 root root 11 1月 24 15:38 cache -> /home/kind/podman-containers/cache
lrwxrwxrwx. 1 root root 12 1月 24 15:38 docker -> /home/kind/podman-containers/docker
lrwxrwxrwx. 1 root root 13 1月 24 15:41 storage -> /home/kind/podman-containers/storage
# 启动容器
podman unpause 5f375c9d1750
5f375c9d1750
# 检查容器状态
podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5f375c9d1750 docker.m.daocloud.io/kindest/node:v1.26.2 2 weeks ago Up 2 weeks 0.0.0.0:443->30443/tcp, 0.0.0.0:8081->30081/tcp, 0.0.0.0:9000-9001->32000-32001/tcp, 0.0.0.0:16443->6443/tcp my-cluster-installer-control-plane
最后检查
# exec 进容器异常,需要手动重启下容器
podman exec -it 5f37 /bin/bash
Error: runc: exec failed: unable to start container process: exec: "/bin/bash": stat /bin/bash: no such file or directory: OCI runtime attempted to invoke a command that was not found
# 重启容器
podman restart 5f37
WARN[0010] StopSignal (37) failed to stop container my-cluster-installer-control-plane in 10 seconds, resorting to SIGKILL
ERRO[0013] Cleaning up container 5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72: unmounting container 5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72 storage: cleaning up container 5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72 storage: unmounting container 5f375c9d1750c5e5705467541ac92c23f6a338998cd1d2881dcdab1485a0be72 root filesystem: removing mount point "/var/lib/containers/storage/overlay/0cec29426340872d7368db0571a3fc26731040f6e7a9ccd92e2442441f44de84/merged": directory not empty
Error: OCI runtime error: runc: runc create failed: invalid rootfs: not an absolute path, or a symlink
# 重启后检查,容器运行正常
podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5f375c9d1750 docker.m.daocloud.io/kindest/node:v1.26.2 2 weeks ago Up 22 seconds 0.0.0.0:443->30443/tcp, 0.0.0.0:8081->30081/tcp, 0.0.0.0:9000-9001->32000-32001/tcp, 0.0.0.0:16443->6443/tcp my-cluster-installer-control-plane
# 再次进容器,检查点火各组件pod 状态,均恢复正常
podman exec -it 5f37 /bin/bash
root@my-cluster-installer-control-plane:/# kubectl get node
NAME STATUS ROLES AGE VERSION
my-cluster-installer-control-plane Ready control-plane 17d v1.26.2
root@my-cluster-installer-control-plane:/# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-787d4945fb-fs7b6 1/1 Running 1 (31s ago) 17d
kube-system coredns-787d4945fb-hscmx 1/1 Running 1 (31s ago) 17d
kube-system etcd-my-cluster-installer-control-plane 1/1 Running 0 20s
kube-system kindnet-hmhfb 1/1 Running 2 (31s ago) 17d
kube-system kube-apiserver-my-cluster-installer-control-plane 1/1 Running 0 20s
kube-system kube-controller-manager-my-cluster-installer-control-plane 1/1 Running 1 (31s ago) 17d
kube-system kube-proxy-2lz72 1/1 Running 1 (31s ago) 16d
kube-system kube-scheduler-my-cluster-installer-control-plane 1/1 Running 1 (31s ago) 17d
kubean-system kubean-admission-5d4768f9cf-7tqqq 1/1 Running 1 (31s ago) 17d
kubean-system kubean-c6b8c997-zchfh 1/1 Running 1 (31s ago) 17d
kubean-system kubean-my-cluster-ops-job-w68tm 0/1 Completed 0 17d
local-path-storage local-path-provisioner-84f55fc489-m9hbf 1/1 Running 1 (31s ago) 17d
minio-system minio-5888c499dd-vxrpk 1/1 Running 1 (31s ago) 17d
museum-system chartmuseum-5db46b89f4-dv7tj 1/1 Running 1 (31s ago) 17d
registry-system registry-docker-registry-55666698c5-jkn7p 1/1 Running 1 (31s ago) 17d
执行 push/pull 验证
push 镜像
[root@g-master-all ~]# podman tag docker.m.daocloud.io/nginx:latest 10.29.14.27/docker.m.daocloud.io/nginx:latest
[root@g-master-all ~]# podman push 10.29.14.27/docker.m.daocloud.io/nginx:latest
Getting image source signatures
Copying blob 943132143199 done |
Copying blob 88ebb510d2fb done |
Copying blob 58045dd06e5b done |
Copying blob 32c977818204 done |
Copying blob f5fe472da253 done |
Copying blob 541cf9cf006d done |
Copying blob b57b5eac2941 done |
Copying config 9bea9f2796 done |
Writing manifest to image destination
[root@g-master-all ~]# podman push 10.29.14.27/docker.m.daocloud.io/nginx:latest
# 换节点 pull 镜像
[root@g-m-10-29-14-196 containers]# podman pull 10.29.14.27/docker.m.daocloud.io/nginx:latest --tls-verify=false
Trying to pull 10.29.14.27/docker.m.daocloud.io/nginx:latest...
Getting image source signatures
Copying blob b24790593a5b done |
Copying blob 0569eaf32db2 done |
Copying blob 0aaac86b6acc done |
Copying blob ab698a6d27cf done |
Copying blob ba27271778c3 done |
Copying blob 3bc4473eb8b1 done |
Copying blob 96cab5c185c1 done |
Copying config 9bea9f2796 done |
Writing manifest to image destination
9bea9f2796e236cb18c2b3ad561ff29f655d1001f9ec7247a0bc5e08d25652a1
kubelet 资源预留及限制
systemReserved
system-reserved用于为诸如sshd、udev等系统守护进程记述其资源预留值system-reserved也应该为kernel预留内存,因为目前kernel使用的内存并不记在 Kubernetes 的 Pod 上,也推荐为用户登录会话预留资源(systemd 体系中的user.slice)
kubeReserved
kube-reserved用来给诸如kubelet、containerd、节点问题监测器等 Kubernetes 系统守护进程记述其资源预留值
podPidsLimit
podPidsLimit用来给每个 Pod 中可使用的 PID 个数上限
kubelet-config.yaml
[root@worker-node-1 ~]# cat /etc/kubernetes/kubelet-config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
nodeStatusUpdateFrequency: "10s"
failSwapOn: True
authentication:
anonymous:
enabled: false
webhook:
enabled: True
x509:
clientCAFile: /etc/kubernetes/ssl/ca.crt
systemReserved: # 给系统组件预留、生产计划 4c、8g
cpu: 1000m
memory: 2048Mi
kubeReserved: # 给 kube 组件预留、生产计划 12c、24g
cpu: 1000m
memory: 2048Mi
authorization:
mode: Webhook
staticPodPath: /etc/kubernetes/manifests
cgroupDriver: systemd
containerLogMaxFiles: 5
containerLogMaxSize: 10Mi
maxPods: 115
podPidsLimit: 12000 # 灵雀默认值 10000、为了保证组件及业务的稳定将其 +2000
address: 10.29.26.200
readOnlyPort: 0
healthzPort: 10248
healthzBindAddress: 127.0.0.1
kubeletCgroups: /system.slice/kubelet.service
clusterDomain: cluster.local
protectKernelDefaults: true
rotateCertificates: true
clusterDNS:
- 10.233.0.3
resolvConf: "/etc/resolv.conf"
eventRecordQPS: 5
shutdownGracePeriod: 60s
shutdownGracePeriodCriticalPods: 20s
# 默认值
Capacity:
cpu: 14
ephemeral-storage: 151094724Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28632864Ki
pods: 115
Allocatable:
cpu: 14
ephemeral-storage: 139248897408
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28530464Ki
pods: 115
# 更改后
Capacity:
cpu: 14
ephemeral-storage: 151094724Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28632864Ki
pods: 115
Allocatable:
cpu: 12
ephemeral-storage: 139248897408
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 24336160Ki
pods: 115
LimitRange
pod 资源限额
Pod 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量
namespace - resourceQuotas资源配额
[root@g-master1 ~]# kubectl get resourcequotas -n mawb -o yaml quota-mawb
apiVersion: v1
kind: ResourceQuota
metadata:
creationTimestamp: "2023-11-27T05:16:16Z"
name: quota-mawb
namespace: mawb
resourceVersion: "14278163"
uid: 60ae6d65-5ce6-4f8f-bee2-ec0db19a9785
spec:
hard: # 限制改 ns 下可以使用的资源、cpu、memory 哪个先到就先限制哪个资源
limits.cpu: "1"
limits.memory: "1073741824"
requests.cpu: "1"
requests.memory: "1073741824"
status:
hard:
limits.cpu: "1"
limits.memory: "1073741824"
requests.cpu: "1"
requests.memory: "1073741824"
used: # 当前 ns 下已经使用的资源、这里看 memory 已经到配额,再起新的 pod,会导致启动失败
limits.cpu: 500m
limits.memory: 1Gi
requests.cpu: 500m
requests.memory: 1Gi
pod - rangeLimit 资源限额
[root@g-master1 ~]# kubectl get limitranges -n mawb -o yaml limits-mawb
apiVersion: v1
kind: LimitRange
metadata:
creationTimestamp: "2023-11-27T05:16:16Z"
name: limits-mawb
namespace: mawb
resourceVersion: "14265593"
uid: 233b6dc7-e12a-4f2d-88f2-7c923a5cac7b
spec:
limits:
- default: # 定制默认限制
cpu: "1"
memory: "1073741824"
defaultRequest: # 定义默认请求
cpu: 500m
memory: 524288k
type: Container
示例应用
# deployment 副本数
[root@g-master1 ~]# kubectl get deployments.apps -n mawb
NAME READY UP-TO-DATE AVAILABLE AGE
resources-pod 2/4 0 2 33m
resources:
limits:
cpu: 250m
memory: 512Mi
requests:
cpu: 250m
memory: 512Mi
# pod 列表数
[root@g-master1 ~]# kubectl get pod -n mawb
NAME READY STATUS RESTARTS AGE
resources-pod-6b678fdc9f-957ft 1/1 Running 0 29m
resources-pod-6b678fdc9f-vngq7 1/1 Running 0 29m
# 新的 pod 启动报错、提示新的副本没有内存可用
kubectl describe rs -n mawb resources-pod-5b67cf49cf
Warning FailedCreate 15m replicaset-controller Error creating: pods "resources-pod-5b67cf49cf-6k6r5" is forbidden: exceeded quota: quota-mawb
requested: limits.cpu=1,limits.memory=1073741824,requests.memory=524288k # 需要在请求 512m 内存
used: limits.cpu=500m,limits.memory=1Gi,requests.memory=1Gi # 已用 cpu 500m、memory 1g
limited: limits.cpu=1,limits.memory=1073741824,requests.memory=1073741824 # 限制 cpu 1c、memory 1g
用户可通过 RBAC 进行权限控制,让不同 os 用户管理各自 namespace 下的资源
生成 configfile
#!/bin/bash
# 获取用户输入
read -p "请输入要创建的Namespace名称: " namespace
read -p "请输入要创建的ServiceAccount名称: " sa_name
read -p "请输入要创建的SecretName名称: " secret_name
read -p "请输入要生成的Config文件名称: " config_file_name
read -p "请输入Kubernetes集群API服务器地址: " api_server
# 创建Namespace
kubectl create namespace $namespace
# 创建ServiceAccount
kubectl create serviceaccount $sa_name -n $namespace
# 创建Secret
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: $secret_name
namespace: $namespace
annotations:
kubernetes.io/service-account.name: $sa_name
EOF
# 创建Role
cat <<EOF | kubectl apply -f -
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: $namespace
name: $sa_name-role
rules:
- apiGroups: [""]
resources: ["pods", "services", "configmaps"] # 根据需要修改资源类型
verbs: ["get", "list", "watch", "create", "update", "delete"]
EOF
# 创建RoleBinding
cat <<EOF | kubectl apply -f -
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: $sa_name-binding
namespace: $namespace
subjects:
- kind: ServiceAccount
name: $sa_name
namespace: $namespace
roleRef:
kind: Role
name: $sa_name-role
apiGroup: rbac.authorization.k8s.io
EOF
# 获取ServiceAccount的Token
#secret_name=$(kubectl get serviceaccount $sa_name -n $namespace -o jsonpath='{.secrets[0].name}')
token=$(kubectl get secret $secret_name -n $namespace -o jsonpath='{.data.token}' | base64 --decode)
# 生成Config文件
cat <<EOF > $config_file_name
apiVersion: v1
kind: Config
clusters:
- name: $namespace-cluster
cluster:
server: "https://$api_server:6443"
certificate-authority-data: "$(kubectl config view --raw -o jsonpath='{.clusters[0].cluster.certificate-authority-data}')"
contexts:
- name: $namespace-context
context:
cluster: $namespace-cluster
namespace: $namespace
user: $sa_name
current-context: $namespace-context
users:
- name: $sa_name
user:
token: $token
EOF
echo "RBAC和Config文件创建成功!"
ssh 192.168.1.110 "mkdir -p /home/$namespace/.kube/"
scp $config_file_name root@192.168.1.110:/home/$namespace/.kube/
ssh 192.168.1.110 "chmod 755 /home/$namespace/.kube/$config_file_name && cp /home/$namespace/.kube/$config_file_name /home/$config_file_name/.kube/config"
echo "Configfile远程copy完成,请用普通用户登录centos执行: alias k='kubectl --kubeconfig=.kube/config' 或将其追加到 .bashrc 并 source .bashrc"
使用
root@g-m-10-8-162-12 rbac]# bash gen_rbac.sh
请输入要创建的Namespace名称: mawb
请输入要创建的ServiceAccount名称: mawb
请输入要创建的SecretName名称: mawb
请输入要生成的Config文件名称: mawb
请输入Kubernetes集群API服务器地址: 192.168.1.110
Error from server (AlreadyExists): namespaces "mawb" already exists
error: failed to create serviceaccount: serviceaccounts "mawb" already exists
secret/mawb unchanged
role.rbac.authorization.k8s.io/mawb-role unchanged
rolebinding.rbac.authorization.k8s.io/mawb-binding unchanged
RBAC和Config文件创建成功!
mawb 100% 2629 7.9MB/s 00:00
Configfile远程copy完成,请用普通用户登录centos执行: alias k='kubectl --kubeconfig=.kube/config' 或将其追加到 .bashrc 并 source .bashrc
rbac 和 kubeconfig 汇总篇
配置 rbac
-
定义 clusterrole & clusterrolebinding
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: common-node-clusterrole rules: - apiGroups: - "" resources: - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: common-node-clusterrolebinding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: common-node-clusterrole subjects: - kind: ServiceAccount name: test namespace: test -
shell 脚本交互式生成 kubeconfig 文件
#!/bin/bash # 获取用户输入 read -p "请输入要创建的Namespace名称: " namespace read -p "请输入要创建的ServiceAccount名称: " sa_name read -p "请输入要创建的SecretName名称: " secret_name read -p "请输入要生成的Config文件名称: " config_file_name read -p "请输入Kubernetes集群API服务器地址: " api_server # 创建Namespace kubectl create namespace $namespace # 创建ServiceAccount kubectl create serviceaccount $sa_name -n $namespace # 创建Secret cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Secret type: kubernetes.io/service-account-token metadata: name: $secret_name namespace: $namespace annotations: kubernetes.io/service-account.name: $sa_name EOF # 创建Role cat <<EOF | kubectl apply -f - kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: $namespace name: $sa_name-role rules: - apiGroups: ["*"] resources: ["*"] # 根据需要修改资源类型 verbs: ["get", "list", "watch", "create", "update", "delete"] EOF # 创建RoleBinding cat <<EOF | kubectl apply -f - kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: $sa_name-binding namespace: $namespace subjects: - kind: ServiceAccount name: $sa_name namespace: $namespace roleRef: kind: Role name: $sa_name-role apiGroup: rbac.authorization.k8s.io EOF # 创建 ClusterRole # 仅第一执行脚本时需要,clusterrole 不需要多次创建 #cat <<EOF | kubectl apply -f - #apiVersion: rbac.authorization.k8s.io/v1 #kind: ClusterRole #metadata: # name: common-node-clusterrole #rules: #- apiGroups: # - "" # resources: # - nodes # verbs: # - get # - list # - watch #EOF # 创建Clusterrolebinding,使 ns 有查看 node 权限 cat <<EOF | kubectl apply -f - apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: common-node-clusterrolebinding-$namespace roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: common-node-clusterrole subjects: - kind: ServiceAccount name: $sa_name namespace: $namespace EOF # 获取 ServiceAccount 的 Token #secret_name=$(kubectl get serviceaccount $sa_name -n $namespace -o jsonpath='{.secrets[0].name}') token=$(kubectl get secret $secret_name -n $namespace -o jsonpath='{.data.token}' | base64 --decode) # 生成Config文件 cat <<EOF > $config_file_name apiVersion: v1 kind: Config clusters: - name: $namespace-cluster cluster: server: "https://$api_server:6443" certificate-authority-data: "$(kubectl config view --raw -o jsonpath='{.clusters[0].cluster.certificate-authority-data}')" contexts: - name: $namespace-context context: cluster: $namespace-cluster namespace: $namespace user: $sa_name current-context: $namespace-context users: - name: $sa_name user: token: $token EOF echo "RBAC 和 Config 文件创建成功!" # 这部分按需原则即可,要求免密 ssh 192.168.0.110 "mkdir -p /home/$namespace/.kube/" scp $config_file_name 192.168.0.110:/home/$namespace/.kube/ ssh 192.168.0.110 "chmod 755 /home/$namespace/.kube/$config_file_name && cp /home/$namespace/.kube/$config_file_name /home/$namespace/.kube/config" ssh 192.168.0.110 "cp /opt/scripts/.bashrc /home/$namespace/" echo "KubeConfig 远程 copy 完成,请用普通用户登录 centos 执行: kubectl get pod "
合并多个 kubeconfig 文件
-
kubeconfig
# first kubeconfig file apiVersion: v1 clusters: - cluster: certificate-authority-data: "" server: https://192.168.0.196:6443 name: 196cluster contexts: - context: cluster: 196cluster user: 196cluster name: 196cluster current-context: 196cluster kind: Config preferences: {} users: - name: 196global user: client-certificate-data: "" client-key-data: "" # second kubeconfig file apiVersion: v1 clusters: - cluster: certificate-authority-data: "" server: https://192.168.0.255:6443 name: 255cluster contexts: - context: cluster: 255cluster user: 255cluster name: 255cluster current-context: 255cluster kind: Config preferences: {} users: - name: 255cluster user: client-certificate-data: "" client-key-data: "" -
合并
- 定义 KUBECONFIG 变量,这里过滤掉了 config.swp 文件
# 定义 KUBECONFIG 变量 export KUBECONFIG=$HOME/.kube/config:$(find $HOME/.kube -maxdepth 1 -type f | grep config | grep -v '\.config\.swp' | tr '\n' ':') # 查看 KUBECONFIG 变量值 echo $KUBECONFIG /Users/kingskye/.kube/config:/Users/kingskye/.kube/255-config:/Users/kingskye/.kube/196-config:- 合并
kubectl config view --flatten > .kube/config-new- 结果
mawb:~ kingskye$ kubectl config get-clusters NAME 196cluster 255cluster mawb:~ kingskye$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE * 196cluster 196cluster 196cluster 255cluster 255cluster 255cluster
通过 kubernetes API 配置 rbac 策略
创建 clusterrole
-
接口 POST
https://apiserver_ip:6443/apis/rbac.authorization.k8s.io/v1/clusterrole -
body
{ "apiVersion": "rbac.authorization.k8s.io/v1", "kind": "ClusterRole", "metadata": { "name": "namespace-admin-writer1" }, "rules": [ { "apiGroups": [ "" ], "resources": [ "pods", "services", "configmaps", "secrets", "persistentvolumeclaims", "replicationcontrollers", "serviceaccounts", "endpoints" ], "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ] }, { "apiGroups": [ "apps" ], "resources": [ "deployments", "statefulsets", "daemonsets", "replicasets" ], "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ] }, { "apiGroups": [ "batch" ], "resources": [ "jobs", "cronjobs" ], "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ] }, { "apiGroups": [ "autoscaling" ], "resources": [ "horizontalpodautoscalers" ], "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ] }, { "apiGroups": [ "networking.k8s.io" ], "resources": [ "ingresses", "networkpolicies" ], "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ] } ] } -
response
{ "kind": "ClusterRole", "apiVersion": "rbac.authorization.k8s.io/v1", "metadata": { "name": "namespace-admin-writer1", "uid": "f7cc8507-f93a-4c0f-b24f-9c37744efd18", "resourceVersion": "613595193", "creationTimestamp": "2025-04-16T13:03:41Z", "managedFields": [ { "manager": "PostmanRuntime", "operation": "Update", "apiVersion": "rbac.authorization.k8s.io/v1", "time": "2025-04-16T13:03:41Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:rules": {} } } ] }, "rules": [ { "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ], "apiGroups": [ "" ], "resources": [ "pods", "services", "configmaps", "secrets", "persistentvolumeclaims", "replicationcontrollers", "serviceaccounts", "endpoints" ] }, { "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ], "apiGroups": [ "apps" ], "resources": [ "deployments", "statefulsets", "daemonsets", "replicasets" ] }, { "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ], "apiGroups": [ "batch" ], "resources": [ "jobs", "cronjobs" ] }, { "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ], "apiGroups": [ "autoscaling" ], "resources": [ "horizontalpodautoscalers" ] }, { "verbs": [ "get", "list", "watch", "create", "update", "patch", "delete" ], "apiGroups": [ "networking.k8s.io" ], "resources": [ "ingresses", "networkpolicies" ] } ] }
创建 serviceacconut
-
接口 POST
https://apiserver_ip:6443/api/v1/namespaces/default/serviceaccounts- API 接口中,需要指定 namespace
-
body
{ "apiVersion": "v1", "kind": "ServiceAccount", "metadata": { "name": "namespace-role-admin" } } -
response
{ "kind": "ServiceAccount", "apiVersion": "v1", "metadata": { "name": "namespace-role-admin", "namespace": "default", "uid": "e08d4691-2cb1-41f7-9cd9-bbbf5638302d", "resourceVersion": "607496346", "creationTimestamp": "2025-04-13T14:20:26Z" } }
创建 secret
-
接口 POST
https://apiserver_ip:6443/api/v1/namespaces/default/secrets- API 接口中,需要指定 namespace
-
body
{ "apiVersion": "v1", "kind": "Secret", "metadata": { "generateName": "namespace-role-admin-token-", "annotations": { "kubernetes.io/service-account.name": "namespace-role-admin" } }, "type": "kubernetes.io/service-account-token" } -
response
{ "kind": "Secret", "apiVersion": "v1", "metadata": { "name": "namespace-role-admin-token-kkfsf", "generateName": "namespace-role-admin-token-", "namespace": "default", "uid": "3a47b9f7-2e83-445a-ab01-f951d26d4e8b", "resourceVersion": "607497767", "creationTimestamp": "2025-04-13T14:21:23Z", "annotations": { "kubernetes.io/service-account.name": "namespace-role-admin" }, "managedFields": [ { "manager": "PostmanRuntime", "operation": "Update", "apiVersion": "v1", "time": "2025-04-13T14:21:23Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:metadata": { "f:annotations": { ".": {}, "f:kubernetes.io/service-account.name": {} }, "f:generateName": {} }, "f:type": {} } } ] }, "type": "kubernetes.io/service-account-token" }
创建 rolebinding
-
接口 POST
https://apiserver_ip:6443/apis/rbac.authorization.k8s.io/v1/namespaces/default/rolebindings- API 接口中,需要指定 namespace
-
body
{ "apiVersion": "rbac.authorization.k8s.io/v1", "kind": "RoleBinding", "metadata": { "name": "namespace-admin-writer-binding1" }, "subjects": [ { "kind": "ServiceAccount", "name": "namespace-role-admin", "namespace": "default" } ], "roleRef": { "kind": "ClusterRole", "name": "namespace-admin-writer1", "apiGroup": "rbac.authorization.k8s.io" } -
response
{ "kind": "RoleBinding", "apiVersion": "rbac.authorization.k8s.io/v1", "metadata": { "name": "namespace-admin-writer-binding1", "namespace": "default", "uid": "e43f498e-d1e3-4bcd-9be2-be660766fc43", "resourceVersion": "613604237", "creationTimestamp": "2025-04-16T13:10:01Z", "managedFields": [ { "manager": "PostmanRuntime", "operation": "Update", "apiVersion": "rbac.authorization.k8s.io/v1", "time": "2025-04-16T13:10:01Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:roleRef": {}, "f:subjects": {} } } ] }, "subjects": [ { "kind": "ServiceAccount", "name": "namespace-role-admin", "namespace": "default" } ], "roleRef": { "apiGroup": "rbac.authorization.k8s.io", "kind": "ClusterRole", "name": "namespace-admin-writer1" } }
查看 serviceaccount 对应的 token
-
接口 GET
https://apiserver_ip:6443/api/v1/namespaces/default/secrets/namespace-role-admin-token-kkfsf- API 接口中,需要指定 namespace 和 secret
-
response
{ "kind": "Secret", "apiVersion": "v1", "metadata": { "name": "namespace-role-admin-token-kkfsf", "generateName": "namespace-role-admin-token-", "namespace": "default", "uid": "3a47b9f7-2e83-445a-ab01-f951d26d4e8b", "resourceVersion": "612650164", "creationTimestamp": "2025-04-13T14:21:23Z", "labels": { "kubernetes.io/legacy-token-last-used": "2025-04-16" }, "annotations": { "kubernetes.io/service-account.name": "namespace-role-admin", "kubernetes.io/service-account.uid": "e08d4691-2cb1-41f7-9cd9-bbbf5638302d" }, "managedFields": [ { "manager": "PostmanRuntime", "operation": "Update", "apiVersion": "v1", "time": "2025-04-13T14:21:23Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:metadata": { "f:annotations": { ".": {}, "f:kubernetes.io/service-account.name": {} }, "f:generateName": {} }, "f:type": {} } }, { "manager": "kube-controller-manager", "operation": "Update", "apiVersion": "v1", "time": "2025-04-13T14:21:23Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:data": { ".": {}, "f:ca.crt": {}, "f:namespace": {}, "f:token": {} }, "f:metadata": { "f:annotations": { "f:kubernetes.io/service-account.uid": {} } } } }, { "manager": "kube-apiserver", "operation": "Update", "apiVersion": "v1", "time": "2025-04-16T01:58:16Z", "fieldsType": "FieldsV1", "fieldsV1": { "f:metadata": { "f:labels": { ".": {}, "f:kubernetes.io/legacy-token-last-used": {} } } } } ] }, "data": { "ca.crt": "", "namespace": "ZGVmYXVsdA==", "token": "" }, "type": "kubernetes.io/service-account-token" }
最后使用 token
-
生成 kubeconfig 参考上文
-
tokne 直接裸奔
# 由于 secret 是密文的形式,不能直接拿来使用,需要 base64 -d 解码 token=$(kubectl get secret namespace-role-admin-token-kkfsf -o=jsonpath="{.data.token}" | base64 -d) # 检查是否生效 echo $token # 检查 pod 状态 kubectl get pod --token=$token --server=https://apiserver_ip:6443 --insecure-skip-tls-verify -n kube-system Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:default:namespace-role-admin" cannot list resource "pods" in API group "" in the namespace "kube-system" kubectl get pod --token=$token --server=https://apiserver_ip:6443 --insecure-skip-tls-verify NAME READY STATUS RESTARTS AGE log-cleanup-daemonset-4f4xq 1/1 Running 3 (54d ago) 254d test-ulimit-55d976b7f9-qn4tl 1/1 Running 3 (54d ago) 275d test-ulimit-6c476d88f8-nmxqs 0/1 Pending 0 107d -
如果有一个 token 管理多个 namespace 的需求,
- 直接新建 rolebinding,
- roleRef 使用前面创建的 clusterrole
- subjects 使用前面创建的 serviceaccount 和 secret
以上接口都是使用 postman 验证
-
postman 历史版本下载,新版本必须要登录才能获取大部分功能,离线环境肯本没法用,请自行下载 10 以下的版本
https://www.filehorse.com/download-postman/old-versions/page-5/
NFS-CSI 组件部署
创建 nfs-server
yum install -y nfs-utils
systemctl start nfs-server.service
systemctl enable nfs-server.service
echo "/data/ 10.29.26.0/16(rw,sync,no_subtree_check,no_root_squash)" >> /etc/exports
exportfs
helm 部署 nfs-subdir
helm install nfs-provisioner ./nfs-subdir-external-provisioner \
--set nfs.server=10.29.26.x \ # 这里需要替换为自己的 nfs-server 实例
--set nfs.path=/data/ \ # 这里需要替换为自己的 nfs-server 实例
--set storageClass.name=nfs-provisioner \
--set storageClass.provisionerName=k8s-sigs.io/nfs-provisioner
cat test-claim.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-provisioner
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
kubectl apply -f test-claim.yaml
kubectl get pvc #会立即 bound,如果遇到bound 失败,请检查 node、rpc-statd 服务是否启动
## 报错
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ExternalProvisioning 8s (x3 over 29s) persistentvolume-controller waiting for a volume to be created, either by external provisioner "nfs.csi.k8s.io" or manually created by system administrator
Warning ProvisioningFailed 8s (x2 over 19s) nfs.csi.k8s.io_worker-node-1_52792836-2ebf-421f-97ce-ce1fbfdb1e44 failed to provision volume with StorageClass "nfs-csi": rpc error: code = Internal desc = failed to mount nfs server: rpc error: code = Internal desc = mount failed: exit status 32
Mounting command: mount
Mounting arguments: -t nfs -o nfsvers=3 10.29.26.199:/data /tmp/pvc-70557e32-5d98-4fd6-8cd4-e285a7c4a279
Output: /usr/sbin/start-statd: 10: cannot create /run/rpc.statd.lock: Read-only file system
mount.nfs: rpc.statd is not running but is required for remote locking.
mount.nfs: Either use '-o nolock' to keep locks local, or start statd.
Normal Provisioning 6s (x3 over 29s) nfs.csi.k8s.io_worker-node-1_52792836-2ebf-421f-97ce-ce1fbfdb1e44 External provisioner is provisioning volume for claim "default/test-claim-csi"
[root@controller-node-1 ~]# systemctl start rpc-statd && systemctl enable rpc-statd
[root@controller-node-1 ~]# systemctl status rpc-statd
● rpc-statd.service - NFS status monitor for NFSv2/3 locking.
Loaded: loaded (/usr/lib/systemd/system/rpc-statd.service; static; vendor preset: disabled)
Active: active (running) since Thu 2024-05-09 14:41:35 CST; 2h 15min ago
Main PID: 1110879 (rpc.statd)
Tasks: 1
Memory: 852.0K
CGroup: /system.slice/rpc-statd.service
└─1110879 /usr/sbin/rpc.statd
May 09 14:41:35 controller-node-1 systemd[1]: Starting NFS status monitor for NFSv2/3 locking....
May 09 14:41:35 controller-node-1 rpc.statd[1110879]: Version 1.3.0 starting
May 09 14:41:35 controller-node-1 rpc.statd[1110879]: Flags: TI-RPC
May 09 14:41:35 controller-node-1 rpc.statd[1110879]: Initializing NSM state
May 09 14:41:35 controller-node-1 systemd[1]: Started NFS status monitor for NFSv2/3 locking..
[root@controller-node-1 ~]#
helm 部署 nfs-csi
# add repo
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
# install
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --version v4.7.0 --set image.nfs.repository=k8s.m.daocloud.io/sig-storage/nfsplugin --set image.csiProvisioner.repository=k8s.m.daocloud.io/sig-storage/csi-provisioner --set image.livenessProbe.repository=k8s.m.daocloud.io/sig-storage/livenessprobe --set image.nodeDriverRegistrar.repository=k8s.m.daocloud.io/sig-storage/csi-node-driver-registrar --set image.csiSnapshotter.repository=k8s.m.daocloud.io/sig-storage/csi-snapshotter --set image.externalSnapshotter.repository=k8s.m.daocloud.io/sig-storage/snapshot-controller --set externalSnapshotter.enabled=true
# create storageclass for nfs-server
[root@controller-node-1 ~]# cat sc.yaml # 当有多个 nfs-server 时,创建新的 sc 并指定ip:path 即可,这点比 nfs-subdir 方便不少
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
provisioner: nfs.csi.k8s.io
parameters:
server: 10.29.26.199
share: /data
# csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume
csi.storage.k8s.io/provisioner-secret-name: "mount-options"
csi.storage.k8s.io/provisioner-secret-namespace: "default"
reclaimPolicy: Delete
volumeBindingMode: Immediate
mountOptions:
- nfsvers=3
检查及验证快照功能
# get sc
[root@controller-node-1 ~]# kubectl get csidrivers.storage.k8s.io
NAME ATTACHREQUIRED PODINFOONMOUNT STORAGECAPACITY TOKENREQUESTS REQUIRESREPUBLISH MODES AGE
nfs.csi.k8s.io false false false <unset> false Persistent 25m
# create snapshotclass
[root@controller-node-1 ~]# cat nfs-csi-snapshot.yaml
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-nfs-snapclass
driver: nfs.csi.k8s.io
deletionPolicy: Delete
# create snapshot
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-nfs-snapshot
spec:
volumeSnapshotClassName: csi-nfs-snapclass
source:
persistentVolumeClaimName: test-claim-csi
[root@controller-node-1 ~]# kubectl apply -f nfs-csi-snapshot-pvc-test-claim-csi.yaml
volumesnapshot.snapshot.storage.k8s.io/test-nfs-snapshot created
# check snapshot status
[root@controller-node-1 ~]# kubectl get volumesnapshot
NAME READYTOUSE SOURCEPVC SOURCESNAPSHOTCONTENT RESTORESIZE SNAPSHOTCLASS SNAPSHOTCONTENT CREATIONTIME AGE
test-nfs-snapshot true test-claim-csi 105 csi-nfs-snapclass snapcontent-462e5866-3c10-4201-8c5b-c3e5fd68af3b 13s 13s
# check nfs-server data
[root@controller-node-1 ~]# cd /data/
[root@controller-node-1 data]# ll
total 0
drwxrwxrwx. 2 root root 21 May 9 15:30 default-test-claim-pvc-372c6ee4-c2fa-41e5-9e7d-a7b18e7c6efc
drwxrwxrwx. 2 root root 6 May 9 15:34 default-test-claim2-pvc-88fe2a10-60b6-47c6-b77a-b07cbe7e001e
drwxr-xr-x. 2 root root 6 May 9 17:01 pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739
drwxr-xr-x. 2 root root 61 May 9 17:09 snapshot-462e5866-3c10-4201-8c5b-c3e5fd68af3b
[root@controller-node-1 data]# ls pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739/
[root@controller-node-1 data]# ls snapshot-462e5866-3c10-4201-8c5b-c3e5fd68af3b/
pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739.tar.gz
对比及建议
- k8 版本较老建议使用 nfs-subdir(使用 deployment 来对接 nfs-server)
- 新建的 k8-cluster 可以尝试使用 nfs-csi(使用 sc 对接 nfs-server,灵活不少)组件,功能相对来说丰富不少
参考文档
API 接口文档
请求
-
-
op: 支持 add、replace、remove 多种场景
- 使用操作列表(op、path、value)来精确定义需要修改的 JSON 文档部分
curl -X PATCH -H 'Content-Type: application/json-patch+json' --data '[{"op": "replace","path": "/spec/template/spec/containers/0/args","value": ["-c", "./nginx.conf", "-g", "daemon off;"]}]' -
merge:以原对象为基础,提供一个结构化的 JSON 数据片段进行合并更新、无法删除字段,除非更改 value 为 null
-
strategic-merge-patch:merge 基础上支持更复杂的操作,特别适用于更新 array 类型字段(如 containers 列表)k8s 特有
curl -X PATCH -H 'Content-Type: application/strategic-merge-patch+json' --data ' {"spec":{"template":{"spec":{"containers":[{"name":"nginx","image":"nginx:1.16"}]}}}}' \ 'http://127.0.0.1:8001/apis/apps/v1/namespaces/default/deployments/deployment-example' -
kubectl patch 示例
kubectl patch deployment deployment-example --type strategic -p \ '{"spec":{"template":{"spec":{"containers":[{"name":"nginx","image":"nginx:1.16"}]}}}}' -
区别
- op:“path”: “/spec/template/spec/containers/0/args” 需要定位到 containers 列表中的字典,然后对其 key:value 键值对进行更新
- merge:{“spec”:{“template”:{“spec”:{“containers”:[{“name”:“nginx”,“image”:“nginx:1.16”}]}}}} 需要也是类似,但是需要加上 name么,否则会报错,在我的环境 name 是这个 dict 中的第一个键值对,后续留意下这点
-
github
LeaderWorkerSet API
LeaderWorkerSet API 是什么?
-
简称 LWS
-
是一个 API
-
旨在解决 AI/ML 推理工作负载的常见部署模式,尤其是多机多卡的推理工作负载,其中 LLM 将被分片并在多个节点上的多个设备上运行

场景
-
用于大模型的服务推理
-
利用多个主机的 GPU 卡完成模型部署和推理
安装 lws
## install
[root@tf1-dameile-master01 ~]# VERSION=v0.6.0
[root@tf1-dameile-master01 ~]# kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/download/$VERSION/manifests.yaml
namespace/lws-system serverside-applied
customresourcedefinition.apiextensions.k8s.io/leaderworkersets.leaderworkerset.x-k8s.io serverside-applied
serviceaccount/lws-controller-manager serverside-applied
role.rbac.authorization.k8s.io/lws-leader-election-role serverside-applied
clusterrole.rbac.authorization.k8s.io/lws-manager-role serverside-applied
clusterrole.rbac.authorization.k8s.io/lws-metrics-reader serverside-applied
clusterrole.rbac.authorization.k8s.io/lws-proxy-role serverside-applied
rolebinding.rbac.authorization.k8s.io/lws-leader-election-rolebinding serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/lws-manager-rolebinding serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/lws-metrics-reader-rolebinding serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/lws-proxy-rolebinding serverside-applied
configmap/lws-manager-config serverside-applied
secret/lws-webhook-server-cert serverside-applied
service/lws-controller-manager-metrics-service serverside-applied
service/lws-webhook-service serverside-applied
deployment.apps/lws-controller-manager serverside-applied
mutatingwebhookconfiguration.admissionregistration.k8s.io/lws-mutating-webhook-configuration serverside-applied
validatingwebhookconfiguration.admissionregistration.k8s.io/lws-validating-webhook-configuration serverside-applied
[root@tf1-dameile-master01 ~]#
## check
[root@tf1-dameile-master01 ~]# kubectl get deployments.apps -n lws-system
NAME READY UP-TO-DATE AVAILABLE AGE
lws-controller-manager 0/2 2 0 95s
[root@tf1-dameile-master01 ~]# kubectl get deployments.apps -n lws-system lws-controller-manager -o yaml | grep image
image: registry.k8s.io/lws/lws:v0.6.0
imagePullPolicy: IfNotPresent
## modify
registry.k8s.io/lws/lws:v0.6.0 替换为 k8s.m.daocloud.io/lws/lws:v0.6.0 # k8s.m.daocloud.io 是 daocloud 加速器
lws 滚动更新
更新策略
MaxUnavailable:表示在更新过程中允许多少个副本不可用,不可用数量基于 spec.replicas。默认为 1MaxSurge:表示更新时可以部署多少个额外副本。默认为 0- maxSurge 和 maxUnavailable 不能同时为零
滚动更新 demo
- 示例 yaml
spec:
rolloutStrategy:
type: RollingUpdate
rollingUpdateConfiguration:
maxUnavailable: 2
maxSurge: 2
replicas: 4
- 更新过程如下:
- ✅ 副本已更新
- ❎ 副本尚未更新
- ⏳ 副本正在滚动更新
| 分区 | 副本 | R-0 | R-1 | R-2 | R-3 | R-4 | R-5 | 说明 | |
|---|---|---|---|---|---|---|---|---|---|
| 第一阶段 | 0 | 4 | ✅ | ✅ | ✅ | ✅ | 滚动更新之前 | ||
| 第 2 阶段 | 4 | 6 | ❎ | ❎ | ❎ | ❎ | ⏳ | ⏳ | 滚动更新已开始 |
| 第 3 阶段 | 2 | 6 | ❎ | ❎ | ⏳ | ⏳ | ⏳ | ⏳ | 分区从 4 变为 2 |
| 第四阶段 | 2 | 6 | ❎ | ❎ | ⏳ | ⏳ | ✅ | ⏳ | 由于最后一个 Replica 尚未准备好,因此 Partition 不会发生改变 |
| 第五阶段 | 0 | 6 | ⏳ | ⏳ | ⏳ | ⏳ | ✅ | ✅ | 分区从 2 变为 0 |
| 第六阶段 | 0 | 6 | ⏳ | ⏳ | ⏳ | ✅ | ✅ | ✅ | |
| 第七阶段 | 0 | 5 | ⏳ | ✅ | ⏳ | ✅ | ✅ | 回收副本以容纳尚未准备好的副本 | |
| 第八阶段 | 0 | 4 | ✅ | ⏳ | ✅ | ✅ | 发布另一个副本 | ||
| 第九阶段 | 0 | 4 | ✅ | ✅ | ✅ | ✅ | 滚动更新已完成 |
lws 标签、注解、环境变量
Labels
| 键 | 描述 | 例子 | 适用于 |
|---|---|---|---|
leaderworkerset.sigs.k8s.io/name | 这些资源所属的 LeaderWorkerSet 对象的名称。 | leaderworkerset-多模板 | Pod、StatefulSet、服务 |
leaderworkerset.sigs.k8s.io/template-revision-hash | 用于跟踪与 LeaderWorkerSet 对象匹配的控制器修订的哈希。 | 5c5fcdfb44 | Pod、StatefulSet |
leaderworkerset.sigs.k8s.io/group-index | 它所属的组。 | 0 | Pod、StatefulSet(仅工作线程) |
leaderworkerset.sigs.k8s.io/group-key | 标识该组的唯一键。 | 689ce1b5…b07 | Pod、StatefulSet(仅工作线程) |
leaderworkerset.sigs.k8s.io/worker-index | 组内 pod 的索引或标识。 | 0 | 荚 |
leaderworkerset.sigs.k8s.io/subgroup-index | 跟踪该 pod 所属的子分组。 | 0 | Pod(仅当设置了 SubGroup 时) |
leaderworkerset.sigs.k8s.io/subgroup-key | 属于同一子组的 Pod 将具有相同的唯一哈希值。 | 92904e74…801 | Pod(仅当设置了 SubGroup 时) |
Annotations
| 键 | 描述 | 例子 | 适用于 |
|---|---|---|---|
leaderworkerset.sigs.k8s.io/size | 每个组中的 pod 总数。 | 4 | 荚 |
leaderworkerset.sigs.k8s.io/replicas | 副本数:领导-工作组的数量。 | 3 | StatefulSet (唯一领导者) |
leaderworkerset.sigs.k8s.io/leader-name | 领导者荚的名称。 | leaderworkerset-多模板-0 | Pod(仅工作进程) |
leaderworkerset.sigs.k8s.io/exclusive-topology | 指定独占 1:1 调度的拓扑。 | cloud.google.com/gke-nodepool | LeaderWorkerSet、Pod(仅当使用 exclusive-topology 时) |
leaderworkerset.sigs.k8s.io/subdomainPolicy | 确定将注入哪种类型的域。 | 每个副本唯一 | Pod(仅当 leader 和 subdomainPolicy 设置为 UniquePerReplica 时) |
leaderworkerset.sigs.k8s.io/subgroup-size | 每个子组的 pod 数量。 | 2 | Pod(仅当设置了 SubGroup 时) |
leaderworkerset.sigs.k8s.io/subgroup-exclusive-topology | 指定子组内的独占 1:1 调度的拓扑。 | 拓扑键 | LeaderWorkerSet、Pod(仅当设置了 SubGroup 并使用了 subgroup-exclusive-topology 时) |
Env
| 键 | 描述 | 例子 | 适用于 |
|---|---|---|---|
LWS_LEADER_ADDRESS | 通过无头服务获取领导者的地址。 | leaderworkerset-多模板-0.leaderworkerset-多模板.默认 | 荚 |
LWS_GROUP_SIZE | 跟踪 LWS 组的大小。 | 4 | 荚 |
LWS_WORKER_INDEX | 组内 pod 的索引或标识。 | 2 | 荚 |
TPU_WORKER_HOSTNAMES | 仅位于同一子组中的 TPU 工作者的主机名。 | 测试样本-1-5.默认,测试样本-1-6.默认,测试样本-1-7.默认,测试样本-1-8.默认 | Pod(仅当启用 TPU 时) |
TPU_WORKER_ID | TPU 工人的 ID。 | 0 | Pod(仅当启用 TPU 时) |
TPU_NAME | TPU 的名称。 | 测试样本-1 | Pod(仅当启用 TPU 时) |
- 更多环境变量,请参考 Kubernetes Downward API
更多示例配置
-
multiple-nodes
LWS 设计文档
Traefik 由 F5 统一卸载 TLS 后改为 HTTP 的配置说明
1. 问题背景
当前 Kubernetes 集群使用 Traefik 作为入口控制器,原 Traefik 同时监听 HTTP 和 HTTPS,并配置了以下能力:
webEntryPoint 监听80;websecureEntryPoint 监听443;- 所有进入
web:80的请求强制跳转到websecure:443; - Traefik 在
websecure上完成 TLS 终止; - Traefik Dashboard 通过
IngressRoute对外提供访问。
后续调整为由 F5 统一管理和卸载 HTTPS 证书,F5 解密请求后,通过 HTTP 将流量转发到 Traefik。因此,Traefik 不再需要监听或处理 HTTPS,也不能继续执行 HTTP 到 HTTPS 的重定向。
目标请求链路如下:
客户端 HTTPS:443
↓
F5:TLS 终止、证书管理
↓ HTTP:80
Traefik:HTTP 路由
↓
Kubernetes Service / Pod
对客户端来说,业务地址仍然是
https://;只有 F5 到 Traefik 这一段改为 HTTP。
2. 原配置存在的问题
Traefik 当前包含以下启动参数:
- --entryPoints.web.address=:80/tcp
- --entryPoints.websecure.address=:443/tcp
- --entryPoints.web.http.redirections.entryPoint.to=:443
- --entryPoints.web.http.redirections.entryPoint.scheme=https
- --entryPoints.web.http.redirections.entryPoint.permanent=true
- --entryPoints.websecure.http.tls=true
其中:
web.http.redirections会把所有进入 Traefik 80 端口的请求重定向到 HTTPS;websecure.http.tls=true表示 Traefik 在 443 入口执行 TLS 终止;- F5 已经完成 TLS 终止后,如果仍将请求发送到 Traefik 80,Traefik又会把请求重定向回 443;
- 如果
IngressRoute只绑定web,请求重定向到websecure后无法匹配对应 Router,最终可能返回 Traefik 404; - 如果 F5 的后端 Pool 只配置了 Traefik 80 端口,还可能出现重定向循环或访问异常。
因此,将证书迁移到 F5 后,需要同时取消 Traefik 的 HTTPS 重定向和 TLS 配置。
3. Traefik 启动参数修改
3.1 必须删除的参数
删除 HTTP 到 HTTPS 的重定向配置:
- --entryPoints.web.http.redirections.entryPoint.to=:443
- --entryPoints.web.http.redirections.entryPoint.scheme=https
- --entryPoints.web.http.redirections.entryPoint.permanent=true
删除 Traefik TLS 终止配置:
- --entryPoints.websecure.http.tls=true
如果确定 Traefik 以后完全不再提供 443 入口,还可以删除:
- --entryPoints.websecure.address=:443/tcp
3.2 修改后的关键启动参数
containers:
- name: traefik
args:
- --entryPoints.metrics.address=:9100/tcp
- --entryPoints.traefik.address=:8080/tcp
- --entryPoints.web.address=:80/tcp
- --api.dashboard=true
- --ping=true
- --metrics.prometheus=true
- --metrics.prometheus.entrypoint=metrics
- --providers.kubernetescrd
- --providers.kubernetescrd.allowCrossNamespace=true
- --providers.kubernetescrd.allowEmptyServices=true
- --providers.kubernetesingress
- --providers.kubernetesingress.allowEmptyServices=true
- --providers.kubernetesingress.ingressendpoint.publishedservice=traefik/traefik
- --providers.kubernetesgateway
- --providers.kubernetesgateway.statusaddress.service.name=traefik
- --providers.kubernetesgateway.statusaddress.service.namespace=traefik
- --log.level=INFO
- --accesslog=true
- --accesslog.fields.defaultmode=keep
- --accesslog.fields.headers.defaultmode=drop
4. Dashboard IngressRoute 修改
Dashboard 应绑定到 HTTP web EntryPoint,并且不能再配置 tls。
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: traefik-dashboard
namespace: traefik
spec:
entryPoints:
- web
routes:
- kind: Rule
match: >-
Host(`traefik-uat2.dominos.com.cn`) &&
(PathPrefix(`/dashboard`) || PathPrefix(`/api`))
middlewares:
- name: dashboard-auth
services:
- kind: TraefikService
name: api@internal
不要保留以下内容:
tls: {}
客户端仍通过以下 HTTPS 地址访问:
https://traefik-uat2.dominos.com.cn/dashboard/
但 F5 转发到 Traefik 的请求为:
http://<Traefik地址>:80/dashboard/
Dashboard 404 注意事项
Traefik Dashboard 的标准访问路径为:
/dashboard/
需要特别注意:
- 不能只访问域名根路径
/,否则api@internal可能返回 404; /dashboard/最后的/不要省略;- 路由规则需要同时放行
/dashboard和/api; - 未携带 BasicAuth 认证信息时返回
401 Unauthorized,说明路由和认证中间件已经正常生效,并不是故障。
5. Helm values.yaml 修改
当前 Traefik 资源由 Helm 管理,直接修改 Deployment 或 Helm 创建的 IngressRoute,可能在下次 helm upgrade 时被覆盖,因此应优先修改原始 values.yaml。
5.1 修改前备份
helm get values traefik -n traefik -o yaml \
> traefik-values-before-http.yaml
同时保存当前完整清单:
helm get manifest traefik -n traefik \
> traefik-manifest-before-http.yaml
5.2 关闭 web 重定向和 websecure TLS
从原 values.yaml 中删除类似配置:
ports:
web:
redirections:
entryPoint:
to: websecure
scheme: https
permanent: true
将端口配置调整为:
ports:
web:
expose:
default: true
exposedPort: 80
protocol: TCP
websecure:
expose:
default: false
tls:
enabled: false
说明:
web继续提供 HTTP 80 服务;websecure.expose.default=false表示 Service 不再暴露 443;websecure.tls.enabled=false表示不在该 EntryPoint 上启用 TLS;- 不同 Chart 小版本的字段可能略有差异,升级前应使用
helm show values与当前 values 对比确认; - 如果原重定向参数来自
additionalArguments,还需要从additionalArguments中删除对应参数。
5.3 Dashboard Helm 配置
ingressRoute:
dashboard:
enabled: true
entryPoints:
- web
matchRule: >-
Host(`traefik-uat2.dominos.com.cn`) &&
(PathPrefix(`/dashboard`) || PathPrefix(`/api`))
middlewares:
- name: dashboard-auth
namespace: traefik
tls: null
如果 Chart 对 tls: null 的处理不符合预期,可以直接从 Dashboard 配置中删除整个 tls 字段,最终以生成的 IngressRoute 中不存在 spec.tls 为准。
5.4 执行 Helm 升级
helm upgrade traefik traefik/traefik \
-n traefik \
--version 37.3.0 \
-f values.yaml
不建议在未确认历史 values 的情况下直接使用
--reuse-values,否则旧的 HTTPS 重定向配置可能被继续保留。
6. Kubernetes Service 检查
检查 Traefik Service 暴露的端口:
kubectl -n traefik get svc traefik -o yaml
目标状态:
- 对 F5 提供 HTTP 80 或对应的 HTTP NodePort;
- 不再需要对 F5 提供 HTTPS 443;
- F5 Pool Member 指向 Traefik HTTP 端口,而不是 Traefik 443。
如果使用 NodePort,可以执行:
kubectl -n traefik get svc traefik \
-o jsonpath='{range .spec.ports[*]}{.name}{"\t"}{.port}{"\t"}{.nodePort}{"\n"}{end}'
7. F5 侧配置要求
F5 建议按照以下方式配置:
| 配置项 | 建议配置 |
|---|---|
| Virtual Server | 监听客户端 HTTPS 443 |
| Client SSL Profile | 配置域名证书并执行 TLS 终止 |
| Pool Member | 指向 Traefik HTTP 80 或 HTTP NodePort |
| 后端协议 | HTTP |
| Host 请求头 | 保留客户端原始 Host |
| X-Forwarded-Proto | 设置为 https |
| X-Forwarded-For | 保留或追加客户端真实 IP |
| 健康检查 | 使用 Traefik HTTP 健康检查地址 |
F5 应向 Traefik 传递:
X-Forwarded-Proto: https
X-Forwarded-For: <客户端IP>
Host: <原始访问域名>
X-Forwarded-Proto: https 非常重要。虽然 F5 到 Traefik 使用 HTTP,但客户端实际使用的是 HTTPS。缺少该请求头可能导致:
- 后端应用生成
http://回调地址; - OAuth、SSO 登录回调地址错误;
- Cookie 的
Secure属性判断异常; - 应用产生 HTTP/HTTPS 重定向循环;
- 日志中记录的原始协议不准确。
8. Traefik 信任 F5 转发头
建议 Traefik 只信任 F5 的地址,不要无条件信任所有客户端传入的 X-Forwarded-* 请求头。
启动参数示例:
- --entryPoints.web.forwardedHeaders.trustedIPs=<F5地址或网段>
例如:
- --entryPoints.web.forwardedHeaders.trustedIPs=10.10.10.10/32
如果 F5 使用 SNAT Automap,应填写 F5 访问 Traefik 时实际使用的 SNAT 地址或网段。
不建议直接配置:
- --entryPoints.web.forwardedHeaders.insecure=true
因为该配置会信任任意来源传入的转发请求头,存在伪造客户端 IP 或原始协议的风险。
9. 其他业务路由检查
除了 Dashboard,还需要检查集群内其他路由是否仍然依赖 websecure 或 TLS。
9.1 检查 IngressRoute
kubectl get ingressroute -A -o json |
jq -r '
.items[] |
select(
(.spec.tls != null) or
((.spec.entryPoints // []) | index("websecure"))
) |
[.metadata.namespace, .metadata.name,
((.spec.entryPoints // []) | join(",")),
(if .spec.tls == null then "no-tls" else "tls" end)] |
@tsv'
需要逐个调整为:
spec:
entryPoints:
- web
并删除:
spec:
tls: {}
9.2 检查标准 Ingress
kubectl get ingress -A -o json |
jq -r '
.items[] |
select(
((.spec.tls // []) | length > 0) or
(.metadata.annotations["traefik.ingress.kubernetes.io/router.tls"] == "true") or
(.metadata.annotations["traefik.ingress.kubernetes.io/router.entrypoints"] // "" | contains("websecure"))
) |
[.metadata.namespace, .metadata.name] |
@tsv'
需要根据实际情况:
- 删除
spec.tls; - 删除
traefik.ingress.kubernetes.io/router.tls: "true"; - 将 Router EntryPoint 修改为
web。
9.3 检查 HTTPS 重定向 Middleware
kubectl get middleware -A -o json |
jq -r '
.items[] |
select(.spec.redirectScheme != null) |
[.metadata.namespace, .metadata.name,
(.spec.redirectScheme.scheme // "")] |
@tsv'
如果 Middleware 仍然将请求重定向到 HTTPS,需要确认它是否已经没有必要。通常在 F5 统一负责 HTTPS 的场景下,外部 HTTP 到 HTTPS 的跳转也应由 F5 完成,而不是由 Traefik完成。
10. 修改后验证
10.1 检查 Traefik 启动参数
kubectl -n traefik get deploy traefik -o json |
jq -r '
.spec.template.spec.containers[] |
select(.name == "traefik") |
.args[]' |
grep -Ei 'websecure|redirection|tls'
不应该再出现:
entryPoints.web.http.redirections
entryPoints.websecure.http.tls=true
如果 Helm 仍保留了一个未暴露、未启用 TLS 的 websecure.address,不会影响 web 的 HTTP 请求;如果要求彻底关闭该监听端口,再根据当前 Chart 的端口模板将整个 websecure EntryPoint 删除。
10.2 集群内部绕过 F5 验证
curl -I \
-H 'Host: traefik-uat2.dominos.com.cn' \
http://traefik.traefik.svc.cluster.local/dashboard/
预期结果:
- 返回
401 Unauthorized:路由已匹配,BasicAuth 正常生效; - 携带正确认证信息后返回
200或正常页面内容; - 不应再返回指向
https://...:443的 301/308 重定向。
携带 BasicAuth 验证:
curl -I \
-u '<用户名>:<密码>' \
-H 'Host: traefik-uat2.dominos.com.cn' \
http://traefik.traefik.svc.cluster.local/dashboard/
10.3 通过 F5 验证
curl -kI https://traefik-uat2.dominos.com.cn/dashboard/
判断方式:
| 返回结果 | 含义 |
|---|---|
401 Unauthorized | 已命中 Traefik Dashboard 和认证中间件 |
200 OK | 访问正常,或已携带正确认证信息 |
301/308 到 Traefik 443 | Traefik 仍残留 HTTPS 重定向配置 |
404 Not Found | Host、路径或 EntryPoint 没有匹配 |
502/503 | F5 Pool、Traefik Service、NodePort 或后端健康状态异常 |
10.4 检查 Traefik 日志
kubectl -n traefik logs deploy/traefik \
--since=10m |
grep 'traefik-uat2.dominos.com.cn'
重点确认:
- 请求是否进入
webEntryPoint; - Host 是否保持为原始域名;
- 是否仍有 HTTPS 重定向;
- 返回状态码是 401、200、404 还是 5xx。
11. 推荐实施顺序
备份 Helm values 和 manifest
↓
确认 F5 已配置证书和 HTTPS Virtual Server
↓
确认 F5 Pool 指向 Traefik HTTP 端口
↓
取消 Traefik 的 HTTP→HTTPS 重定向
↓
关闭 websecure TLS 和 443 暴露
↓
IngressRoute/Ingress 统一切换到 web
↓
集群内部验证 HTTP 路由
↓
通过 F5 验证客户端 HTTPS
↓
观察访问日志和业务回调
建议先在 UAT 环境验证,确认业务登录、回调、Cookie、真实客户端 IP 和访问日志正常后,再应用到生产环境。
12. 回滚方案
如果修改后出现异常,可使用修改前备份的 values 回滚:
helm upgrade traefik traefik/traefik \
-n traefik \
--version 37.3.0 \
-f traefik-values-before-http.yaml
也可以查看 Helm 历史版本:
helm history traefik -n traefik
回滚到指定 Revision:
helm rollback traefik <REVISION> -n traefik
回滚后需要同步确认:
- Traefik 是否重新暴露 443;
- TLS 配置和证书是否恢复;
- F5 Pool 的后端协议是否与 Traefik 当前配置一致;
- 避免 F5 与 Traefik 同时进行相互冲突的重定向。
13. 最终结论
当 HTTPS 证书统一放在 F5 上时,Traefik 应作为 F5 后端的纯 HTTP 七层路由使用。改造的核心是:
- 删除 Traefik
web到websecure的强制重定向; - 关闭 Traefik
websecure的 TLS 和 443 对外暴露; - 所有
IngressRoute和Ingress统一绑定 HTTPwebEntryPoint; - F5 监听客户端 443,并将解密后的 HTTP 请求转发到 Traefik 80;
- F5 保留原始 Host,并正确传递
X-Forwarded-Proto和X-Forwarded-For; - Traefik 只信任 F5 的转发地址,避免转发请求头被伪造。
完成以上调整后,客户端继续通过 HTTPS 访问,证书由 F5 统一管理,Traefik 内部不再处理 TLS。
k3s 架构
架构
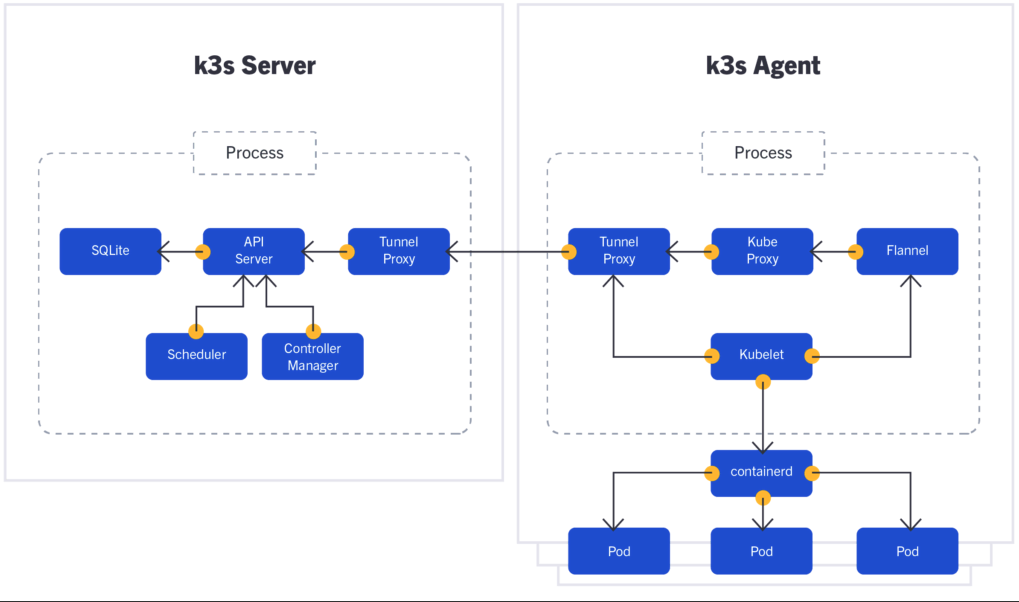
组件
角色
- server
- agent
两者的通信是通过 tunnel proxy 来完成,它们有大量的通信,均会通过 tunnel proxy 设置对应连接和端口
组件(所有组件一个进程一起运行,90s一个单节点集群)
- kubelet
- api-server
- controller-manager
- scheduler
- kube-proxy
通过 tunnel proxy 来完成和 api-server 的连接,tunnel 模式创建单向连接跟 api 进行通信,一旦建立链接便会创建双向连接,通过使用单个端口进行通信来确保连接安全(长连接)
- sqlite
- 单节点 server,推荐使用
- 高可用模式下,推荐使用其它外部存储
- flannel
flannel 与 kubelet 建立连接,而 kubelet 又与 containerd 通信,并最终由 containerd 来跟 集群中的 pod 建立连接
- containerd/runc(支持 docker,部署集群时支持 args 选择)
- traefik
- coredns
- local-path-provisioner
- helm-controller
差异
- k3s:k8s 遗留、非默认功能、以及处于 alpha 的功能均被删除(Rancher 表示删除 30 亿行 code)
优势
- 体积小、简化安装,一个单节点集群,只需 90s 即可启动完成。多节点集群需要约3条名称来完成集群的创建。(对硬件设备的要求低,适合物联网、边缘计算场景下的客户)
- 支持 helm 和 manifst 清单,只需将 yaml 放入对应目录,k3s 启动时会扫描 helm 介质和 ymal 目录来完成集群/应用的启动(边缘计算硬需求)
- 集群节点的新增和删除用一条命令完成
- 简单的集群配置
兼容矩阵
| k3s | 系统 | 芯片 |
|---|---|---|
| k3s-1.26.1-k3s1 、k3s-1.25.1-k3s1 | rhel 8.4~8.7、rocky linux 8.4~8.7Ubuntu 、18.04\20.04\22.04 | x86_64、arm64/aarch64、armv7、s390 |
| k3s-1.24.10-k3s1 | rhel 8.4~8.7、rocky linux 8.4~8.7、Ubuntu 18.04\20.04\22.04、centos7.9 | x86_64、arm64/aarch64、armv7、s390 |
安装参数搜集
单节点
- –write-kubeconfig-mode 6444 # 默认 kubeconfig 文件仅 root 可读,其它用户可读需要加上该参数
多节点
- K3S_URL=https://127.0.0.1:6443 # 节点接入时需要提供集群的入口地址
- K3S_TOKEN=$node-toekn # 节点接入时需要提供集群的接入 token 信息
客户场景
封装小,硬件要求小、在树莓派上都可以轻松运行,而且 k3s 对于制作单个应用程序的集群非常高效
- 边缘计算
- 嵌入式系统
- 物联网
参考文档
k3s 离线安装篇
1. containerd runc cni 安装(该章节忽略,k3s 自带 containerd)
1.1 containerd
- 解压并将二进制文件放入 /usr/local/bin/ 目录下
tar Cxzvf /usr/local containerd-1.7.0-linux-arm64.tar.gz
bin/
bin/containerd-shim-runc-v2
bin/containerd-shim
bin/ctr
bin/containerd-shim-runc-v1
bin/containerd
bin/containerd-stress
- 配置systemd
vi /usr/lib/systemd/system/containerd.service
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target
[Service]
#uncomment to enable the experimental sbservice (sandboxed) version of containerd/cri integration
#Environment="ENABLE_CRI_SANDBOXES=sandboxed"
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=infinity
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
- 启动
systemctl daemon-reload
systemctl enable --now containerd
- 生成默认配置文件
mkdir -p /etc/containerd/
containerd config default >> /etc/containerd/config.toml
1.2 runc
install -m 755 runc.arm64 /usr/local/sbin/runc
1.3 cni
mkdir -p /opt/cni/bin
tar Cxzvf /opt/cni/bin cni-plugins-linux-arm64-v1.2.0.tgz
./
./macvlan
./static
./vlan
./portmap
./host-local
./vrf
./bridge
./tuning
./firewall
./host-device
./sbr
./loopback
./dhcp
./ptp
./ipvlan
./bandwidth
2. k3s 安装
2.1 准备介质
- 手动部署镜像(如果是用私有仓库,cri 调整默认仓库地址即可)
mkdir -p /var/lib/rancher/k3s/agent/images/
cp /root/k3s/k3s-airgap-images-arm64.tar /var/lib/rancher/k3s/agent/images/
- k3s 二进制文件
chmod +x k3s-arm64
cp k3s-arm64 /usr/local/bin/k3s
[root@k3s-master k3s]# k3s --version
k3s version v1.26.2+k3s1 (ea094d1d)
go version go1.19.6
2.2 安装 master 节点
- 下载安装脚本
curl https://get.k3s.io/ -o install.sh
chmod +x install.sh
- 跳过下载镜像
INSTALL_K3S_SKIP_DOWNLOAD=true
- 安装
[root@k3s-master k3s]# INSTALL_K3S_SKIP_DOWNLOAD=true ./install.sh
[INFO] Skipping k3s download and verify
[INFO] Skipping installation of SELinux RPM
[INFO] Creating /usr/local/bin/kubectl symlink to k3s
[INFO] Creating /usr/local/bin/crictl symlink to k3s
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, already exists
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
- 检查节点/组件状态
[root@k3s-master k3s]# kubectl get node
NAME STATUS ROLES AGE VERSION
k3s-master Ready control-plane,master 55s v1.26.2+k3s1
[root@k3s-master k3s]# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-5c6b6c5476-tz8jn 1/1 Running 0 48s 10.42.0.4 k3s-master <none> <none>
kube-system local-path-provisioner-5d56847996-n27l6 1/1 Running 0 48s 10.42.0.5 k3s-master <none> <none>
kube-system helm-install-traefik-crd-cnjhj 0/1 Completed 0 49s 10.42.0.3 k3s-master <none> <none>
kube-system metrics-server-7b67f64457-bzgdt 1/1 Running 0 48s 10.42.0.6 k3s-master <none> <none>
kube-system svclb-traefik-569139e2-rgdqr 2/2 Running 0 28s 10.42.0.7 k3s-master <none> <none>
kube-system traefik-56b8c5fb5c-g5ggl 1/1 Running 0 28s 10.42.0.8 k3s-master <none> <none>
kube-system helm-install-traefik-sqfzx 0/1 Completed 2 49s 10.42.0.2 k3s-master <none> <none>
2.3 接入 agent 节点
- 参考前面步骤
1. containerd runc cni 安装
2.1 准备介质
2.2 安装 master 节点
-下载脚本
- 安装
- 查看 master 节点 token
来自服务器的令牌通常位于/var/lib/rancher/k3s/server/token
[root@k3s-master k3s]# cat /var/lib/rancher/k3s/server/token
K108226e8e6a76a0b1f8586b2f191ad16e496d190854d08310b07168c2cfa5f0bca::server:0c8280fe93b598d279470bf8648b2344
- 接入命令
INSTALL_K3S_SKIP_DOWNLOAD=true \
K3S_URL=https://10.29.33.52:6443 \
K3S_TOKEN=K108226e8e6a76a0b1f8586b2f191ad16e496d190854d08310b07168c2cfa5f0bca::server:0c8280fe93b598d279470bf8648b2344 \
./install.sh
[INFO] Skipping k3s download and verify
[INFO] Skipping installation of SELinux RPM
[INFO] Creating /usr/local/bin/kubectl symlink to k3s
[INFO] Creating /usr/local/bin/crictl symlink to k3s
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, already exists
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-agent-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s-agent.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s-agent.service
[INFO] systemd: Enabling k3s-agent unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s-agent.service → /etc/systemd/system/k3s-agent.service.
[INFO] systemd: Starting k3s-agent
- 检查
[root@k3s-master k3s]# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k3s-master Ready control-plane,master 9m56s v1.26.2+k3s1 10.29.33.52 <none> Kylin Linux Advanced Server V10 (Sword) 4.19.90-25.24.v2101.ky10.aarch64 containerd://1.6.15-k3s1
k3s-agent Ready <none> 42s v1.26.2+k3s1 10.29.33.54 <none> Kylin Linux Advanced Server V10 (Sword) 4.19.90-25.24.v2101.ky10.aarch64 containerd://1.6.15-k3s1
[root@k3s-master k3s]# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-5c6b6c5476-tz8jn 1/1 Running 0 9m46s 10.42.0.4 k3s-master <none> <none>
kube-system local-path-provisioner-5d56847996-n27l6 1/1 Running 0 9m46s 10.42.0.5 k3s-master <none> <none>
kube-system helm-install-traefik-crd-cnjhj 0/1 Completed 0 9m47s 10.42.0.3 k3s-master <none> <none>
kube-system metrics-server-7b67f64457-bzgdt 1/1 Running 0 9m46s 10.42.0.6 k3s-master <none> <none>
kube-system svclb-traefik-569139e2-rgdqr 2/2 Running 0 9m26s 10.42.0.7 k3s-master <none> <none>
kube-system traefik-56b8c5fb5c-g5ggl 1/1 Running 0 9m26s 10.42.0.8 k3s-master <none> <none>
kube-system helm-install-traefik-sqfzx 0/1 Completed 2 9m47s 10.42.0.2 k3s-master <none> <none>
kube-system svclb-traefik-569139e2-4tsz4 2/2 Running 0 44s 10.42.1.2 k3s-agent <none> <none>
3. k8s-dashboard 安装
- 安装
[root@k3s-master ~]# GITHUB_URL=https://github.com/kubernetes/dashboard/releases
[root@k3s-master ~]# VERSION_KUBE_DASHBOARD=$(curl -w '%{url_effective}' -I -L -s -S ${GITHUB_URL}/latest -o /dev/null | sed -e 's|.*/||')
[root@k3s-master ~]# sudo k3s kubectl create -f https://raw.githubusercontent.com/kubernetes/dashboard/${VERSION_KUBE_DASHBOARD}/aio/deploy/recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
- 创建 admin-user 的 serviceaccount
[root@k3s-master k8s-dashboard]# kubectl apply -f admin-user.yaml
serviceaccount/admin-user created
- 创建 clusterrolebinding
vi admin-user-clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
[root@k3s-master k8s-dashboard]# kubectl apply -f admin-user-clusterrolebinding.yaml
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
- 创建 token
[root@k3s-master k8s-dashboard]# k3s kubectl create token admin-user -n kubernetes-dashboard
eyJhbGciOiJSUzI1NiIsImtpZCI6IkZQY0NuTGh5Vy1FMEdWb3hlQk4tWmpJZ2E3WW9CM2ZKNURQejRoX1hFalkifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiLCJrM3MiXSwiZXhwIjoxNjc5MDY2MTkzLCJpYXQiOjE2NzkwNjI1OTMsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiMjAyZDdlZTUtNjg3MC00YjgxLTljYzktM2FlNWNhNTkyYjBjIn19LCJuYmYiOjE2NzkwNjI1OTMsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.tH_jW4FbuWzu9qcPsBUaUjTNOIaaahY5uV0svTiV_9V0BnzrYgFFe7czhIOkoluLmWnbBwxv1xCp4rwR42Vkpd99gHd8nfQAHhCzk2pypomF9gyr2UeKF1SvcbY4PXbOYaqJ3G-CX9l8uHQCvG3Uev70Xzy6eouDegeEsjfo_h7l1M3xfMf9KQ0x-1ErLt9sm5nL0dO0B9nagcgRZObk-RlwP7kT4MwJ4EF6anjxlfJ7GX-HWwrdodNCHqxX-zkM-K1v0Slzvn0jMif01G6d7uu8CyW18xsP65XwW2hwSpcvpe9VoZYKkhRDhQVz83UtPqPZF9BdqmOVBKp6-Ucxxw
- 检查发现 imagepullfailed,手动 pull 即可(dockerhub 国内直通)
ctr images pull docker.io/kubernetesui/dashboard:v.2.7.0
ctr images pull docker.io/kubernetesui/metrics-scraper:v1.0.8
4. traefik 使用
4.1 ui 调试 (ingressRoute、dashboard)
- 修改 traefik 的 ingressRoute 规则 ( entryPoints: - web,默认是 trarfik 导致无法访问)
[root@k3s-master manifests]# kubectl get ingressroute -n kube-system -o yaml
apiVersion: v1
items:
- apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
annotations:
helm.sh/hook: post-install,post-upgrade
meta.helm.sh/release-name: traefik
meta.helm.sh/release-namespace: kube-system
creationTimestamp: "2023-03-17T06:43:38Z"
generation: 8
labels:
app.kubernetes.io/instance: traefik-kube-system
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: traefik
helm.sh/chart: traefik-20.3.1_up20.3.0
name: traefik-dashboard
namespace: kube-system
resourceVersion: "2722"
uid: 7360d929-ab7a-45a8-ba8d-7ca60e586fb5
spec:
entryPoints:
- web # 默认是 traefik 会导致无法访问 UI
routes:
- kind: Rule
# 默认不带 Host,用 IP 访问即可 PathPrefix(`/dashboard`) || PathPrefix(`/api`)
match: Host(`mwb.k3straefik.com`) && (PathPrefix(`/dashboard`) || PathPrefix(`/api`))
services:
- kind: TraefikService
name: api@internal
kind: List
metadata:
resourceVersion: ""
4.2 UI 页面
- 域名访问 http://mwb.k3straefik.com/dashboard/
附录
- 说明
- 默认配置文件目录
/var/lib/rancher/k3s/server/
- manifests
各组件的 yaml 文件,k3s dameon 服务重启后会覆盖此文件
- token
节点接入使用
- static
traefik 的 helm 模版文件
- 组件
coredns、traefik、local-storage和metrics-server、servicelbLoadBalancer
- 禁用组件的部署
--disable
- .skip 的神奇支持
前面说过,重启会导致 manifests 下面的资源全部还原(如果有修改),那么可以用过创建某个资源的 skip 文件,来规避这种问题
traefik.yaml.skip # 表示跳过对该资源的覆盖
- kubectl 自动补全
yum install bash-completion -y
source /usr/share/bash-completion/bash_completion
echo 'source <(kubectl completion bash)' >>~/.bashrc
echo 'source <(kubectl completion bash)' >>~/.bashrc
source ~/.bashrc
kubectl completion bash >/etc/bash_completion.d/kubectl
ClusterPedia-介绍
ClusterPedia 概念
1. PediaCluster
# PediaCluster 是什么?
个人理解:我称它为实例,一个集群一个实例,这个实例包含了认证信息和需要同步给 clusterpedia 的资源信息
# PediaCluster 怎么用?
- 包含集群集群的认证信息
- kubeconfig # 集群的 kubeconfig 文件,使用它 pediacluster 的 apiserver 列显示为空
- caData # namesapce 下 serviceaccoint 的 secret ca (推荐)
- tokenData # namesapce 下 serviceaccoint 的 secret ca (推荐)
- certData # 证书
- keyData # 证书
- 包含集群需要同步的资源信息
- syncResources: [] # 自定义需要同步的资源,deploy、pod、configmap、secret、......
- syncAllCustomResources: false # 同步所有自定义资源
- syncResourcesRefName: "" # 引用公共的集群同步配置
2. ClusterSyncResources
# ClusterSyncResources 是什么?
一个公共/通用的集群资源同步配置,有了它在创建 PediaCluster 实例时就不用配置 syncResources,使用 syncResourcesRefName 引用即可,如果两者并存,那么取两者并集
# ClusterSyncResources 示例:
root@master01 ~]# kubectl get clustersyncresources.cluster.clusterpedia.io cluster-sync-resources-example -o yaml
apiVersion: cluster.clusterpedia.io/v1alpha2
kind: ClusterSyncResources
metadata:
name: cluster-sync-resources-example
spec:
syncResources:
- group: ""
resources:
- pods
versions:
- v1
- group: ""
resources:
- nodes
- services
- ingress
- secrets
- configmaps
# PediaCluster 示例:
[root@master01 ~]# kubectl get pediacluster dce4-010 -o yaml
apiVersion: cluster.clusterpedia.io/v1alpha2
kind: PediaCluster
metadata:
name: dce4-010
spec:
apiserver: https://10.29.16.27:16443
caData: ""
tokenData: ""
syncResources:
- group: apps
resources:
- deployments
- group: ""
resources:
- pods
- configmaps
- group: cert-manager.io
resources:
- certificates
versions:
- v1
syncResourcesRefName: cluster-sync-resources-example
3. Collection Resource
# Collection Resource(聚合资源) 是什么?
- 一次获取多个类型的资源
- 不同类型资源组合而成
- 多种资源进行统一的检索和分页
- 只能检索 pediacluster 都同步了的资源类型,比如,两个资源都同步了 sts ,如果一个没有同步就会聚合资源时就不会显示 sts 资源
# 目前支持的聚合资源(建议:kubectl get --raw="$API" api 的形式对资源进行检索和分页)
- any # 所有资源,不能使用 kubectl 工具获取, 使用 url 时需要定义 grops / resources
- workloads # deployment\daemonsets\statefulsets
- kuberesources # kubernetes 所有内置资源
# kubectl get collectionresources any
# kubectl get collectionresources workloads
# kubectl get deploy,cm,secrets --cluster clusterpedia -A
# kubectl get collectionresources.clusterpedia.io kuberesources
# kubectl get --raw="/apis/clusterpedia.io/v1beta1/collectionresources/workloads?limit=2" | jq
# kubectl get --raw "/apis/clusterpedia.io/v1beta1/collectionresources/any?onlyMetadata=true&resources=apps/deployments&limit=2" | jq
# 暂不支持自定义
4. ClusterImportPolicy
# ClusterImportPolicy(自动接入)
- 定义某种资源,并根据前期约定的模板、条件来自动创建、更新、删除 pediacluster
- 对于已经存在的 pediacluster 不会创建和删除,只会对其更新/手动删除
ClusterPedia-安装-v0.6.3
1. 下载 clusterpedia 项目到本地
[root@master01 ~]# git clone https://github.com/clusterpedia-io/clusterpedia.git
[root@master01 ~]# cd clusterpedia
2. 部署 mysql 组件
2.1. 安装 mysql
cd ./deploy/internalstorage/mysql
# 重新定义 mysql pv 和 job yaml 文件 ( pv 需要更改 hostpath 路径也在这里更改)
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# export STORAGE_NODE_NAME=worker01
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# sed "s|__NODE_NAME__|$STORAGE_NODE_NAME|g" `grep __NODE_NAME__ -rl ./templates` > clusterpedia_internalstorage_pv.yaml
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# cat clusterpedia_internalstorage_pv.yaml
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: clusterpedia-internalstorage-mysql
labels:
app: clusterpedia-internalstorage
internalstorage.clusterpedia.io/type: mysql
spec:
capacity:
storage: 20Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
local:
path: /var/local/clusterpedia/internalstorage/mysql
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker01
---
apiVersion: batch/v1
kind: Job
metadata:
name: check-worker01-mysql-local-pv-dir
namespace: clusterpedia-system
labels:
app: clusterpedia-internalstorage
internalstorage.clusterpedia.io/type: mysql
spec:
ttlSecondsAfterFinished: 600
template:
metadata:
labels:
app: clusterpedia-internalstorage
internalstorage.clusterpedia.io/type: mysql
job: check-node-local-pv-dir
spec:
restartPolicy: Never
nodeName: worker01
containers:
- name: check-dir
image: mysql:8
command: ['sh', '-c', 'stat /var/lib/mysql']
volumeMounts:
- name: pv-dir
mountPath: /var/lib/mysql
volumes:
- name: pv-dir
hostPath:
path: /var/local/clusterpedia/internalstorage/mysql
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
# 部署 mysql
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# kubectl apply -f .
namespace/clusterpedia-system created
configmap/clusterpedia-internalstorage created
service/clusterpedia-internalstorage-mysql created
persistentvolumeclaim/internalstorage-mysql created
deployment.apps/clusterpedia-internalstorage-mysql created
persistentvolume/clusterpedia-internalstorage-mysql created
job.batch/check-worker01-mysql-local-pv-dir created
secret/internalstorage-password created
2.2 检查 mysql 状态
# 查看组件资源
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# kubectl get all -n clusterpedia-system
NAME READY STATUS RESTARTS AGE
pod/check-worker01-mysql-local-pv-dir-gqrpc 0/1 Completed 0 2m43s
pod/clusterpedia-internalstorage-mysql-6c4778f66b-7shcd 1/1 Running 0 2m43s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/clusterpedia-internalstorage-mysql ClusterIP 10.233.28.80 <none> 3306/TCP 2m43s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/clusterpedia-internalstorage-mysql 1/1 1 1 2m43s
NAME DESIRED CURRENT READY AGE
replicaset.apps/clusterpedia-internalstorage-mysql-6c4778f66b 1 1 1 2m43s
NAME COMPLETIONS DURATION AGE
job.batch/check-worker01-mysql-local-pv-dir 1/1 4s 2m43s
[root@master01 ~/clusterpedia/deploy/internalstorage/mysql]# kubectl get pvc -n clusterpedia-system
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
internalstorage-mysql Bound clusterpedia-internalstorage-mysql 20Gi RWO 3m14s
# 查看 mysql 密码
echo `kubectl get secret -n clusterpedia-system internalstorage-password -o jsonpath='{.data.password}'` | base64 -d
dangerous0
3. 安装 clusterpedia
3.1 clusterpedia
# 查看项目文件
[root@master01 ~/clusterpedia]# ll
total 216
-rw-r--r--. 1 root root 344 Feb 28 20:57 builder.dockerfile
-rw-r--r--. 1 root root 0 Feb 28 16:56 builder.dockerfile.dockerignore
drwxr-xr-x. 3 root root 86 Feb 28 16:56 charts
drwxr-xr-x. 6 root root 104 Feb 28 16:56 cmd
-rw-r--r--. 1 root root 144 Feb 28 16:56 CODE_OF_CONDUCT.md
-rw-r--r--. 1 root root 4192 Feb 28 16:56 CONTRIBUTING.md
drwxr-xr-x. 6 root root 4096 Feb 28 16:56 deploy
-rw-r--r--. 1 root root 319 Feb 28 20:57 Dockerfile
drwxr-xr-x. 3 root root 20 Feb 28 16:56 docs
drwxr-xr-x. 2 root root 134 Feb 28 16:56 examples
-rw-r--r--. 1 root root 8466 Feb 28 20:57 go.mod
-rw-r--r--. 1 root root 98838 Feb 28 20:57 go.sum
-rw-r--r--. 1 root root 6605 Feb 28 16:56 GOVERNANCE.md
drwxr-xr-x. 2 root root 4096 Feb 28 20:57 hack
-rw-r--r--. 1 root root 2270 Feb 28 16:56 ldflags.sh
-rw-r--r--. 1 root root 11357 Feb 28 16:56 LICENSE
-rw-r--r--. 1 root root 374 Feb 28 20:57 MAINTAINERS.md
-rw-r--r--. 1 root root 9063 Feb 28 16:56 Makefile
-rw-r--r--. 1 root root 70 Feb 28 16:56 OWNERS
drwxr-xr-x. 13 root root 196 Feb 28 16:56 pkg
-rw-r--r--. 1 root root 25220 Feb 28 20:57 README.md
-rw-r--r--. 1 root root 2253 Feb 28 16:56 ROADMAP.md
drwxr-xr-x. 3 root root 17 Feb 28 16:56 staging
drwxr-xr-x. 4 root root 85 Feb 28 20:57 test
drwxr-xr-x. 12 root root 214 Feb 28 20:57 vendor
# 下发 deploy 目录下所有资源
[root@master01 ~/clusterpedia]# kubectl apply -f deploy/
customresourcedefinition.apiextensions.k8s.io/clustersyncresources.cluster.clusterpedia.io created
Warning: Detected changes to resource pediaclusters.cluster.clusterpedia.io which is currently being deleted.
customresourcedefinition.apiextensions.k8s.io/pediaclusters.cluster.clusterpedia.io configured
apiservice.apiregistration.k8s.io/v1beta1.clusterpedia.io created
serviceaccount/clusterpedia-apiserver created
service/clusterpedia-apiserver created
deployment.apps/clusterpedia-apiserver created
clusterrole.rbac.authorization.k8s.io/clusterpedia created
clusterrolebinding.rbac.authorization.k8s.io/clusterpedia created
serviceaccount/clusterpedia-clustersynchro-manager created
deployment.apps/clusterpedia-clustersynchro-manager created
serviceaccount/clusterpedia-controller-manager created
deployment.apps/clusterpedia-controller-manager created
namespace/clusterpedia-system unchanged
Warning: Detected changes to resource clusterimportpolicies.policy.clusterpedia.io which is currently being deleted.
customresourcedefinition.apiextensions.k8s.io/clusterimportpolicies.policy.clusterpedia.io configured
customresourcedefinition.apiextensions.k8s.io/pediaclusterlifecycles.policy.clusterpedia.io created
# 2 个 warning 时因为前期没有删除干净导致,通过创建时间可以看出
[root@master01 ~/clusterpedia]# kubectl get crd | grep clusterpedia
clusterimportpolicies.policy.clusterpedia.io 2022-12-08T08:26:47Z
clustersyncresources.cluster.clusterpedia.io 2023-02-28T13:15:35Z
pediaclusterlifecycles.policy.clusterpedia.io 2023-02-28T13:15:35Z
pediaclusters.cluster.clusterpedia.io 2022-12-08T08:26:47Z
# 4 个 无状态资源类型
deployment.apps/clusterpedia-apiserver created (svc、sa、secret) ------> mysql、-----> pediacluster 来兼容 k8 api 做一下复杂的资源检索
deployment.apps/clusterpedia-clustersynchro-manager created (sa) -----> mysql、-----> pediacluster 进行资源同步
deployment.apps/clusterpedia-controller-manager created (sa)
deployment.apps/clusterpedia-internalstorage-mysql # 步骤 2 已安装
# 4 个 crd (后期接入集群是,如果报错,可以到 crds 目录再执行下)
customresourcedefinition.apiextensions.k8s.io/clustersyncresources.cluster.clusterpedia.io created
customresourcedefinition.apiextensions.k8s.io/pediaclusters.cluster.clusterpedia.io configured
customresourcedefinition.apiextensions.k8s.io/clusterimportpolicies.policy.clusterpedia.io configured
customresourcedefinition.apiextensions.k8s.io/pediaclusterlifecycles.policy.clusterpedia.io created
# clusterrole、clusterrolebinding (apiserver、clustersynchro-manager、controller-manager)
clusterrole.rbac.authorization.k8s.io/clusterpedia created
clusterrolebinding.rbac.authorization.k8s.io/clusterpedia created
3.2 检查各组件状态
[root@master01 ~/clusterpedia]# kubectl get deployments.apps -n clusterpedia-system
NAME READY UP-TO-DATE AVAILABLE AGE
clusterpedia-apiserver 1/1 1 1 12h
clusterpedia-clustersynchro-manager 1/1 1 1 12h
clusterpedia-controller-manager 1/1 1 1 12h
clusterpedia-internalstorage-mysql 1/1 1 1 13h
[root@master01 ~/clusterpedia]# kubectl get pod -n clusterpedia-system
NAME READY STATUS RESTARTS AGE
clusterpedia-apiserver-b7d9ddd86-hlq8k 1/1 Running 0 12h
clusterpedia-clustersynchro-manager-84fbdf5758-x948t 1/1 Running 0 12h
clusterpedia-controller-manager-6fc45659dd-sxmsd 1/1 Running 0 12h
clusterpedia-internalstorage-mysql-6c4778f66b-7shcd 1/1 Running 0 13h
4. 接入集群
4.1 创建 rbac 资源并获取 token
# 创建 clusterrole、clusterrolebinding、sa、secretn(1.22 之后默认创建的 sa,不带 secret)
[root@master01 ~/clusterpedia/examples]# pwd
/root/clusterpedia/examples
[root@master01 ~/clusterpedia/examples]# cat clusterpedia_synchro_rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: clusterpedia-synchro
rules:
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
- nonResourceURLs:
- '*'
verbs:
- '*'
---
apiVersion: v1
kind: ServiceAccount # 1.24 之后的版本 sa 不带 secret 密钥,需要自行创建
metadata:
name: clusterpedia-synchro
namespace: default
---
apiVersion: v1
kind: Secret
metadata:
name: clusterpedia-synchro
namespace: default
annotations:
kubernetes.io/service-account.name: clusterpedia-synchro
type: kubernetes.io/service-account-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterpedia-synchro
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: clusterpedia-synchro
subjects:
- kind: ServiceAccount
name: clusterpedia-synchro
namespace: default
---
root@master01 ~/clusterpedia/examples]# kubectl apply -f clusterpedia_synchro_rbac.yaml
clusterrole.rbac.authorization.k8s.io/clusterpedia-synchro unchanged
serviceaccount/clusterpedia-synchro unchanged
secret/clusterpedia-synchro created
clusterrolebinding.rbac.authorization.k8s.io/clusterpedia-synchro unchanged
# 查看 secret 种 的 ca 、 token
[root@master01 ~/clusterpedia/examples]# kubectl get sa clusterpedia-synchro -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"clusterpedia-synchro","namespace":"default"}}
creationTimestamp: "2023-03-20T02:29:28Z"
name: clusterpedia-synchro
namespace: default
resourceVersion: "62487008"
uid: a34d7e2a-1ad5-488d-b9aa-8f9682fa2206
[root@master01 ~/clusterpedia/examples]# kubectl get secret clusterpedia-synchro -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1UQXlPVEEzTXpFME1Wb1hEVE15TVRBeU5qQTNNekUwTVZvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTlpMCjhvVitVemo4Ky9CYTZ1MkVyV2tVQ3IxRitUeEZXSlRRZmMrWE44UGtOMDRUa1V4VzdnTVo4SHUzeFFoZHY1eGsKSmRwNCtRNFFyM1B1U1Z4MGMvNlBOVUFwOVRCY3EyVTRZK09hZjJhR3pXRWxaNXIzVnBRUDF5akx2UURtbUpxRwowVHNnYU1UTnVBQ3ZPRW56eFRzNkZzdkFFTmZ6djhZWDlDeUs4azlTam5qSy9xaS9pSUlLSm45NG1yUUQ5SUtnCkFyYUw2MDMvRzhFMzJGVUFwc3FvVUh1V3pGclRQY2ZNd0xpbWVXeS9PU2lkRTU5aGR2Q2lHWHNvWGxMTURKSXAKT1dsT1FHL2Y3VHNZMFdLMXNvQ3drTjZYdkY0c1J4T1JCK1pQRS9qSFdLbVhhSm5jQ1hMNStocnh1MXg1Z1lJcgpManZ1YUR0NmdYWm5qSXBNYzdrQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZHem5rbkZ0ajFkNzRhN2pNRUd2TWdFQXIzcGpNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBQmtJZG4xWW93YllGWTdyeHltawo1VWdmRkFwRzBDcUVjSmY1Unk1QU9mYWNxRldaZTF0Yk9kSy9nSEtDT2JRdTQ0Zi94Mnh0K1VqYnllRzYrYmRkCk52THhrOXg1REtjM29ZU1l0bWtqTkxoM2lpYzRNRHZDcmwwWGZzd2R5bDVQbDdqaHBLVE5XMHIyNEt4NDlZdWcKVDNBcURJcFROL3ppTURwMHk5SXFhMkFRcEkyQ0c2cUZOakxlcmxqclFISVZubDZwbjl3WndIVnluL1RsT1hhRgpKRjVLRHg4S3R4ck1zamhTY2pwZzZ4cUJLam8wWDlTenV2UGhUL3dUejQrekhQb1JodzBSMnJlbUNpR1llUFB1Ck9CT2l0WUJwdkYyYVhKcUxpcVFWWG5GdGRyaE81dEVYcW14YmV4amRqUlFBWUQ3UXVRaG9ONlk1Tlc1TzNGcGEKeGFzPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
namespace: ZGVmYXVsdA==
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNklqVTFaRUZKVTJ4UWVURktXamxYZW1GemF6TXpPV2swVm1aaFJWazNkbEJUY1hOc01XeG1SMkoxTlhjaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUprWldaaGRXeDBJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpXTnlaWFF1Ym1GdFpTSTZJbU5zZFhOMFpYSndaV1JwWVMxemVXNWphSEp2SWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXpaWEoyYVdObExXRmpZMjkxYm5RdWJtRnRaU0k2SW1Oc2RYTjBaWEp3WldScFlTMXplVzVqYUhKdklpd2lhM1ZpWlhKdVpYUmxjeTVwYnk5elpYSjJhV05sWVdOamIzVnVkQzl6WlhKMmFXTmxMV0ZqWTI5MWJuUXVkV2xrSWpvaVlUTTBaRGRsTW1FdE1XRmtOUzAwT0Roa0xXSTVZV0V0T0dZNU5qZ3labUV5TWpBMklpd2ljM1ZpSWpvaWMzbHpkR1Z0T25ObGNuWnBZMlZoWTJOdmRXNTBPbVJsWm1GMWJIUTZZMngxYzNSbGNuQmxaR2xoTFhONWJtTm9jbThpZlEuR2pBb1MxZ0RUdUdmSkd5UEJqWHpxcDRwa0ljMWpOX0dvUXZway1VeFE0OEdKUk9lSHFaZFdwZi1CeEZCMHdFUjd2ME9ub19EMGtndHRjRHJzZUluaGx2RVdHa3dwZHEyMVVUeHFhQ293aE1mMWsxdFk4ZVZCQzVBWTJqTVhPN0pMM05KM2xpU25LNFZWbjYtVlpEcXg3dTlxMXFFSE8tb3hubjNleklRSGtLSmFFei03SUlNSlJ5ZGN5R1lPZk9pUTFhbnZqa0ZpUm93VkRZSG1pM1Q0ZVBEbEtqTW9kU0VxTWxUYU9FcmF6YVl0TXJKdmdpYmRrZl9LQzFrVTdYYldaMGhIZHMtTFJCOHoyenV0QWFfZTcxbDNmTmxEWWdvMEdzYjA1d1B3anE1Mm1jc2hxWkEwbG1MdnI2bnkzVEJ6OTVsT3FSdmgxYWZpTmZyU1lHekpR
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Secret","metadata":{"annotations":{"kubernetes.io/service-account.name":"clusterpedia-synchro"},"name":"clusterpedia-synchro","namespace":"default"},"type":"kubernetes.io/service-account-token"}
kubernetes.io/service-account.name: clusterpedia-synchro
kubernetes.io/service-account.uid: a34d7e2a-1ad5-488d-b9aa-8f9682fa2206
creationTimestamp: "2023-03-20T02:51:13Z"
name: clusterpedia-synchro
namespace: default
resourceVersion: "62496452"
uid: b20e8ebc-2c54-4a30-a39d-ed1dec5a42bd
type: kubernetes.io/service-account-token
4.2 生成 pediacluster 实例 并接入集群
# pediacluster 配置文件
[root@master01 ~/clusterpedia/examples]# kubectl get secret clusterpedia-synchro -o jsonpath='{.data.ca\.crt}'
[root@master01 ~/clusterpedia/examples]# kubectl get secret clusterpedia-synchro -o jsonpath='{.data.toekn}'
# 配置文件如下
root@master01 ~]# cat clusterpedia/examples/dce5-mmber-pediacluster.yaml
apiVersion: cluster.clusterpedia.io/v1alpha2
kind: PediaCluster
metadata:
name: dce5-member
spec:
apiserver: "https://10.29.15.79:6443"
caData: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUMvakNDQWVhZ0F3SUJBZ0lCQURBTkJna3Foa2lHOXcwQkFRc0ZBREFWTVJNd0VRWURWUVFERXdwcmRXSmwKY201bGRHVnpNQjRYRFRJeU1UQXlPVEEzTXpFME1Wb1hEVE15TVRBeU5qQTNNekUwTVZvd0ZURVRNQkVHQTFVRQpBeE1LYTNWaVpYSnVaWFJsY3pDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBTlpMCjhvVitVemo4Ky9CYTZ1MkVyV2tVQ3IxRitUeEZXSlRRZmMrWE44UGtOMDRUa1V4VzdnTVo4SHUzeFFoZHY1eGsKSmRwNCtRNFFyM1B1U1Z4MGMvNlBOVUFwOVRCY3EyVTRZK09hZjJhR3pXRWxaNXIzVnBRUDF5akx2UURtbUpxRwowVHNnYU1UTnVBQ3ZPRW56eFRzNkZzdkFFTmZ6djhZWDlDeUs4azlTam5qSy9xaS9pSUlLSm45NG1yUUQ5SUtnCkFyYUw2MDMvRzhFMzJGVUFwc3FvVUh1V3pGclRQY2ZNd0xpbWVXeS9PU2lkRTU5aGR2Q2lHWHNvWGxMTURKSXAKT1dsT1FHL2Y3VHNZMFdLMXNvQ3drTjZYdkY0c1J4T1JCK1pQRS9qSFdLbVhhSm5jQ1hMNStocnh1MXg1Z1lJcgpManZ1YUR0NmdYWm5qSXBNYzdrQ0F3RUFBYU5aTUZjd0RnWURWUjBQQVFIL0JBUURBZ0trTUE4R0ExVWRFd0VCCi93UUZNQU1CQWY4d0hRWURWUjBPQkJZRUZHem5rbkZ0ajFkNzRhN2pNRUd2TWdFQXIzcGpNQlVHQTFVZEVRUU8KTUF5Q0NtdDFZbVZ5Ym1WMFpYTXdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBQmtJZG4xWW93YllGWTdyeHltawo1VWdmRkFwRzBDcUVjSmY1Unk1QU9mYWNxRldaZTF0Yk9kSy9nSEtDT2JRdTQ0Zi94Mnh0K1VqYnllRzYrYmRkCk52THhrOXg1REtjM29ZU1l0bWtqTkxoM2lpYzRNRHZDcmwwWGZzd2R5bDVQbDdqaHBLVE5XMHIyNEt4NDlZdWcKVDNBcURJcFROL3ppTURwMHk5SXFhMkFRcEkyQ0c2cUZOakxlcmxqclFISVZubDZwbjl3WndIVnluL1RsT1hhRgpKRjVLRHg4S3R4ck1zamhTY2pwZzZ4cUJLam8wWDlTenV2UGhUL3dUejQrekhQb1JodzBSMnJlbUNpR1llUFB1Ck9CT2l0WUJwdkYyYVhKcUxpcVFWWG5GdGRyaE81dEVYcW14YmV4amRqUlFBWUQ3UXVRaG9ONlk1Tlc1TzNGcGEKeGFzPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
tokenData: "ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNklqVTFaRUZKVTJ4UWVURktXamxYZW1GemF6TXpPV2swVm1aaFJWazNkbEJUY1hOc01XeG1SMkoxTlhjaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUprWldaaGRXeDBJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpXTnlaWFF1Ym1GdFpTSTZJbU5zZFhOMFpYSndaV1JwWVMxemVXNWphSEp2SWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXpaWEoyYVdObExXRmpZMjkxYm5RdWJtRnRaU0k2SW1Oc2RYTjBaWEp3WldScFlTMXplVzVqYUhKdklpd2lhM1ZpWlhKdVpYUmxjeTVwYnk5elpYSjJhV05sWVdOamIzVnVkQzl6WlhKMmFXTmxMV0ZqWTI5MWJuUXVkV2xrSWpvaVlUTTBaRGRsTW1FdE1XRmtOUzAwT0Roa0xXSTVZV0V0T0dZNU5qZ3labUV5TWpBMklpd2ljM1ZpSWpvaWMzbHpkR1Z0T25ObGNuWnBZMlZoWTJOdmRXNTBPbVJsWm1GMWJIUTZZMngxYzNSbGNuQmxaR2xoTFhONWJtTm9jbThpZlEuR2pBb1MxZ0RUdUdmSkd5UEJqWHpxcDRwa0ljMWpOX0dvUXZway1VeFE0OEdKUk9lSHFaZFdwZi1CeEZCMHdFUjd2ME9ub19EMGtndHRjRHJzZUluaGx2RVdHa3dwZHEyMVVUeHFhQ293aE1mMWsxdFk4ZVZCQzVBWTJqTVhPN0pMM05KM2xpU25LNFZWbjYtVlpEcXg3dTlxMXFFSE8tb3hubjNleklRSGtLSmFFei03SUlNSlJ5ZGN5R1lPZk9pUTFhbnZqa0ZpUm93VkRZSG1pM1Q0ZVBEbEtqTW9kU0VxTWxUYU9FcmF6YVl0TXJKdmdpYmRrZl9LQzFrVTdYYldaMGhIZHMtTFJCOHoyenV0QWFfZTcxbDNmTmxEWWdvMEdzYjA1d1B3anE1Mm1jc2hxWkEwbG1MdnI2bnkzVEJ6OTVsT3FSdmgxYWZpTmZyU1lHekpR"
syncResources:
- group: apps
resources:
- deployments
- group: ""
resources:
- pods
# 过程报错(提示 crd 没有创建)
[root@master01 ~/clusterpedia/examples]# kubectl apply -f dce5-mmber-pediacluster.yaml
error: resource mapping not found for name: "dce5-member" namespace: "" from "dce5-mmber-pediacluster.yaml": no matches for kind "PediaCluster" in version "cluster.clusterpedia.io/v1alpha2"
ensure CRDs are installed first
[root@master01 ~/clusterpedia/examples]# cd ..
[root@master01 ~/clusterpedia]# kubectl apply -f deploy/crds/cluster.clusterpedia.io_pediaclusters.yaml
customresourcedefinition.apiextensions.k8s.io/pediaclusters.cluster.clusterpedia.io created
# 对接 dce5 成员集群
[root@master01 ~/clusterpedia/examples]# kubectl apply -f dce5-mmber-pediacluster.yaml
pediacluster.cluster.clusterpedia.io/dce5-member created
# 对接 dce4.0.10 集群
[root@master01 ~/clusterpedia/examples]# kubectl apply -f /root/clusterpedia-v0.5.0/examples/pediacluster-dce4010.yaml
pediacluster.cluster.clusterpedia.io/dce4-010 created
4.3 状态检查
# 检查同步状态
[root@master01 ~/clusterpedia/examples]# kubectl get pediacluster -o wide
NAME READY VERSION APISERVER VALIDATED SYNCHRORUNNING CLUSTERHEALTHY
dce5-member True v1.24.7 https://10.29.15.79:6443 Validated Running Healthy
# 检查 mysql 数据
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| clusterpedia |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.03 sec)
mysql> use clusterpedia
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SELECT * FROM clusterpedia.resources where resource = 'deployments' limit 2 \G
*************************** 1. row ***************************
id: 1
group: apps
version: v1
resource: deployments
kind: Deployment
cluster: dce5-member
namespace: kube-system
name: calico-kube-controllers
owner_uid:
uid: ddc79a37-8d8f-4960-a187-c9d68a430f02
resource_version: 13743249
object: {"kind": "Deployment", "spec": {"replicas": 1, "selector": {"matchLabels": {"k8s-app": "calico-kube-controllers"}}, "strategy": {"type": "Recreate"}, "template": {"spec": {"dnsPolicy": "ClusterFirst", "containers": [{"env": [{"name": "ENABLED_CONTROLLERS", "value": "node"}, {"name": "DATASTORE_TYPE", "value": "kubernetes"}], "name": "calico-kube-controllers", "image": "quay.m.daocloud.io/calico/kube-controllers:v3.23.3", "resources": {"limits": {"cpu": "1", "memory": "256M"}, "requests": {"cpu": "30m", "memory": "64M"}}, "livenessProbe": {"exec": {"command": ["/usr/bin/check-status", "-l"]}, "periodSeconds": 10, "timeoutSeconds": 1, "failureThreshold": 6, "successThreshold": 1, "initialDelaySeconds": 10}, "readinessProbe": {"exec": {"command": ["/usr/bin/check-status", "-r"]}, "periodSeconds": 10, "timeoutSeconds": 1, "failureThreshold": 3, "successThreshold": 1}, "imagePullPolicy": "IfNotPresent", "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File"}], "hostNetwork": true, "tolerations": [{"key": "node-role.kubernetes.io/master", "effect": "NoSchedule"}, {"key": "node-role.kubernetes.io/control-plane", "effect": "NoSchedule"}], "nodeSelector": {"kubernetes.io/os": "linux"}, "restartPolicy": "Always", "schedulerName": "default-scheduler", "serviceAccount": "calico-kube-controllers", "securityContext": {}, "priorityClassName": "system-cluster-critical", "serviceAccountName": "calico-kube-controllers", "terminationGracePeriodSeconds": 30}, "metadata": {"name": "calico-kube-controllers", "labels": {"k8s-app": "calico-kube-controllers"}, "namespace": "kube-system", "creationTimestamp": null}}, "revisionHistoryLimit": 10, "progressDeadlineSeconds": 600}, "status": {"replicas": 1, "conditions": [{"type": "Progressing", "reason": "NewReplicaSetAvailable", "status": "True", "message": "ReplicaSet \"calico-kube-controllers-7cd4576599\" has successfully progressed.", "lastUpdateTime": "2022-10-29T07:37:57Z", "lastTransitionTime": "2022-10-29T07:36:30Z"}, {"type": "Available", "reason": "MinimumReplicasAvailable", "status": "True", "message": "Deployment has minimum availability.", "lastUpdateTime": "2023-01-06T03:37:48Z", "lastTransitionTime": "2023-01-06T03:37:48Z"}], "readyReplicas": 1, "updatedReplicas": 1, "availableReplicas": 1, "observedGeneration": 1}, "metadata": {"uid": "ddc79a37-8d8f-4960-a187-c9d68a430f02", "name": "calico-kube-controllers", "labels": {"k8s-app": "calico-kube-controllers"}, "namespace": "kube-system", "generation": 1, "annotations": {"deployment.kubernetes.io/revision": "1", "shadow.clusterpedia.io/cluster-name": "dce5-member"}, "resourceVersion": "13743249", "creationTimestamp": "2022-10-29T07:36:30Z"}, "apiVersion": "apps/v1"}
created_at: 2022-10-29 07:36:30.000
synced_at: 2023-03-20 06:06:44.674
deleted_at: NULL
*************************** 2. row ***************************
id: 2
group: apps
version: v1
resource: deployments
kind: Deployment
cluster: dce5-member
namespace: kube-system
name: coredns
owner_uid:
uid: 4fab46a9-5cc2-469a-b01d-f62f2ac6e586
resource_version: 39760205
object: {"kind": "Deployment", "spec": {"replicas": 2, "selector": {"matchLabels": {"k8s-app": "kube-dns"}}, "strategy": {"type": "RollingUpdate", "rollingUpdate": {"maxSurge": "10%", "maxUnavailable": 0}}, "template": {"spec": {"volumes": [{"name": "config-volume", "configMap": {"name": "coredns", "items": [{"key": "Corefile", "path": "Corefile"}], "defaultMode": 420}}], "affinity": {"nodeAffinity": {"preferredDuringSchedulingIgnoredDuringExecution": [{"weight": 100, "preference": {"matchExpressions": [{"key": "node-role.kubernetes.io/control-plane", "values": [""], "operator": "In"}]}}]}, "podAntiAffinity": {"requiredDuringSchedulingIgnoredDuringExecution": [{"topologyKey": "kubernetes.io/hostname", "labelSelector": {"matchLabels": {"k8s-app": "kube-dns"}}}]}}, "dnsPolicy": "Default", "containers": [{"args": ["-conf", "/etc/coredns/Corefile"], "name": "coredns", "image": "k8s-gcr.m.daocloud.io/coredns/coredns:v1.8.6", "ports": [{"name": "dns", "protocol": "UDP", "containerPort": 53}, {"name": "dns-tcp", "protocol": "TCP", "containerPort": 53}, {"name": "metrics", "protocol": "TCP", "containerPort": 9153}], "resources": {"limits": {"memory": "300Mi"}, "requests": {"cpu": "100m", "memory": "70Mi"}}, "volumeMounts": [{"name": "config-volume", "mountPath": "/etc/coredns"}], "livenessProbe": {"httpGet": {"path": "/health", "port": 8080, "scheme": "HTTP"}, "periodSeconds": 10, "timeoutSeconds": 5, "failureThreshold": 10, "successThreshold": 1}, "readinessProbe": {"httpGet": {"path": "/ready", "port": 8181, "scheme": "HTTP"}, "periodSeconds": 10, "timeoutSeconds": 5, "failureThreshold": 10, "successThreshold": 1}, "imagePullPolicy": "IfNotPresent", "securityContext": {"capabilities": {"add": ["NET_BIND_SERVICE"], "drop": ["all"]}, "readOnlyRootFilesystem": true, "allowPrivilegeEscalation": false}, "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File"}], "tolerations": [{"key": "node-role.kubernetes.io/master", "effect": "NoSchedule"}, {"key": "node-role.kubernetes.io/control-plane", "effect": "NoSchedule"}], "nodeSelector": {"kubernetes.io/os": "linux"}, "restartPolicy": "Always", "schedulerName": "default-scheduler", "serviceAccount": "coredns", "securityContext": {}, "priorityClassName": "system-cluster-critical", "serviceAccountName": "coredns", "terminationGracePeriodSeconds": 30}, "metadata": {"labels": {"k8s-app": "kube-dns"}, "annotations": {"createdby": "kubespray", "seccomp.security.alpha.kubernetes.io/pod": "runtime/default"}, "creationTimestamp": null}}, "revisionHistoryLimit": 10, "progressDeadlineSeconds": 600}, "status": {"replicas": 2, "conditions": [{"type": "Progressing", "reason": "NewReplicaSetAvailable", "status": "True", "message": "ReplicaSet \"coredns-58795d59cc\" has successfully progressed.", "lastUpdateTime": "2022-10-29T07:37:23Z", "lastTransitionTime": "2022-10-29T07:37:03Z"}, {"type": "Available", "reason": "MinimumReplicasAvailable", "status": "True", "message": "Deployment has minimum availability.", "lastUpdateTime": "2023-02-17T02:33:47Z", "lastTransitionTime": "2023-02-17T02:33:47Z"}], "readyReplicas": 2, "updatedReplicas": 2, "availableReplicas": 2, "observedGeneration": 2}, "metadata": {"uid": "4fab46a9-5cc2-469a-b01d-f62f2ac6e586", "name": "coredns", "labels": {"k8s-app": "kube-dns", "kubernetes.io/name": "coredns", "addonmanager.kubernetes.io/mode": "Reconcile"}, "namespace": "kube-system", "generation": 2, "annotations": {"deployment.kubernetes.io/revision": "1", "shadow.clusterpedia.io/cluster-name": "dce5-member"}, "resourceVersion": "39760205", "creationTimestamp": "2022-10-29T07:37:02Z"}, "apiVersion": "apps/v1"}
created_at: 2022-10-29 07:37:02.000
synced_at: 2023-03-20 06:06:44.698
deleted_at: NULL
2 rows in set (0.00 sec)
[root@master01 ~/clusterpedia/examples]# kubectl get pediacluster -o wide
NAME READY VERSION APISERVER VALIDATED SYNCHRORUNNING CLUSTERHEALTHY
dce4-010 True v1.18.20 https://10.29.16.27:16443 Validated Running Healthy
dce5-member True v1.24.7 https://10.29.15.79:6443 Validated Running Healthy
# 检查 mysql 数据
mysql> SELECT * FROM clusterpedia.resources where cluster = 'dce4-010' limit 1 \G
*************************** 1. row ***************************
id: 54
group: apps
version: v1
resource: deployments
kind: Deployment
cluster: dce4-010
namespace: kube-system
name: dce-prometheus
owner_uid:
uid: cf53ad44-856d-4e3f-8129-113fa42af534
resource_version: 17190
object: {"kind": "Deployment", "spec": {"replicas": 1, "selector": {"matchLabels": {"k8s-app": "dce-prometheus"}}, "strategy": {"type": "RollingUpdate", "rollingUpdate": {"maxSurge": 1, "maxUnavailable": 2}}, "template": {"spec": {"volumes": [{"name": "dce-metrics-server-secrets", "secret": {"secretName": "dce-prometheus", "defaultMode": 420}}, {"name": "config", "configMap": {"name": "dce-prometheus", "defaultMode": 420}}, {"name": "dce-certs", "hostPath": {"path": "/etc/daocloud/dce/certs", "type": ""}}], "affinity": {"nodeAffinity": {"requiredDuringSchedulingIgnoredDuringExecution": {"nodeSelectorTerms": [{"matchExpressions": [{"key": "node-role.kubernetes.io/master", "operator": "Exists"}]}]}}, "podAntiAffinity": {"requiredDuringSchedulingIgnoredDuringExecution": [{"topologyKey": "kubernetes.io/hostname", "labelSelector": {"matchExpressions": [{"key": "k8s-app", "values": ["dce-prometheus"], "operator": "In"}]}}]}}, "dnsPolicy": "ClusterFirst", "containers": [{"name": "dce-metrics-server", "image": "10.29.140.12/kube-system/dce-metrics-server:0.3.0", "ports": [{"name": "https", "protocol": "TCP", "containerPort": 6443}, {"name": "http", "protocol": "TCP", "containerPort": 8080}, {"name": "metrics", "protocol": "TCP", "containerPort": 9091}], "command": ["/usr/bin/server", "--hpa-version=v2beta1", "--secure-port=6443", "--tls-cert-file=/srv/kubernetes/server.cert", "--tls-private-key-file=/srv/kubernetes/server.key", "--prometheus-url=http://127.0.0.1:9090"], "resources": {"limits": {"cpu": "50m", "memory": "50Mi"}, "requests": {"cpu": "25m", "memory": "25Mi"}}, "volumeMounts": [{"name": "dce-metrics-server-secrets", "readOnly": true, "mountPath": "/srv/kubernetes/"}], "imagePullPolicy": "IfNotPresent", "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File"}, {"args": ["--config.file=/prometheus/config/config.yml", "--storage.tsdb.path=/prometheus/data", "--web.listen-address=0.0.0.0:9090", "--storage.tsdb.retention.time=7d", "--web.enable-lifecycle"], "name": "dce-prometheus", "image": "10.29.140.12/kube-system/dce-prometheus:4.0.10-35699", "ports": [{"name": "web", "protocol": "TCP", "containerPort": 9090}], "command": ["/usr/local/bin/prometheus"], "resources": {"limits": {"cpu": "400m", "memory": "500Mi"}, "requests": {"cpu": "100m", "memory": "250Mi"}}, "volumeMounts": [{"name": "config", "mountPath": "/prometheus/config/"}, {"name": "dce-certs", "readOnly": true, "mountPath": "/etc/daocloud/dce/certs"}], "imagePullPolicy": "IfNotPresent", "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File"}], "tolerations": [{"key": "node-role.kubernetes.io/master", "effect": "NoSchedule"}], "restartPolicy": "Always", "schedulerName": "default-scheduler", "serviceAccount": "dce-prometheus", "securityContext": {}, "priorityClassName": "system-cluster-critical", "serviceAccountName": "dce-prometheus", "terminationGracePeriodSeconds": 30}, "metadata": {"name": "dce-prometheus", "labels": {"k8s-app": "dce-prometheus"}, "namespace": "kube-system", "creationTimestamp": null}}, "revisionHistoryLimit": 10, "progressDeadlineSeconds": 600}, "status": {"replicas": 1, "conditions": [{"type": "Available", "reason": "MinimumReplicasAvailable", "status": "True", "message": "Deployment has minimum availability.", "lastUpdateTime": "2023-01-08T11:51:58Z", "lastTransitionTime": "2023-01-08T11:51:58Z"}, {"type": "Progressing", "reason": "NewReplicaSetAvailable", "status": "True", "message": "ReplicaSet \"dce-prometheus-59b9468478\" has successfully progressed.", "lastUpdateTime": "2023-01-08T13:11:43Z", "lastTransitionTime": "2023-01-08T13:11:43Z"}], "readyReplicas": 1, "updatedReplicas": 1, "availableReplicas": 1, "observedGeneration": 2}, "metadata": {"uid": "cf53ad44-856d-4e3f-8129-113fa42af534", "name": "dce-prometheus", "labels": {"k8s-app": "dce-prometheus", "app.kubernetes.io/managed-by": "Helm"}, "selfLink": "/apis/apps/v1/namespaces/kube-system/deployments/dce-prometheus", "namespace": "kube-system", "generation": 2, "annotations": {"meta.helm.sh/release-name": "dce-components", "meta.helm.sh/release-namespace": "kube-system", "deployment.kubernetes.io/revision": "1", "shadow.clusterpedia.io/cluster-name": "dce4-010", "dce-metrics-server.daocloud.io/collector-config": "{\"kind\": \"DCE-Metrics-Server\", \"parameters\": {\"address\": \"\"}}"}, "resourceVersion": "17190", "creationTimestamp": "2023-01-08T11:51:58Z"}, "apiVersion": "apps/v1"}
created_at: 2023-01-08 11:51:58.000
synced_at: 2023-03-20 06:23:59.262
deleted_at: NULL
1 row in set (0.00 sec)
ClusterPedia 对接 k8s 集群
1. 接入集群中创建 clusterrole/clusterrolebinding/serviceaccout/secret
# 创建 cluserpedia-RBAC
[root@master01 clusterpedia]# vi clusterpedia_synchro_rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: clusterpedia-synchro
rules:
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
- nonResourceURLs:
- '*'
verbs:
- '*'
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: clusterpedia-synchro
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterpedia-synchro
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: clusterpedia-synchro
subjects:
- kind: ServiceAccount
name: clusterpedia-synchro
namespace: default
---
[root@master01 clusterpedia]# kubectl apply -f clusterpedia_synchro_rbac.yaml
clusterrole.rbac.authorization.k8s.io/clusterpedia-synchro created
serviceaccount/clusterpedia-synchro created
clusterrolebinding.rbac.authorization.k8s.io/clusterpedia-synchro created
# 查看 sa/secret
[root@master01 clusterpedia]# kubectl get sa
NAME SECRETS AGE
clusterpedia-synchro 1 9s
default 1 2d14h
[root@master01 clusterpedia]# kubectl get secret
NAME TYPE DATA AGE
clusterpedia-synchro-token-bjj5m kubernetes.io/service-account-token 3 14s
default-token-jxtkh kubernetes.io/service-account-token 3 2d14h
sh.helm.release.v1.dao-2048.v1 helm.sh/release.v1 1 43h
# 获取 caData/toeknData
[root@master01 clusterpedia]# kubectl get secret clusterpedia-synchro-token-bjj5m -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUdNRENDQkJpZ0F3SUJBZ0lKQU1CVkpiU3RXZ0JKTUEwR0NTcUdTSWIzRFFFQkN3VUFNRzB4Q3pBSkJnTlYKQkFZVEFrTk9NUkV3RHdZRFZRUUlFd2hUYUdGdVoyaGhhVEVSTUE4R0ExVUVCeE1JVTJoaGJtZG9ZV2t4RVRBUApCZ05WQkFvVENFUmhiME5zYjNWa01SRXdEd1lEVlFRTEV3aEVZVzlEYkc5MVpERVNNQkFHQTFVRUF4TUpiRzlqCllXeG9iM04wTUI0WERURTNNRFV4TURBMk16UTFPVm9YRFRJM01EVXdPREEyTXpRMU9Wb3diVEVMTUFrR0ExVUUKQmhNQ1EwNHhFVEFQQmdOVkJBZ1RDRk5vWVc1bmFHRnBNUkV3RHdZRFZRUUhFd2hUYUdGdVoyaGhhVEVSTUE4RwpBMVVFQ2hNSVJHRnZRMnh2ZFdReEVUQVBCZ05WQkFzVENFUmhiME5zYjNWa01SSXdFQVlEVlFRREV3bHNiMk5oCmJHaHZjM1F3Z2dJaU1BMEdDU3FHU0liM0RRRUJBUVVBQTRJQ0R3QXdnZ0lLQW9JQ0FRQzFab3laTFdIc2ozVGMKN09PejRxZUlDa1J0NTFOM1lJVkNqc2cxTnA1ZllLQWRzQStNRktWN3VWYnc5djcrbmZpUEwySjFoeGx1MzF2UAo0Zlliamp5ZlAyd0w0RXlOeVBxYjlhNG5nRWZxZmhxOUo1QitCTWd2cTNSMFNCQ05YTTE2Mm1pSzBuUmlSU1pUCmlvSTY0S29wdjFvWXFsaW5mR2RzcnlPdHM1UUpYMFN1TEZKekhIK1hpa3dzQVJSOWNjRkpGajZTazJHODllZkUKZ1FaY2hvZThnd3BqSW9zK2w4S1BEVkxEdDFzeVM4MUVZaFpLZXpSWmZVWmdyb0VhZU5iRVdmNjg5NGpRQUdhNwpsbklpL0RCTWJXYjcwN1FybG9mYkt4ZWorSE9OUHdzai9uZFB5VjM3SFVNOG5iMFM3eTJ5V3A0dFJVdm5QQ2R4CkRWUjlyYzRMUEhGbjB5SUZtTmRrNTU5Q3BTS01meHBoTjNzbkZXdEsxZG1ieis3R2svUlpwRi96VkYvMnpEM2UKRkVTWmVZOU9ucUt0Wk1VZlR4dy9oZW83dC9OZHFNdU50TVJJY294SHREdzZIU0pibHhwTkxIcnh5M0l3Z3lUZApBZVMvR3Rjblg5T3hYRHFWUDJMN1RENlVuK05GRVBSbHhqTi9EVzRRS1gvdGg4T2FNTU9PekVZdlhTUUl2TVg4ClRTb2x5c0pBNGhrR0crM09YVUNENzFwS0N0TTVTU2lPTzNYc0xQdm1YYWt6NXpNd0p3cXBPUyt6M01LM0s4K08KRFBOcld1ZExNcm40VVduRkx2SzJhakx3Q2xTYk5Rdzk0K0I0eVdqVkR5a21hNGpkUm1QSkVvTVBRN3NNTGRISQpHbHdEOWkxMGdpaUpiR3haclp1a0pIUlMvMzFQS3dJREFRQUJvNEhTTUlIUE1CMEdBMVVkRGdRV0JCUlZsajNlCk1mWk1KNGVnSEdGbHRmcVAwSWxBNVRDQm53WURWUjBqQklHWE1JR1VnQlJWbGozZU1mWk1KNGVnSEdGbHRmcVAKMElsQTVhRnhwRzh3YlRFTE1Ba0dBMVVFQmhNQ1EwNHhFVEFQQmdOVkJBZ1RDRk5vWVc1bmFHRnBNUkV3RHdZRApWUVFIRXdoVGFHRnVaMmhoYVRFUk1BOEdBMVVFQ2hNSVJHRnZRMnh2ZFdReEVUQVBCZ05WQkFzVENFUmhiME5zCmIzVmtNUkl3RUFZRFZRUURFd2xzYjJOaGJHaHZjM1NDQ1FEQVZTVzByVm9BU1RBTUJnTlZIUk1FQlRBREFRSC8KTUEwR0NTcUdTSWIzRFFFQkN3VUFBNElDQVFBYjRnenI1dXhLZEdWTjBRck9meWNvS1BiTDltN0hsazlYcDFOYgpiVXQzQ0FnbHhDemc0NkVqOTNZK2dOZHF6SmNoU2o3M3RIYmRMYzY0Zlh1R3Riemp4RU55aUcwTlFVUXlVdEVBCjFKUmhJY2RSaG1uZVpzNGNNdm9OVTVmbU4yRllVZGFFT3JoUkRHd3pzQks1MDgzVXNDRVBaelhxV1FVRUpWNlQKVTVoMmJQbHUxT3ZwdlhpQ0hENG5kOVVSa21pZkdGSWZHWk16enRjay9MQnVEWE4wdUltSW1mSXluM0hkK2FNRQpZaTk1N1NjVFhuSXVkK0dtOVRkZjZSRW14Z0pkQVhwUmZVRm9UOVRBVURIcFhGcTlHcW4xSmlHUlJxRWFVbWZ6Cmp5ek5DMXowQmtMK2JkOG5LTGpseURhMVdaNHRuYU1yMGZ0TFp4dldYeEJ0NjBDcVM2Rk1SekhTUHpPRUNUSjQKb1g4WjlsQnhBYkx3bTBjSUx2K2JHdGxOREwzbGlxK3h1ck5OQjJsOHdFcndNUTdoUEVFeG1wQ0VJRGcxNVBCQgpKb3A0bEpxNTlwVms4dytNbzJzR3psMVVrSE5yOUdRbi9MZ3pCNDFrdTEzcll4dCthWFN0eTYzVUM1dUc5SEtlCldmY2U1RXE4YkcyZmZlME45c2xLdmc3K0FMNFdiNEtFVjk5U2VmY0pqL3JrcitiN2xrbERBZjl5cVJLNzdwMHkKZkZLT3dtSTVadlVSQW9BZDRBN1R4cXMvNjRNUjNWREhlMWZiMzVUU2g5RjZhSm0wVWNkQ2I3MGcwUG01bERoRwpOTTEyNjlKUHUxNVQxRHNHbWxUVGxSOXNHUFR4QnM0QlkvRDVFdDNRdFYvS2tIWTVDSW9RZnk3SXNCdWdyeU1rCjZ1UmZOQT09Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K
namespace: ZGVmYXVsdA==
token: ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNkltUnVibTFSYUVkbVdtTlBUR2hzZHpVd1dEZE9UVWhhZFdKdlJVZHpaMDV2Y1hOcmFqTnNTM1ZVYUhNaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUprWldaaGRXeDBJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpXTnlaWFF1Ym1GdFpTSTZJbU5zZFhOMFpYSndaV1JwWVMxemVXNWphSEp2TFhSdmEyVnVMV0pxYWpWdElpd2lhM1ZpWlhKdVpYUmxjeTVwYnk5elpYSjJhV05sWVdOamIzVnVkQzl6WlhKMmFXTmxMV0ZqWTI5MWJuUXVibUZ0WlNJNkltTnNkWE4wWlhKd1pXUnBZUzF6ZVc1amFISnZJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpYSjJhV05sTFdGalkyOTFiblF1ZFdsa0lqb2lOakZoWVRZMk16VXRPV1UwWlMwME9UQmpMV0ZtTjJJdFpEUTFaVGs0WkdNME9XRmxJaXdpYzNWaUlqb2ljM2x6ZEdWdE9uTmxjblpwWTJWaFkyTnZkVzUwT21SbFptRjFiSFE2WTJ4MWMzUmxjbkJsWkdsaExYTjVibU5vY204aWZRLkljVnNmcEdRVDFfUC1DM1BZRkZ4TU95dzIzdk10Ykw5Z2NNMVc2bnJRcWt1OE95dl9GaHFBLWxoV2dQXzRZRW83S0o0NU5qeGNlTDZtZkdub1BSX2NnaHoxVjVZSEZhUFhVVTFBZDl4NjA0bnlzTHFYemdCLUVKdEE4MjJZX0tHUWE3RHVuWktDUHJ2Y2NybVZiOS1NcEpoYjFfVmJTVDNpbWpiSDFSRnRHWnM1MllyU1ZNWmZqb0luR3BhemRQTzA3dFFTTmpXc0NUaTdlcW42cFIwV2VTOUZCYV83MXdDX1ZTdkRpYWZsRnRqT3ZNamdYbmc4OXJjVW8zWlNMaXd5aGcwYnhHOXZSWXRxTXp1X0hFa3JxTXJMTV9RaGJSc0lrWTJmTnlaN2hBY2VrRXl4eWJQWkpYVzV0Z3NBZ2Jka0RmOUJQS2NDWnJhWHdhdVdBX0dIZw==
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: clusterpedia-synchro
kubernetes.io/service-account.uid: 61aa6635-9e4e-490c-af7b-d45e98dc49ae
creationTimestamp: "2023-01-11T02:07:32Z"
name: clusterpedia-synchro-token-bjj5m
namespace: default
resourceVersion: "1032452"
selfLink: /api/v1/namespaces/default/secrets/clusterpedia-synchro-token-bjj5m
uid: 52f797f6-9c86-4ac4-935e-7d9ce5f87370
type: kubernetes.io/service-account-token
2. cluserpedia 组件节点中创建 pediacluser 实例
# 创建 pediacluser 配置文件
[root@master01 ~]# cat clusterpedia/examples/pediacluster-dce4010.yaml
apiVersion: cluster.clusterpedia.io/v1alpha2
kind: PediaCluster
metadata:
name: cluster2-dce4010
spec:
apiserver: "https://10.29.16.27:16443"
caData: "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUdNRENDQkJpZ0F3SUJBZ0lKQU1CVkpiU3RXZ0JKTUEwR0NTcUdTSWIzRFFFQkN3VUFNRzB4Q3pBSkJnTlYKQkFZVEFrTk9NUkV3RHdZRFZRUUlFd2hUYUdGdVoyaGhhVEVSTUE4R0ExVUVCeE1JVTJoaGJtZG9ZV2t4RVRBUApCZ05WQkFvVENFUmhiME5zYjNWa01SRXdEd1lEVlFRTEV3aEVZVzlEYkc5MVpERVNNQkFHQTFVRUF4TUpiRzlqCllXeG9iM04wTUI0WERURTNNRFV4TURBMk16UTFPVm9YRFRJM01EVXdPREEyTXpRMU9Wb3diVEVMTUFrR0ExVUUKQmhNQ1EwNHhFVEFQQmdOVkJBZ1RDRk5vWVc1bmFHRnBNUkV3RHdZRFZRUUhFd2hUYUdGdVoyaGhhVEVSTUE4RwpBMVVFQ2hNSVJHRnZRMnh2ZFdReEVUQVBCZ05WQkFzVENFUmhiME5zYjNWa01SSXdFQVlEVlFRREV3bHNiMk5oCmJHaHZjM1F3Z2dJaU1BMEdDU3FHU0liM0RRRUJBUVVBQTRJQ0R3QXdnZ0lLQW9JQ0FRQzFab3laTFdIc2ozVGMKN09PejRxZUlDa1J0NTFOM1lJVkNqc2cxTnA1ZllLQWRzQStNRktWN3VWYnc5djcrbmZpUEwySjFoeGx1MzF2UAo0Zlliamp5ZlAyd0w0RXlOeVBxYjlhNG5nRWZxZmhxOUo1QitCTWd2cTNSMFNCQ05YTTE2Mm1pSzBuUmlSU1pUCmlvSTY0S29wdjFvWXFsaW5mR2RzcnlPdHM1UUpYMFN1TEZKekhIK1hpa3dzQVJSOWNjRkpGajZTazJHODllZkUKZ1FaY2hvZThnd3BqSW9zK2w4S1BEVkxEdDFzeVM4MUVZaFpLZXpSWmZVWmdyb0VhZU5iRVdmNjg5NGpRQUdhNwpsbklpL0RCTWJXYjcwN1FybG9mYkt4ZWorSE9OUHdzai9uZFB5VjM3SFVNOG5iMFM3eTJ5V3A0dFJVdm5QQ2R4CkRWUjlyYzRMUEhGbjB5SUZtTmRrNTU5Q3BTS01meHBoTjNzbkZXdEsxZG1ieis3R2svUlpwRi96VkYvMnpEM2UKRkVTWmVZOU9ucUt0Wk1VZlR4dy9oZW83dC9OZHFNdU50TVJJY294SHREdzZIU0pibHhwTkxIcnh5M0l3Z3lUZApBZVMvR3Rjblg5T3hYRHFWUDJMN1RENlVuK05GRVBSbHhqTi9EVzRRS1gvdGg4T2FNTU9PekVZdlhTUUl2TVg4ClRTb2x5c0pBNGhrR0crM09YVUNENzFwS0N0TTVTU2lPTzNYc0xQdm1YYWt6NXpNd0p3cXBPUyt6M01LM0s4K08KRFBOcld1ZExNcm40VVduRkx2SzJhakx3Q2xTYk5Rdzk0K0I0eVdqVkR5a21hNGpkUm1QSkVvTVBRN3NNTGRISQpHbHdEOWkxMGdpaUpiR3haclp1a0pIUlMvMzFQS3dJREFRQUJvNEhTTUlIUE1CMEdBMVVkRGdRV0JCUlZsajNlCk1mWk1KNGVnSEdGbHRmcVAwSWxBNVRDQm53WURWUjBqQklHWE1JR1VnQlJWbGozZU1mWk1KNGVnSEdGbHRmcVAKMElsQTVhRnhwRzh3YlRFTE1Ba0dBMVVFQmhNQ1EwNHhFVEFQQmdOVkJBZ1RDRk5vWVc1bmFHRnBNUkV3RHdZRApWUVFIRXdoVGFHRnVaMmhoYVRFUk1BOEdBMVVFQ2hNSVJHRnZRMnh2ZFdReEVUQVBCZ05WQkFzVENFUmhiME5zCmIzVmtNUkl3RUFZRFZRUURFd2xzYjJOaGJHaHZjM1NDQ1FEQVZTVzByVm9BU1RBTUJnTlZIUk1FQlRBREFRSC8KTUEwR0NTcUdTSWIzRFFFQkN3VUFBNElDQVFBYjRnenI1dXhLZEdWTjBRck9meWNvS1BiTDltN0hsazlYcDFOYgpiVXQzQ0FnbHhDemc0NkVqOTNZK2dOZHF6SmNoU2o3M3RIYmRMYzY0Zlh1R3Riemp4RU55aUcwTlFVUXlVdEVBCjFKUmhJY2RSaG1uZVpzNGNNdm9OVTVmbU4yRllVZGFFT3JoUkRHd3pzQks1MDgzVXNDRVBaelhxV1FVRUpWNlQKVTVoMmJQbHUxT3ZwdlhpQ0hENG5kOVVSa21pZkdGSWZHWk16enRjay9MQnVEWE4wdUltSW1mSXluM0hkK2FNRQpZaTk1N1NjVFhuSXVkK0dtOVRkZjZSRW14Z0pkQVhwUmZVRm9UOVRBVURIcFhGcTlHcW4xSmlHUlJxRWFVbWZ6Cmp5ek5DMXowQmtMK2JkOG5LTGpseURhMVdaNHRuYU1yMGZ0TFp4dldYeEJ0NjBDcVM2Rk1SekhTUHpPRUNUSjQKb1g4WjlsQnhBYkx3bTBjSUx2K2JHdGxOREwzbGlxK3h1ck5OQjJsOHdFcndNUTdoUEVFeG1wQ0VJRGcxNVBCQgpKb3A0bEpxNTlwVms4dytNbzJzR3psMVVrSE5yOUdRbi9MZ3pCNDFrdTEzcll4dCthWFN0eTYzVUM1dUc5SEtlCldmY2U1RXE4YkcyZmZlME45c2xLdmc3K0FMNFdiNEtFVjk5U2VmY0pqL3JrcitiN2xrbERBZjl5cVJLNzdwMHkKZkZLT3dtSTVadlVSQW9BZDRBN1R4cXMvNjRNUjNWREhlMWZiMzVUU2g5RjZhSm0wVWNkQ2I3MGcwUG01bERoRwpOTTEyNjlKUHUxNVQxRHNHbWxUVGxSOXNHUFR4QnM0QlkvRDVFdDNRdFYvS2tIWTVDSW9RZnk3SXNCdWdyeU1rCjZ1UmZOQT09Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K"
tokenData: "ZXlKaGJHY2lPaUpTVXpJMU5pSXNJbXRwWkNJNkltUnVibTFSYUVkbVdtTlBUR2hzZHpVd1dEZE9UVWhhZFdKdlJVZHpaMDV2Y1hOcmFqTnNTM1ZVYUhNaWZRLmV5SnBjM01pT2lKcmRXSmxjbTVsZEdWekwzTmxjblpwWTJWaFkyTnZkVzUwSWl3aWEzVmlaWEp1WlhSbGN5NXBieTl6WlhKMmFXTmxZV05qYjNWdWRDOXVZVzFsYzNCaFkyVWlPaUprWldaaGRXeDBJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpXTnlaWFF1Ym1GdFpTSTZJbU5zZFhOMFpYSndaV1JwWVMxemVXNWphSEp2TFhSdmEyVnVMV0pxYWpWdElpd2lhM1ZpWlhKdVpYUmxjeTVwYnk5elpYSjJhV05sWVdOamIzVnVkQzl6WlhKMmFXTmxMV0ZqWTI5MWJuUXVibUZ0WlNJNkltTnNkWE4wWlhKd1pXUnBZUzF6ZVc1amFISnZJaXdpYTNWaVpYSnVaWFJsY3k1cGJ5OXpaWEoyYVdObFlXTmpiM1Z1ZEM5elpYSjJhV05sTFdGalkyOTFiblF1ZFdsa0lqb2lOakZoWVRZMk16VXRPV1UwWlMwME9UQmpMV0ZtTjJJdFpEUTFaVGs0WkdNME9XRmxJaXdpYzNWaUlqb2ljM2x6ZEdWdE9uTmxjblpwWTJWaFkyTnZkVzUwT21SbFptRjFiSFE2WTJ4MWMzUmxjbkJsWkdsaExYTjVibU5vY204aWZRLkljVnNmcEdRVDFfUC1DM1BZRkZ4TU95dzIzdk10Ykw5Z2NNMVc2bnJRcWt1OE95dl9GaHFBLWxoV2dQXzRZRW83S0o0NU5qeGNlTDZtZkdub1BSX2NnaHoxVjVZSEZhUFhVVTFBZDl4NjA0bnlzTHFYemdCLUVKdEE4MjJZX0tHUWE3RHVuWktDUHJ2Y2NybVZiOS1NcEpoYjFfVmJTVDNpbWpiSDFSRnRHWnM1MllyU1ZNWmZqb0luR3BhemRQTzA3dFFTTmpXc0NUaTdlcW42cFIwV2VTOUZCYV83MXdDX1ZTdkRpYWZsRnRqT3ZNamdYbmc4OXJjVW8zWlNMaXd5aGcwYnhHOXZSWXRxTXp1X0hFa3JxTXJMTV9RaGJSc0lrWTJmTnlaN2hBY2VrRXl4eWJQWkpYVzV0Z3NBZ2Jka0RmOUJQS2NDWnJhWHdhdVdBX0dIZw=="
syncResources:
- group: apps
resources:
- deployments
- group: ""
resources:
- pods
- configmaps
- group: cert-manager.io
versions:
- v1
resources:
- certificates
# caData / tokenData 均来自接入集群中 clusterpedia-synchro-token-bjj5m Secret。另外 1.24 以后版本的 k8s,在创建 sa 后不会自动创建对应的 secret
# 查看 pediacluser 列表
[root@master01 ~]# kubectl get pediacluster
NAME READY VERSION APISERVER
cluster1-maweibing True v1.24.7 https://10.29.15.79:6443
cluster2-dce4010 True v1.18.20 https://10.29.16.27:16443
# 通过 -o yaml 可以查看资源的同步状态
3. cluserpedia 组件节点中为 kubectl 生成集群快捷访问配置
# 备份 kubeconfig 文件
[root@master01 ~]# cp .kube/config .kube/config_bak
# 追加 pediacluser 配置信息到 kubeconfig
[root@master01 ~]# bash gen_clusterconfig.sh
Current Context: kubernetes-admin@cluster.local
Current Cluster: cluster.local
Server: https://127.0.0.1:6443
TLS Server Name:
Insecure Skip TLS Verify:
Certificate Authority:
Certificate Authority Data: ***
Cluster "clusterpedia" set.
Cluster "dce4-010" set.
Cluster "dce5-member" set.
# 执行后 .kube/config 新增 3 个 cluster 配置,分别是 get pediacluster 集群信息、和 1 个 clusterpedia <这个是属于一个多集群的概念,通过它可以检索所有集群的资源信息>
4. cluserpedia 组件节点中使用 kubectl 检查集群资源 更多检索技巧
# 检索所有 pediacluster 所同步的资源信息
[root@master01 ~]# kubectl --cluster clusterpedia api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
configmaps cm v1 true ConfigMap
pods po v1 true Pod
deployments deploy apps/v1 true Deployment
# 检索所有 pediacluster 资源
[root@master01 ~]# kubectl --cluster clusterpedia get deployments.apps -A
NAMESPACE CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE
calico-apiserver cluster1-maweibing calico-apiserver 1/1 1 1 73d
clusterpedia-system cluster1-maweibing clusterpedia-apiserver 1/1 1 1 33d
clusterpedia-system cluster1-maweibing clusterpedia-clustersynchro-manager 1/1 1 1 33d
dce-system cluster2-dce4010 dce-system-dnsservice 1/1 1 1 47h
dce-system cluster2-dce4010 dce-system-loadbalancermanager 1/1 1 1 44h
dce-system cluster2-dce4010 dce-system-uds 1/1 1 1 2d14h
default cluster2-dce4010 dao-2048 1/1 1 1 43h
kube-system cluster2-dce4010 calico-kube-controllers 1/1 1 1 2d14h
kube-system cluster2-dce4010 coredns-coredns 2/2 2 2 47h
kube-system cluster2-dce4010 dce-chart-manager 1/1 1 1 2d14h
kube-system cluster2-dce4010 dce-clair 1/1 1 1 2d14h
# 检索指定集群和租户信息
[root@master01 ~]# kubectl --cluster cluster2-dce4010 get deployments.apps -n kube-system
CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE
cluster2-dce4010 calico-kube-controllers 1/1 1 1 2d14h
cluster2-dce4010 coredns-coredns 2/2 2 2 47h
cluster2-dce4010 dce-chart-manager 1/1 1 1 2d14h
cluster2-dce4010 dce-clair 1/1 1 1 2d14h
cluster2-dce4010 dce-controller 1/1 1 1 2d14h
cluster2-dce4010 dce-core-keepalived 1/1 1 1 2d14h
cluster2-dce4010 dce-prometheus 1/1 1 1 2d14h
cluster2-dce4010 dce-registry 1/1 1 1 2d14h
cluster2-dce4010 dce-uds-daocloud-dlocal-local-1-0-0-csi-controller 1/1 1 1 37h
cluster2-dce4010 dce-uds-failover-assistant 1/1 1 1 2d14h
cluster2-dce4010 dce-uds-policy-controller 1/1 1 1 2d14h
cluster2-dce4010 dce-uds-snapshot-controller 1/1 1 1 2d14h
cluster2-dce4010 dce-uds-storage-server 1/1 1 1 2d14h
cluster2-dce4010 lb01-ingress1 1/1 1 1 44h
cluster2-dce4010 lb01-ingress2 1/1 1 1 44h
cluster2-dce4010 lb01-keepalived 2/2 2 2 44h
cluster2-dce4010 metrics-server 1/1 1 1 2d14h
[root@master01 ~]# kubectl --cluster cluster2-dce4010 get pod -o wide -n kube-system
CLUSTER NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cluster2-dce4010 calico-kube-controllers-789ff96b77-lwvb6 1/1 Running 0 2d14h 10.29.16.27 master01 <none> <none>
cluster2-dce4010 calico-node-28xtc 1/1 Running 0 2d13h 10.29.16.33 worker02 <none> <none>
cluster2-dce4010 calico-node-bc8b7 1/1 Running 0 2d14h 10.29.16.27 master01 <none> <none>
cluster2-dce4010 calico-node-bs9fh 1/1 Running 0 2d13h 10.29.16.30 worker01 <none> <none>
cluster2-dce4010 calico-node-dbz46 1/1 Running 0 37h 10.29.16.39 worker03 <none> <none>
cluster2-dce4010 coredns-coredns-5b879856b7-lnj4g 1/1 Running 0 47h 172.28.2.130 worker01 <none> <none>
cluster2-dce4010 coredns-coredns-5b879856b7-mjjcl 1/1 Running 0 47h 172.28.48.1 worker02 <none> <none>
cluster2-dce4010 dce-chart-manager-795cdfd86b-6dhnv 1/1 Running 0 2d14h 172.28.213.70 master01 <none> <none>
Prometheus
Prometheus 是什么?
Prometheus 是一个开源系统监控和告警工具,目前是一个独立开源的项目,2016年之后加入 CNCF。其通过指标搜集性能数并存为时间序列数据。
特点
- 具有指标、标签键值对、时间序列数据的多维数据模型
- 具有 PromQl 灵活的查询语言
- 单节点部署数据落盘、也可使用远端存储存放监控数据
- 通过 HTTP 的 pull 搜集监控数据(默认)
- 通过 pushgateway 中间 push 数据到 Prometheus Server
- 多种服务发现模式(动态/静态)
- 内嵌图形和支持 Grafana 对性能数据进行展示
Metrics 是什么?
- web 服务器下,你的指标可能是请求时间、成功/失败率.等
- db 服务器,你的指标可能是读/写io、延迟.等
架构

组件
- Prometheus Server 负责搜集和存储 pull/push 模式的数据
- PromQL
- Rule
- ServiceDiscovery
- 动态
- 静态
- Exporter 负责通过 metrics 采集应用/主机上的性能数据
- Pushgateway 负责将短时间/间歇性运行的 exporter 的数据 push 给 Prometheus Server
- Alertmanager 负责将触发的告警条目通过 mail、企业微信等多种方式发送给组织进行警示
- Grafana 负责对接Prometheus 数据源,通过各种模型数据和 Query 将数据以友好形式展示出来
场景
- Docker、Kubernetes
- Linux
- 应用系统 (需要具备开发能力,可根据应用自定义 metrics)
- Windows (不太友好)
VictoriaMetrics 安装
安装 anisible 组件
# 使用 dnf 安装 epel-release 源
dnf install epel-release
# 只手使用 dnf 包管理器,安装 ansibel
dnf install -y ansible
# 查看安装后版本
ansible --version
ansible [core 2.14.17]
config file = /etc/ansible/ansible.cfg
configured module search path = ['/root/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.9/site-packages/ansible
ansible collection location = /root/.ansible/collections:/usr/share/ansible/collections
executable location = /usr/bin/ansible
python version = 3.9.19 (main, Sep 11 2024, 00:00:00) [GCC 11.5.0 20240719 (Red Hat 11.5.0-2)] (/usr/bin/python3)
jinja version = 3.1.2
libyaml = True
部署单节点模式
# 创建目录
mkdir -p /var/lib/victoria-metrics
# 配置文件
cat <<END >/etc/systemd/system/victoriametrics.service
[Unit]
Description=VictoriaMetrics service
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/victoria-metrics-prod -storageDataPath=/var/lib/victoria-metrics -retentionPeriod=90d -selfScrapeInterval=10s
SyslogIdentifier=victoriametrics
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动服务
systemctl daemon-reload && sudo systemctl enable --now victoriametrics.service
# 检查服务
systemctl status victoriametrics
# victoriametriscs 内置了 ui
http://0.0.0.0:8428/vmui
部署集群模式
vmstorage
# 创建目录
mkdir -p /var/lib/vmstorage
# 配置文件
cat <<END >/etc/systemd/system/vmstorage.service
[Unit]
Description=VictoriaMetrics vmstorage service
After=network.target
[Service]
Type=simple
User=root
Group=root
Restart=always
ExecStart=/usr/local/bin/vmstorage-prod -retentionPeriod=90d -storageDataPath=/var/lib/vmstorage
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && systemctl enable --now vmstorage
vminstert
# 配置文件
cat << END >/etc/systemd/system/vminsert.service
[Unit]
Description=VictoriaMetrics vminsert service
After=network.target
[Service]
Type=simple
User=victoriametrics
Group=victoriametrics
Restart=always
ExecStart=/usr/local/bin/vminsert-prod -storageNode=192.168.0.110
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && sudo systemctl enable --now vminsert.service
# 多 vmstorgae 写法
-storageNode=192.168.0.110,192.168.0.111
vmselect
# 创建目录
mkdir -p /var/lib/vmselect-cache
# 配置文件
cat << END >/etc/systemd/system/vmselect.service
[Unit]
Description=VictoriaMetrics vmselect service
After=network.target
[Service]
Type=simple
User=root
Group=root
Restart=always
ExecStart=/usr/local/bin/vmselect-prod -storageNode=192.168.0.110 -cacheDataPath=/var/lib/vmselect-cache
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && sudo systemctl enable --now vmselect.service
# vmui
http://0.0.0.0:8481/select/0/vmui
检查监听端口
[root@vmserver ~]# netstat -naltp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8480 0.0.0.0:* LISTEN 12877/vminsert-prod
tcp 0 0 0.0.0.0:8481 0.0.0.0:* LISTEN 12843/vmselect-prod
tcp 0 0 0.0.0.0:8482 0.0.0.0:* LISTEN 12529/vmstorage-pro
tcp 0 0 0.0.0.0:8400 0.0.0.0:* LISTEN 12529/vmstorage-pro
tcp 0 0 0.0.0.0:8401 0.0.0.0:* LISTEN 12529/vmstorage-pro
部署采集器
prometheus
# 创建目录
mkdir -p /var/lib/prometheus/rules
# 配置文件
cat << END >/etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus service
After=network.target
[Service]
Type=simple
User=root
Group=root
Restart=always
ExecStart=/usr/local/bin/prometheus --config.file="/var/lib/prometheus/prometheus.yml" --config.auto-reload-interval=30s --storage.tsdb.path="/var/lib/prometheus/data/" --storage.tsdb.retention.time=2h --web.enable-lifecycle
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && sudo systemctl enable --now prometheus.service
node-exporter
- exporter_more (windows/ipmi/smartraid/ups/jenkins/jira/confluence/ovirt/ssh/podman/powerdns/script)
# 配置文件
cat << END >/etc/systemd/system/node_exporter.service
[Unit]
Description=Node-exporter service
After=network.target
[Service]
Type=simple
User=root
Group=root
Restart=always
ExecStart=/usr/local/bin/node_exporter --web.listen-address=0.0.0.0:9100
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && systemctl enable --now node_exporter
prometheus.yml 配置文件
[root@vmserver prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
external_labels:
env: maweibing
remote_write:
- url: http://192.168.0.110:8480/insert/0/prometheus
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.110:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "./rules/instance_down_status.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.0.110:9090"]
- job_name: "node-exporter"
static_configs:
- targets: ["192.168.0.110:9100"]
- job_name: "ipmi-exporter"
static_configs:
- targets: ["192.168.0.110:9290"]
- job_name: "alertmanager"
static_configs:
- targets: ["192.168.0.110:9093"]
- job_name: "blackbox-exporter"
static_configs:
- targets: ["192.168.0.110:9115"]
# 示例告警规则
[root@vmserver prometheus]# cat /var/lib/prometheus/rules/instance_down_status.yml
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
# Prometheus 开启热加载
curl -X POST http://192.168.0.110:9090/-/reload
部署仪表盘
安装 grafana
# 安装
wget -q -O gpg.key https://rpm.grafana.com/gpg.key
sudo rpm --import gpg.key
cat << END >/etc/yum.repos.d/grafana.repo
[grafana]
name=grafana
baseurl=https://rpm.grafana.com
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://rpm.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
END
dnf install grafana -y
# 手动下载 grafana rpm 包
wget https://dl.grafana.com/oss/release/grafana-11.4.0-1.x86_64.rpm
yum install -y grafana-11.4.0-1.x86_64.rpm
# 查看配置文件
[root@vmserver ~]# cat /etc/sysconfig/grafana-server
GRAFANA_USER=grafana
GRAFANA_GROUP=grafana
GRAFANA_HOME=/usr/share/grafana
LOG_DIR=/var/log/grafana
DATA_DIR=/var/lib/grafana
MAX_OPEN_FILES=10000
CONF_DIR=/etc/grafana
CONF_FILE=/etc/grafana/grafana.ini
RESTART_ON_UPGRADE=true
PLUGINS_DIR=/var/lib/grafana/plugins
PROVISIONING_CFG_DIR=/etc/grafana/provisioning
# Only used on systemd systems
PID_FILE_DIR=/var/run/grafana
# 启动 grafna
mkdir -p /var/lib/grafana
chown -R grafana:grafana /var/lib/grafana/
systemctl daemon-reload && sudo systemctl enable --now grafana-server
配置 grafana
- 首次登录需要更改密码,默认用户/密码:admin/admin
- 登录后,添加数据源:
- http://192.168.0.110:8481/select/0/prometheus # 前面部署好的 vmselect 的地址
- 8481: 是 vmselect
- /select/0/prometheus: 0 是自定义的 int 型数字,多个 prometheus 时都是为 0 ?,只是在 vmstorage 里面的标识么,可以其它数字么,待研究、prometheus 就是你数据源的类型
- http://192.168.0.110:8481/select/0/prometheus # 前面部署好的 vmselect 的地址
告警通知
安装 alertmanger
# 创建目录
mkdir -pv /var/lib/alertmanager
# 配置文件
cat << END >/etc/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager service
After=network.target
[Service]
Type=simple
User=root
Group=root
Restart=always
ExecStart=/usr/local/bin/alertmanager --config.file="/var/lib/alertmanager/alertmanager.yml" --storage.path="/var/lib/alertmanager/data/" --data.retention=2h --data.maintenance-interval=15m --alerts.gc-interval=30m --web.listen-address=:9093
PrivateTmp=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 启动
systemctl daemon-reload && systemctl enable --now alertmanager
# alertmanager 配置文件 - 多 receivers 示例配置
global:
resolve_timeout: 5m
smtp_from: "skyking116@163.com"
smtp_smarthost: "smtp.163.com:25"
smtp_auth_username: "skyking116@163.com"
smtp_auth_password: "*********" # 邮箱的授权码
smtp_require_tls: false
smtp_hello: '163.com'
templates:
- "/etc/vm/configs/**/*.tmpl"
route:
group_by:
- "alertname"
- "group_id"
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: insight
routes:
- receiver: 163mail
continue: true # 继续匹配下一个路由,也就是告警都会发送到所有的 receiver
receivers:
- name: insight
webhook_configs:
- url: http://insight-server.insight-system.svc.cluster.local:80/apis/insight.io/v1alpha1/alert/hook
- name: 163mail
email_configs:
- to: weibing.ma@daocloud.io
send_resolved: true
对接企业微信
# 自行申请一个企业微信,不需要上传资质
# 然后创建群组,把想收到告警通知的人都拉进去
# alertmanger 配置文件
frp 内网穿透
frp_server
# 创建目录
mkdir -p /var/lib/proxy
# 配置文件
cat <<END >/etc/systemd/system/proxy.service
[Unit]
Description=frp_server_proxy service
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/frps -c /var/lib/proxy/frps.toml
SyslogIdentifier=fprserver
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 服务配置文件
[root@cloud-sg8dm4-ip08 ~]# cat /var/lib/proxy/frps.toml
bindPort = xxxx
frp_client
# 创建目录
mkdir -p /var/lib/proxy
# 配置文件
cat <<END >/etc/systemd/system/proxy.service
[Unit]
Description=frp_server_proxy service
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/frpc -c /var/lib/proxy/frpc.toml
SyslogIdentifier=fprclient
Restart=always
PrivateTmp=yes
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
[Install]
WantedBy=multi-user.target
END
# 服务配置文件
[root@vmserver ~]# cat /var/lib/proxy/frpc.toml
serverAddr = "x.x.x.x" # 具有公网节点的 ip 地址
serverPort = xxxx # prxoy 暴露的端口,client 会通过他连接 server 端
# 本机的 22 端口,然后通过 prxoy-server 端的公网 ip:60222 对外暴露
[[proxies]]
name = "ssh" # 对 server 端,暴露 ssh 服务,
type = "tcp"
localIP = "127.0.0.1"
localPort = 22 # 本机的 22 端口,
remotePort = xxxxx # 通过公网 ip 访问时的 ssh 端口
# 本机的 3000 端口,然后通过 prxoy-server 端的公网 ip:63000 对外暴露
[[proxies]]
name = "web"
type = "tcp"
localIP = "127.0.0.1"
localPort = 3000
remotePort = xxxxx
VictoriaMetrics
通过 operator 安装 VictoriaMetrics
安装 operator
- 下载最新版本 operator 相关的 crd
export VM_OPERATOR_VERSION=$(basename $(curl -fs -o /dev/null -w %{redirect_url} https://github.com/VictoriaMetrics/operator/releases/latest));
echo "VM_OPERATOR_VERSION=$VM_OPERATOR_VERSION";
wget -O operator-and-crds.yaml \
"https://github.com/VictoriaMetrics/operator/releases/download/$VM_OPERATOR_VERSION/install-no-webhook.yaml";
# Output:
# VM_OPERATOR_VERSION=v0.56.0
- 安装 crd 和 operator
[root@mwb-k8s-master-test01 vm]# kubectl apply -f operator-and-crds.yaml
namespace/vm created
customresourcedefinition.apiextensions.k8s.io/vlagents.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vlclusters.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vlogs.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vlsingles.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmagents.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmalertmanagerconfigs.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmalertmanagers.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmalerts.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmanomalies.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmauths.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmclusters.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmnodescrapes.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmpodscrapes.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmprobes.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmrules.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmscrapeconfigs.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmservicescrapes.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmsingles.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmstaticscrapes.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vmusers.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vtclusters.operator.victoriametrics.com created
customresourcedefinition.apiextensions.k8s.io/vtsingles.operator.victoriametrics.com created
serviceaccount/vm-operator created
role.rbac.authorization.k8s.io/vm-leader-election-role created
clusterrole.rbac.authorization.k8s.io/vm-operator created
rolebinding.rbac.authorization.k8s.io/vm-leader-election-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/vm-operator created
service/vm-operator-metrics-service created
deployment.apps/vm-operator created
networkpolicy.networking.k8s.io/vm-allow-metrics-traffic created
networkpolicy.networking.k8s.io/vm-allow-webhook-traffic created
- 查看 operator 状态
[root@mwb-k8s-master-test01 vm]# kubectl get deployments.apps -n mv
No resources found in mv namespace.
[root@mwb-k8s-master-test01 vm]# kubectl get deployments.apps -n vm
NAME READY UP-TO-DATE AVAILABLE AGE
vm-operator 1/1 1 1 83s
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-674c6cc4fd-kdb4p 1/1 Running 0 88s
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service ClusterIP 10.233.57.253 <none> 8080/TCP 102s
[root@mwb-k8s-master-test01 vm]# kubectl api-resources --api-group=operator.victoriametrics.com
NAME SHORTNAMES APIVERSION NAMESPACED KIND
vlagents operator.victoriametrics.com/v1 true VLAgent
vlclusters operator.victoriametrics.com/v1 true VLCluster
vlogs operator.victoriametrics.com/v1beta1 true VLogs
vlsingles operator.victoriametrics.com/v1 true VLSingle
vmagents operator.victoriametrics.com/v1beta1 true VMAgent
vmalertmanagerconfigs operator.victoriametrics.com/v1beta1 true VMAlertmanagerConfig
vmalertmanagers vma operator.victoriametrics.com/v1beta1 true VMAlertmanager
vmalerts operator.victoriametrics.com/v1beta1 true VMAlert
vmanomalies operator.victoriametrics.com/v1 true VMAnomaly
vmauths operator.victoriametrics.com/v1beta1 true VMAuth
vmclusters operator.victoriametrics.com/v1beta1 true VMCluster
vmnodescrapes operator.victoriametrics.com/v1beta1 true VMNodeScrape
vmpodscrapes operator.victoriametrics.com/v1beta1 true VMPodScrape
vmprobes operator.victoriametrics.com/v1beta1 true VMProbe
vmrules operator.victoriametrics.com/v1beta1 true VMRule
vmscrapeconfigs operator.victoriametrics.com/v1beta1 true VMScrapeConfig
vmservicescrapes operator.victoriametrics.com/v1beta1 true VMServiceScrape
vmsingles operator.victoriametrics.com/v1beta1 true VMSingle
vmstaticscrapes operator.victoriametrics.com/v1beta1 true VMStaticScrape
vmusers operator.victoriametrics.com/v1beta1 true VMUser
vtclusters operator.victoriametrics.com/v1 true VTCluster
vtsingles operator.victoriametrics.com/v1 true VTSingle
部署 VictoriaMetrics 集群 single node
- 创建 single node yaml 文件 vm-single.yaml
cat <<'EOF' > vmsingle-demo.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMSingle
metadata:
name: vmsingle
namespace: vm
spec:
retentionPeriod: "7d"
replicaCount: 1
image:
repository: docker.m.daocloud.io/victoriametrics/victoria-metrics
tag: v1.131.0
pullPolicy: IfNotPresent
storage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
storageClassName: nfs-provisioner
serviceSpec:
spec:
type: NodePort
ports:
- name: http
port: 8429
targetPort: 8429
- name: grpc
port: 8428
targetPort: 8428
EOF
- 检查状体,并更新 svc 类型为 NodePort
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-674c6cc4fd-kdb4p 1/1 Running 0 12m
vmsingle-vmsingle-749798d5b8-ktkgp 0/1 ContainerCreating 0 33s
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm vmsingle-vmsing
Error from server (NotFound): services "vmsingle-vmsing" not found
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm vmsingle-vmsingle
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vmsingle-vmsingle ClusterIP 10.233.23.190 <none> 8429/TCP,8428/TCP 5m26s
[root@mwb-k8s-master-test01 vm]# kubectl edit svc -n vm vmsingle-vmsingle
service/vmsingle-vmsingle edited
[root@mwb-k8s-master-test01 ~]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service NodePort 10.233.57.253 <none> 8080:32131/TCP 46m
vmsingle-vmsingle ClusterIP 10.233.1.186 <none> 8429/TCP,8428/TCP 10m
vmsingle-vmsingle-additional-service NodePort 10.233.48.164 <none> 8429:31950/TCP,8428:30380/TCP 9s
- 访问 VictoriaMetrics 单节点实例
- 8429: http 端口(这里会返回 vm 的一些 api 接口,比如 vmui、targets、metrics 等)
- 8428: grpc 端口 (数据的写入和查询都是通过它),vmui 还是 8428 暴露出来的
http://10.1.32.175:31950/
Single-node VictoriaMetrics
See docs at https://docs.victoriametrics.com/
Useful endpoints:
vmui - Web UI
targets - status for discovered active targets
service-discovery - labels before and after relabeling for discovered targets
metric-relabel-debug - debug metric relabeling
expand-with-exprs - WITH expressions' tutorial
api/v1/targets - advanced information about discovered targets in JSON format
config - -promscrape.config contents
metrics - available service metrics
flags - command-line flags
api/v1/status/tsdb - tsdb status page
api/v1/status/top_queries - top queries
api/v1/status/active_queries - active queries
-/reload - reload configuration
http://10.1.32.175:31950/vmui/
- 为啥 rancher 中没有 cr 的封装
- 知识补充
- 写入数据
curl -i -X POST \
--url http://127.0.0.1:8428/api/v1/import/prometheus \
--header 'Content-Type: text/plain' \
--data 'a_metric{foo="fooVal"} 123'
- 查询数据
curl -i --url http://127.0.0.1:8428/api/v1/query --url-query query=a_metric
- vmsingle 相当于 allinone 的模式,数据通过 8428 写入后,会落到 vmstorage 中
VMSINGLE_POD_NAME=$(kubectl get pod -l "app.kubernetes.io/name=vmsingle" -n vm -o jsonpath="{.items[0].metadata.name}");
kubectl exec -n vm "$VMSINGLE_POD_NAME" -- ls -l /victoria-metrics-data;
[root@mwb-k8s-master-test01 ~]# kubectl exec -n vm "$VMSINGLE_POD_NAME" -- ps
PID USER TIME COMMAND
1 root 0:01 /victoria-metrics-prod -httpListenAddr=:8429 -retentionPeriod=7d -storageDataPath=/victoria-metrics-data
19 root 0:00 ps
部署 vmagent 来搜集 exporter 的数据到 vmsingle
- 创建 vmagent.yaml
cat <<'EOF' > vmagent.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAgent
metadata:
name: vmagent
namespace: vm
spec:
containers:
- name: vmagent
image: docker.m.daocloud.io/victoriametrics/vmagent:v1.131.0
- name: config-reloader
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
initContainers:
- name: config-init
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
selectAllByDefault: true
remoteWrite:
- url: "http://vmsingle-vmsingle.vm.svc:8428/api/v1/write"
replicaCount: 1
image:
repository: docker.m.daocloud.io/victoriametrics/vmagent
tag: v1.131.0
pullPolicy: IfNotPresent
serviceSpec:
spec:
type: NodePort
ports:
- name: http
port: 8429
targetPort: 8429
- name: grpc
port: 8435
targetPort: 8435
EOF
- 检查
[root@mwb-k8s-master-test01 vm]# kubectl apply -f vmagent.yaml
vmagent.operator.victoriametrics.com/vmagent created
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-674c6cc4fd-kdb4p 1/1 Running 0 64m
vmagent-vmagent-567bf6879-4l9kj 0/2 Init:0/1 0 8s
vmsingle-vmsingle-76b88c76d5-jq8wd 1/1 Running 0 29m
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service NodePort 10.233.57.253 <none> 8080:32131/TCP 64m
vmagent-vmagent ClusterIP 10.233.44.106 <none> 8429/TCP 14s
vmagent-vmagent-additional-service NodePort 10.233.52.118 <none> 8429:31663/TCP,8428:30734/TCP 14s
vmsingle-vmsingle ClusterIP 10.233.1.186 <none> 8429/TCP,8428/TCP 28m
vmsingle-vmsingle-additional-service NodePort 10.233.48.164 <none> 8429:31950/TCP,8428:30380/TCP 18m
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-78f68b8b5-5clqr 1/1 Running 0 42m
vmagent-vmagent-686cd5dbd9-5dz79 2/2 Running 0 32s
vmsingle-vmsingle-76b88c76d5-jq8wd 1/1 Running 0 83m
- http://10.1.32.177:31663/ # 8429
- http://10.1.32.177:31663/targets
- 部署 demo 应用
cat <<'EOF' > demo-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-app
namespace: default
labels:
app.kubernetes.io/name: demo-app
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: demo-app
template:
metadata:
labels:
app.kubernetes.io/name: demo-app
spec:
containers:
- name: main
image: docker.m.daocloud.io/victoriametrics/demo-app:1.2
---
apiVersion: v1
kind: Service
metadata:
name: demo-app
namespace: default
labels:
app.kubernetes.io/name: demo-app
spec:
selector:
app.kubernetes.io/name: demo-app
ports:
- port: 8080
name: http
EOF
- 创建 scrape 配置,它会告知 vmagent 去 scrape 这个服务的 metrics 数据
cat <<'EOF' > demo-app-scrape.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMServiceScrape
metadata:
name: demo-app-service-scrape
spec:
selector:
matchLabels:
app.kubernetes.io/name: demo-app
endpoints:
- port: http
EOF
[root@mwb-k8s-master-test01 vm]# kubectl apply -f demo-app-scrape.yaml
vmservicescrape.operator.victoriametrics.com/demo-app-service-scrape created
[root@mwb-k8s-master-test01 vm]# kubectl get vmservicescrapes.operator.victoriametrics.com
NAME AGE STATUS SYNC ERROR
demo-app-service-scrape 106s operational
部署 vmalertmananger、vmalert、vmrule 来告警
- 安装 vmalertmanager
cat <<'EOF' > vmalertmanager.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAlertmanager
metadata:
name: vmalertmanager
namespace: vm
spec:
configRawYaml: |
route:
receiver: 'demo-app'
receivers:
- name: 'demo-app'
webhook_configs:
- url: 'http://demo-app.default.svc:8080/alerting/webhook'
replicaCount: 1
containers:
- name: config-reloader
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
image:
repository: docker.m.daocloud.io/prom/alertmanager
tag: v0.29.0
pullPolicy: IfNotPresent
serviceSpec:
spec:
type: NodePort
ports:
- name: http
port: 9093
targetPort: 9093
EOF
[root@mwb-k8s-master-test01 vm]# kubectl apply -f vmalertmanager.yaml
vmalertmanager.operator.victoriametrics.com/vmalertmanager created
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service NodePort 10.233.57.253 <none> 8080:32131/TCP 11h
vmagent-vmagent ClusterIP 10.233.44.106 <none> 8429/TCP 10h
vmagent-vmagent-additional-service NodePort 10.233.52.118 <none> 8429:31663/TCP,8428:30734/TCP 10h
vmalertmanager-vmalertmanager ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m58s
vmalertmanager-vmalertmanager-additional-service NodePort 10.233.36.98 <none> 9093:31668/TCP 3m58s
vmsingle-vmsingle ClusterIP 10.233.1.186 <none> 8429/TCP,8428/TCP 10h
vmsingle-vmsingle-additional-service NodePort 10.233.48.164 <none> 8429:31950/TCP,8428:30380/TCP 10h
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-78f68b8b5-5clqr 1/1 Running 0 9h
vmagent-vmagent-686cd5dbd9-5dz79 2/2 Running 0 9h
vmalertmanager-vmalertmanager-0 2/2 Running 0 39s
vmsingle-vmsingle-76b88c76d5-jq8wd 1/1 Running 0 10h
- http://10.1.32.177:31668/#/status # 9093 是 alertmanager 的 http 端口
- 创建 vmalert
cat <<'EOF' > vmalert.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAlert
metadata:
name: vmalert
namespace: vm
spec:
containers:
- name: config-reloader
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
image:
repository: docker.m.daocloud.io/victoriametrics/vmalert
tag: v1.131.0
# Metrics source (VMCluster/VMSingle)
datasource:
url: "http://vmsingle-vmsingle.vm.svc:8428"
# Where alert state and recording rules are stored
remoteWrite:
url: "http://vmsingle-vmsingle.vm.svc:8428"
# Where the previous alert state is loaded from. Optional
remoteRead:
url: "http://vmsingle-vmsingle.vm.svc:8428"
# Alertmanager URL for sending alerts
notifier:
url: "http://vmalertmanager-vmalertmanager.vm.svc:9093"
# How often the rules are evaluated
evaluationInterval: "10s"
# Watch VMRule resources in all namespaces
selectAllByDefault: true
serviceSpec:
spec:
type: NodePort
ports:
- name: http
port: 8080
targetPort: 8080
EOF
[root@mwb-k8s-master-test01 vm]# kubectl apply -f vmalert.yaml
vmalert.operator.victoriametrics.com/vmalert created
[root@mwb-k8s-master-test01 ~]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service NodePort 10.233.57.253 <none> 8080:32131/TCP 12h
vmagent-vmagent ClusterIP 10.233.44.106 <none> 8429/TCP 10h
vmagent-vmagent-additional-service NodePort 10.233.52.118 <none> 8429:31663/TCP,8428:30734/TCP 10h
vmalert-vmalert ClusterIP 10.233.36.230 <none> 8080/TCP 44m
vmalert-vmalert-additional-service NodePort 10.233.41.234 <none> 8080:31166/TCP 7s
vmalertmanager-vmalertmanager ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 55m
vmalertmanager-vmalertmanager-additional-service NodePort 10.233.36.98 <none> 9093:31668/TCP 55m
vmsingle-vmsingle ClusterIP 10.233.1.186 <none> 8429/TCP,8428/TCP 11h
vmsingle-vmsingle-additional-service NodePort 10.233.48.164 <none> 8429:31950/TCP,8428:30380/TCP 11h
[root@mwb-k8s-master-test01 ~]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-78f68b8b5-5clqr 1/1 Running 0 10h
vmagent-vmagent-686cd5dbd9-5dz79 2/2 Running 0 10h
vmalert-vmalert-cf767bc5b-npvwl 2/2 Running 0 39m
vmalertmanager-vmalertmanager-0 2/2 Running 0 52m
vmsingle-vmsingle-76b88c76d5-jq8wd 1/1 Running 0 11h
- http://10.1.32.177:31166/ # 8080 VMAlert UI
API:
api/v1/rules - list all loaded groups and rules
api/v1/alerts - list all active alerts
api/v1/notifiers - list all notifiers
api/v1/alert?group_id=<int>&alert_id=<int> - get alert status by group and alert ID
api/v1/rule?group_id=<int>&rule_id=<int> - get rule status by group and rule ID
api/v1/group?group_id=<int> - get group status by group ID
System:
vmalert/groups - UI
flags - command-line flags
metrics - list of application metrics
-/reload - reload configuration
demo-app (every 10s) #
1
/etc/vmalert/config/vm-vmalert-rulefiles-0/default-demo.yaml
- 创建 vmrule 告警规则
cat <<'EOF' > demo-app-rule.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
name: demo
namespace: default
spec:
groups:
- name: demo-app
rules:
- alert: DemoAlertFiring
expr: 'sum(demo_alert_firing{job="demo-app",namespace="default"}) by (job,pod,namespace) > 0'
for: 30s
labels:
job: '{{ $labels.job }}'
pod: '{{ $labels.pod }}'
annotations:
description: 'demo-app pod {{ $labels.pod }} is firing demo alert'
EOF
kubectl apply -f demo-app-rule.yaml
kubectl wait --for=jsonpath='{.status.updateStatus}'=operational vmrule/demo
[root@mwb-k8s-master-test01 vm]# kubectl get vmrules.operator.victoriametrics.com
NAME AGE STATUS SYNC ERROR
demo 17s operational
http://10.1.32.177:31166/vmalert/groups?search= # 8080 VMAlert UI
demo-app (every 10s) #
1
/etc/vmalert/config/vm-vmalert-rulefiles-0/default-demo.yaml
开启认证
- 部署 vmauth
cat <<'EOF' > vmauth.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAuth
metadata:
name: vmauth
spec:
initContainers:
- name: config-init
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
containers:
- name: config-reloader
image: docker.m.daocloud.io/victoriametrics/operator:config-reloader-v0.66.1
image:
repository: docker.m.daocloud.io/victoriametrics/vmauth
tag: v1.131.0
selectAllByDefault: true
ingress:
class_name: 'nginx'
host: victoriametrics.dominos.com.cn
serviceSpec:
spec:
type: NodePort
ports:
- name: http
port: 8427
targetPort: 8427
EOF
[root@mwb-k8s-master-test01 vm]# kubectl apply -f vmauth.yaml
vmauth.operator.victoriametrics.com/vmauth created
[root@mwb-k8s-master-test01 vm]# kubectl get pod -n vm
NAME READY STATUS RESTARTS AGE
vm-operator-78f68b8b5-5clqr 1/1 Running 0 11h
vmagent-vmagent-686cd5dbd9-5dz79 2/2 Running 0 10h
vmalert-vmalert-cf767bc5b-npvwl 2/2 Running 0 76m
vmalertmanager-vmalertmanager-0 2/2 Running 0 88m
vmauth-vmauth-8467c998cf-ghs52 2/2 Running 0 29s
vmsingle-vmsingle-76b88c76d5-jq8wd 1/1 Running 0 12h
[root@mwb-k8s-master-test01 vm]# kubectl get svc -n vm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vm-operator-metrics-service NodePort 10.233.57.253 <none> 8080:32131/TCP 12h
vmagent-vmagent ClusterIP 10.233.44.106 <none> 8429/TCP 11h
vmagent-vmagent-additional-service NodePort 10.233.52.118 <none> 8429:31663/TCP,8428:30734/TCP 11h
vmalert-vmalert ClusterIP 10.233.36.230 <none> 8080/TCP 81m
vmalert-vmalert-additional-service NodePort 10.233.41.234 <none> 8080:31166/TCP 36m
vmalertmanager-vmalertmanager ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 92m
vmalertmanager-vmalertmanager-additional-service NodePort 10.233.36.98 <none> 9093:31668/TCP 92m
vmauth-vmauth ClusterIP 10.233.9.104 <none> 8427/TCP 39s
vmauth-vmauth-additional-service NodePort 10.233.41.18 <none> 8427:30599/TCP 39s
vmsingle-vmsingle ClusterIP 10.233.1.186 <none> 8429/TCP,8428/TCP 12h
vmsingle-vmsingle-additional-service NodePort 10.233.48.164 <none> 8429:31950/TCP,8428:30380/TCP 11h
[root@mwb-k8s-master-test01 vm]# kubectl get ingress -n vm
NAME CLASS HOSTS ADDRESS PORTS AGE
vmauth-vmauth nginx victoriametrics.dominos.com.cn 10.233.29.142 80 2m25s
- http://10.1.32.177:30599/ # 8427 vmauth-UI,上来就让输入用户名和密码
- 创建 vmuser 认证信息
cat <<'EOF' > vmuser.yaml
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMUser
metadata:
name: vmuser
namespace: vm
spec:
name: vmuser-demo
username: weibing.ma
generatePassword: true
targetRefs:
# vmsingle
- crd:
kind: VMSingle
name: vmsingle
namespace: vm
paths:
- "/vmui.*"
- "/prometheus/.*"
# vmalert
- crd:
kind: VMAlert
name: vmalert
namespace: vm
paths:
- "/vmalert.*"
- "/api/v1/groups"
- "/api/v1/alert"
- "/api/v1/alerts"
# vmagent
- crd:
kind: VMAgent
name: vmagent
namespace: vm
paths:
- "/api/v1/write"
- "/api/v1/read"
- "/targets.*"
# vmalertmanager
- crd:
kind: VMAlertmanager
name: vmalertmanager
namespace: vm
paths:
- "/api/v2/alerts"
- "/api/v2/status"
EOF
[root@mwb-k8s-master-test01 vm]# kubectl apply -f vmuser.yaml
vmuser.operator.victoriametrics.com/vmuser created
[root@mwb-k8s-master-test01 vm]# kubectl get vmagents.operator.victoriametrics.com -n vm
NAME SHARDS COUNT REPLICA COUNT STATUS AGE
vmagent 1 operational 11h
[root@mwb-k8s-master-test01 vm]# kubectl get secret -n vm
NAME TYPE DATA AGE
tls-assets-vmagent-vmaget Opaque 0 11h
tls-assets-vmalert-vmalert Opaque 0 93m
vmagent-vmaget Opaque 1 11h
vmalert-vmalert Opaque 0 93m
vmalertmanager-vmalertmanager-config Opaque 1 104m
vmauth-config-vmauth Opaque 1 12m
vmuser-vmuser Opaque 3 2m40s
[root@mwb-k8s-master-test01 vm]# kubectl get secret -n vm vmuser-vmuser -o yaml
apiVersion: v1
data:
name: dmFjdGlvci12bXVzZXItZGVtby==
password: <PASSWORD>==
username: d2VpYmluZy5tYQ==
export DEMO_USERNAME="$(kubectl get secret -n vm vmuser-vmuser -o jsonpath="{.data.username}" | base64 --decode)";
export DEMO_PASSWORD="$(kubectl get secret -n vm vmuser-vmuser -o jsonpath="{.data.password}" | base64 --decode)";
echo "Username: $DEMO_USERNAME; Password: $DEMO_PASSWORD";
- http://victoriametrics.dominos.com.cn/vmui/ # vmsingle
- http://victoriametrics.dominos.com.cn/targets # vmagent
- http://victoriametrics.dominos.com.cn/vmalert # vmalert
- http://victoriametrics.dominos.com.cn/api/v2/status # vmalertmanager
Usage
查询类
配置类
Grafana 类
Prometheus 查询函数
label_join
- 新增 label,并将 source_labels 的 values 赋予给 new_label=values
- 格式:
label_join(v instant-vector, dst_label string, separator string, src_label_1, src_label_2)
- 示例:
label_join(up{job="kubelet"},"new_key",",","instance","node_ip") # 若 "," 不写,会将第二个源标签 valeus 就行赋值,此语句是将 "instance","node_ip" 赋值给 new_key
- 输出:
up{beta_kubernetes_io_arch="amd64",beta_kubernetes_io_os="linux",instance="k8s-master01",job="kubelet",kubernetes_io_arch="amd64",kubernetes_io_hostname="k8s-master01",kubernetes_io_os="linux",new_key="k8s-master01,10.6.203.60",node_ip="10.6.203.60",noderole="master"}
label_replace
- 新增 label,并将 source_labels 的 values 赋予给 new_label=values,并且支持 regex 匹配
- 格式:
label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string) # 如果 regex 匹配不到,则按原数据进行显示
- 示例:
label_replace(up,"new_key","$1","instance","(.*):.*") # 匹配 "instance" 的 values 的第一列数据,并且按 "(.*):.*" 进行过滤
label_replace(up,"new_key","$1","instance","(.*)") # 匹配 "instance" 的 values 的第一列数据
- 输出:
up{instance="10.6.179.65:9090",job="prometheus",new_key="10.6.179.65"}
up{instance="10.6.179.65:9090",job="prometheus",new_key="10.6.179.65:9090"}
Prometheus 配置文件 relabel_configs 实操
- source_labels: 源标签
- separator: 分隔符,默认为;
- regex: 按正则进行匹配,默认为 .*
- target_label: 指定一个 label 的 key
- replacement: 通过regex 检索出来的进行替换,默认为 $1 也就是 regex 匹配出来的 value
- action: <relabel_action> 基于 regex 进行的操作,默认是 replace
relabel_action
- replace: 按 regex 进行匹配,并配合 replacement 的 $x,将 target_labels 的 key 与 replacement 的 $x 进行组合,另外如果没有 regex 则不会就行替换
- keep: 删除 regex 不匹配的 source_lables
- drop: 删除 regex 匹配的 source_lables
- labelmap: 将所有 regex 匹配到的lables,配合 replacement 进行替换操作
- labelkeep:删除 regex 不匹配的 source_lables
- labeldrop:删除 regex 不匹配的 source_lables
示例
- prometheus-job_configs
- job_name: kubelet-cadvisor
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics/cadvisor
scheme: https
kubernetes_sd_configs:
- api_server: https://10.6.203.60:6443
role: node
bearer_token_file: /opt/caas/prometh/prometh_server/k8s.token
tls_config:
insecure_skip_verify: true
bearer_token_file: /opt/caas/prometh/prometh_server/k8s.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- prometheus-job_configs_jpg

relabel_config场景
1. 标签新增(在后期制作dashboard以及使用metrics进行高级及自定义的筛选时会用到)
2. 标签重构
- 示例文件如下:
relabel_configs:
- regex: __meta_kubernetes_node_label_(.+) #标签重构而非元数据信息
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_node_address_InternalIP] #标签新增
target_label: node_ip
replacement: $1
action: replace
Grafana Dashboard
Dashboard 中定义 Query Variable 从而获取对应 Job 中的 label 信息
常用查询变量 Prometheus template variables
Name Description
label_names() Returns a list of label names.
label_values(label) Returns a list of label values for the label in every metric.
label_values(metric, label) Returns a list of label values for the label in the specified metric.
metrics(metric) Returns a list of metrics matching the specified metric regex.
query_result(query) Returns a list of Prometheus query result for the query.
前后数据对比(Prometheus Graph)
# 源数据
node_filesystem_size_bytes{device="/dev/mapper/centos-root",fstype="xfs",instance="10.6.203.60:9100",job="node_exporter-metrics",mountpoint="/"} 50432839680
node_filesystem_size_bytes{device="/dev/mapper/centos-root",fstype="xfs",instance="10.6.203.62:9100",job="node_exporter-metrics",mountpoint="/"}
# 目标数据
label_values(node_filesystem_size_bytes,instance)
Preview of values
All 10.6.203.60:9100 10.6.203.62:9100 10.6.203.63:9100 10.6.203.64:9100
Grafana 子路径
-
在使用代理的场景下,可能会涉及到子路径的问题,因为同意域名下面不能有多个 /,否则会导致转发失败
-
k8s ingress 规则中,同一个域名也会出现上面的问题,其本质是一个问题
- 提交允许换个域名即可
如何配置
# If you use reverse proxy and sub path specify full url (with sub path)
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana/
# Serve Grafana from subpath specified in `root_url` setting. By default it
is set to `false` for compatibility reasons.
serve_from_sub_path = true
- /grafana/ 在这里是加入的 uri 子路径
Grafana 中相似 Pod 名称匹配问题总结
一、问题现象
Kubernetes 中存在两个名称相似的 Deployment:
delivery-test-service
delivery-test-service-special
它们生成的 Pod 分别为:
delivery-test-service-6dbf645bdc-zsf79
delivery-test-service-special-5ccc757cbb-78qkw
Grafana 变量中需要同时展示这两个服务,但查询中如果使用模糊匹配:
pod=~"${service:regex}.*"
由于两个服务名称存在前缀包含关系,可能导致选择其中一个服务时,将另一个服务的 Pod 也匹配出来。
二、解决方法一:使用完整的严格正则
pod=~"^(${service:regex})-[^-]+-[^-]+$"
正则含义
^ 从 Pod 名称开头匹配
(${service:regex}) 匹配 Grafana 中选择的服务名称
- 匹配连字符
[^-]+ 匹配 ReplicaSet 哈希
- 匹配连字符
[^-]+ 匹配 Pod 随机后缀
$ 必须匹配到 Pod 名称结尾
匹配的 Pod 名称结构为:
服务名称-ReplicaSet哈希-Pod随机后缀
例如变量选择:
delivery-test-service
可以匹配:
delivery-test-service-6dbf645bdc-zsf79
不会匹配:
delivery-test-service-special-5ccc757cbb-78qkw
因为在 delivery-test-service 后面存在三段内容:
special-5ccc757cbb-78qkw
而正则只允许存在两段。
三、解决方法二:使用简化正则
pod=~"${service:regex}-[^-]+-[^-]+"
该写法与完整写法的匹配效果基本相同。
这是因为 Prometheus 的标签正则匹配默认采用完整字符串匹配,因此通常可以省略:
^ 开头限定
$ 结尾限定
() 外层分组
同样能够保证 Pod 名称符合以下结构:
服务名称-ReplicaSet哈希-Pod随机后缀
四、两种方法的区别
| 对比项 | 完整写法 | 简化写法 |
|---|---|---|
| 表达式 | ^(${service:regex})-[^-]+-[^-]+$ | ${service:regex}-[^-]+-[^-]+ |
| 匹配效果 | 严格匹配完整 Pod 名称 | 在 PromQL 中效果基本相同 |
| 可读性 | 边界表达更明确 | 更简洁 |
| 对 Prometheus 默认行为的依赖 | 较少 | 依赖 Prometheus 正则默认完整匹配 |
| 适用范围 | PromQL、普通正则工具、Grafana Regex 过滤 | 更适合直接写在 PromQL 标签条件中 |
| 推荐场景 | 强调严谨、方便后续维护 | Grafana 面板查询,追求简洁 |
五、最终建议
如果该表达式直接用于 Grafana 的 PromQL 查询,推荐使用简化写法:
pod=~"${service:regex}-[^-]+-[^-]+"
如果表达式还可能复制到 Grafana 变量的 Regex 过滤、脚本或其他正则工具中,推荐保留完整写法:
pod=~"^(${service:regex})-[^-]+-[^-]+$"
两种方法的核心逻辑相同:限制服务名称后面只能存在两段 Pod 后缀,避免名称相似的服务发生前缀误匹配。
Grafana Operator(integreatly.org/v1alpha1)创建 Dashboard 指定目录说明
1. 背景
在 Kubernetes 环境中,如果通过 Grafana Operator 管理 Dashboard,通常使用:
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDashboard
该方式通过 Kubernetes CR(Custom Resource)声明式管理 Grafana Dashboard。
默认情况下,如果不指定目录,Dashboard 通常会进入 Grafana 默认目录。
integreatly.org/v1alpha1 版本可以通过 spec.customFolderName 指定
Dashboard 所属 Folder。
2. 指定 Dashboard 目录
示例:
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDashboard
metadata:
name: insight-grafana-dashboard-redis-instance
namespace: insight-system
labels:
operator.insight.io/managed-by: insight
spec:
customFolderName: "Middleware"
json: |-
{
"title": "Redis Instance Dashboard",
"uid": "redis-instance",
"schemaVersion": 39,
"version": 1,
"panels": []
}
创建后 Grafana 目录结构:
Dashboards
└── Middleware
└── Redis Instance Dashboard
3. 多级目录
Grafana 支持通过 / 创建多级目录:
spec:
customFolderName: "Middleware/Redis"
效果:
Dashboards
└── Middleware
└── Redis
└── Redis Instance Dashboard
4. 使用 ConfigMap 管理 Dashboard JSON
生产环境推荐将 Dashboard JSON 独立保存到 ConfigMap。
ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-dashboard-json
namespace: insight-system
data:
redis-dashboard.json: |-
{
"title": "Redis Instance Dashboard",
"uid": "redis-instance",
"panels": []
}
GrafanaDashboard
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDashboard
metadata:
name: redis-instance-dashboard
namespace: insight-system
spec:
customFolderName: "Middleware/Redis"
configMapRef:
name: redis-dashboard-json
key: redis-dashboard.json
5. 验证配置
查看 Dashboard CR:
kubectl get grafanadashboard \
-n insight-system \
redis-instance-dashboard -o yaml
确认:
spec:
customFolderName: Middleware/Redis
查看 Grafana Operator 日志:
kubectl logs -n <operator-namespace> \
deployment/grafana-operator
6. 常见问题
6.1 Dashboard 仍然显示在 General
检查字段位置。
正确:
spec:
customFolderName: "Redis"
json: |-
错误:
json:
customFolderName: Redis
6.2 JSON 中配置 Folder 是否有效
无效:
{
"title": "Redis Dashboard",
"folder": "Redis"
}
原因:
Dashboard JSON 只负责 Dashboard 内容,例如:
- Panel
- Query
- Variable
- Annotation
Folder 属于 Grafana 元数据,由 Operator 创建 Dashboard 时处理。
6.3 修改目录后没有变化
如果 Dashboard 已经存在,修改:
customFolderName
可能不会移动已有 Dashboard。
建议删除后重新创建:
kubectl delete grafanadashboard \
redis-instance-dashboard \
-n insight-system
然后:
kubectl apply -f dashboard.yaml
7. 检查 CRD 是否支持
查看字段:
kubectl explain grafanadashboard.spec
或者:
kubectl get crd grafanadashboards.integreatly.org -o yaml \
| grep customFolderName
如果输出:
customFolderName
表示当前版本支持。
8. 推荐目录规划
Grafana
├── Kubernetes
│ ├── Cluster
│ ├── Node
│ ├── Pod
│ └── Ingress
│
├── Middleware
│ ├── Redis
│ ├── MySQL
│ ├── Kafka
│ └── Elasticsearch
│
├── Business
│ ├── EC
│ └── Delivery
│
└── Network
├── Zabbix
└── NPM
示例:
spec:
customFolderName: "Middleware/MySQL"
9. 总结
需求 配置
指定 Dashboard 目录 spec.customFolderName
一级目录 customFolderName: Redis
多级目录 customFolderName: Middleware/Redis
JSON 中配置 Folder 不支持
生产环境推荐 ConfigMap + GrafanaDashboard
对于:
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDashboard
直接增加:
spec:
customFolderName: "Middleware/Redis"
即可实现 Dashboard 自动归档到指定 Grafana Folder。
TroubleShooting 事件记录
Prometheus Targets 中 Job 丢失
Prometheus Job 丢失事件
Prometheus 的监控项 是什么 ?
众所周知,Prometheus 中的监控项是在 Targets 中的,而 Targets 中定义了具体的监控项,也就是所谓的 Job,详情见 CONFIGURATION 和 SampleConfig
记一次 Job 丢失后如何恢复
- 一次巡检中发现监控项 kubelet 丢失
排查思路
-
查看 Prometheus 的配置文件,确认是否真的有配置其 kubelet 的 job
- 存在
-
查看 Prometheus Pod 的 log,提示 open /etc/ssl/private/kubelet/tls.crt: no such file or directory“
- 说明是 Prometheus Server 去访问 kubelet job 的实例时认证错误导致(提示:找不到对应的证书文件)
-
查看 Promethues StatefulSets,发现之前添加 volumes 和 volumeMounts 丢失了
- volume 和 volumeMounts 就是声明了将 tls.crt 证书放在哪个目录下
-
由于 Prometheus 时采用 operator 部署的,因此怀疑 operator 相关的 pod 重启导致 Promethues StatefulSets 的配置被还原,从而导致后续自定义的监控项 (Job) 被丢失
-
建议自定义监控项 (Job) 全部更改为永久生效
更改为永久生效
- 将 kubelet-tls 密钥添加至 Prometheus CRD 下 k8s 资源中
kubectl get prometheus k8s -n monitoring -o yaml
secrets: #增加 kubelet-tls
- kubelet-tls
- 上述执行后,Prometheus 的 sts 会自动重建 pod,Prometheus 下会新增一个 volumeMounts 、volumes 的声明
volumeMounts:
- mountPath: /etc/prometheus/secrets/kubelet-tls
name: secret-kubelet-tls
readOnly: true
volumes:
- name: secret-kubelet-tls
secret:
defaultMode: 420
secretName: kubelet-tls
- 查看发现 Tartgets 下依然没有 kubelet 的 job,查看 Prometheus 的 log 发现证书路径与 volumeMounts 不一致
kubectl logs -f prometheus-k8s-0 -n monitoring -c prometheus
level=error ts=2021-01-06T10:09:02.392Z caller=manager.go:188 component="scrape manager" msg="error creating new scrape pool" err="error creating HTTP client: unable to use specified client cert (/etc/ssl/private/kubelet/tls.crt) & key (/etc/ssl/private/kubelet/tls.key): open /etc/ssl/private/kubelet/tls.crt: no such file or directory" scrape_pool=monitoring/kubelet/0
level=error ts=2021-01-06T10:09:02.392Z caller=manager.go:188 component="scrape manager" msg="error creating new scrape pool" err="error creating HTTP client: unable to use specified client cert (/etc/ssl/private/kubelet/tls.crt) & key (/etc/ssl/private/kubelet/tls.key): open /etc/ssl/private/kubelet/tls.crt: no such file or directory" scrape_pool=monitoring/kubelet/1
- 编辑 Servicemonitor 下 kubelet 监控项
kubectl edit servicemonitor kubelet -n monitoring
%s#/etc/ssl/private/kubelet#/etc/prometheus/secrets/kubelet-tls#g #:(冒号),全局替换保存退出
- 再次查看 kubelet 监控项 (Job) 已恢复
结论
-
追述之前是变更步骤时 kubectl patch 的方式添加的 volumes 和 volumeMounts 字段,所以在编辑 monitoring 下 crd 的 k8s 资源后,重建了 Prometheus 的 pod,所以之前自定义的配置丢失了
-
查看 operator 相关知识,说是可以在 crd prometheus下的 k8s 资源中自定义 volumes 和 volumemounts,但是尝试了几次不行,于是参照了 etcd-certs 的方式,并修改 Servermointor 下 kubelet 后使其永久生效
方案一:多集群Prometheus + Remote-Write集中存储(VMStorage) + Grafana集中查询
架构
- 每个集群部署Prometheus,配置
remote-write将数据实时写入中心化VMStorage集群。 - Grafana直接查询VMStorage,统一展示所有集群数据。
优点
-
数据集中管理
- 所有数据统一存储在VMStorage中,便于长期保留、备份和跨集群聚合分析。
- 避免数据孤岛,适合全局监控和告警规则统一配置。
-
存储扩展性
- VMStorage支持横向扩展,可通过增加节点应对数据增长,适合海量监控场景。
- 数据压缩率高(VictoriaMetrics的存储效率优于Prometheus TSDB)。
-
查询性能
- 集中存储支持高效的跨集群查询(如
sum by (cluster)),无需Grafana从多个数据源聚合数据。 - VictoriaMetrics对PromQL兼容性好,且在大规模数据下查询速度更快。
- 集中存储支持高效的跨集群查询(如
-
维护成本
- 只需维护中心化VMStorage集群,无需关注各集群本地存储的容量、备份等问题。
- Prometheus实例可配置为无状态模式(关闭本地存储),降低运维复杂度。
-
高可用性
- VMStorage支持多副本,数据可靠性高。
- 即使某个集群的Prometheus宕机,中心存储的数据仍完整。
缺点
-
网络依赖
remote-write需稳定网络,网络抖动可能导致数据写入延迟或丢失(需配置重试机制)。- 跨地域集群可能因高延迟影响写入性能。
-
中心存储压力
- 所有集群的数据写入集中在VMStorage,需合理规划存储集群规模,避免写入吞吐量成为瓶颈。
- 存储集群故障会影响全局监控数据查询。
-
资源消耗
- VMStorage集群需要额外资源(CPU、内存、磁盘),初期部署成本较高。
瓶颈
- 写入吞吐量:VMStorage的写入性能取决于节点数量和配置,需监控
vminsert节点的负载。 - 网络带宽:大规模集群或高频指标场景下,
remote-write可能占用大量带宽。
方案二:多集群Prometheus本地存储 + Grafana多数据源查询
架构
- 每个集群独立部署Prometheus,数据存储在本地TSDB。
- Grafana配置多个Prometheus数据源,分别查询各集群数据。
优点
-
架构简单
- 无中心化存储依赖,各集群监控完全独立,适合小型或隔离环境。
- 部署简单,无需维护VMStorage集群。
-
网络开销低
- 数据无需远程传输,减少带宽占用(尤其适合网络受限环境)。
-
数据隔离性
- 单个集群的Prometheus故障不会影响其他集群数据。
缺点
-
数据分散
- Grafana需配置多个数据源,跨集群查询需手动聚合(如
federation或recording rules),复杂度高。 - 无法直接实现全局聚合计算(如统计所有集群的CPU使用率总和)。
- Grafana需配置多个数据源,跨集群查询需手动聚合(如
-
存储限制
- Prometheus本地TSDB默认保留15天,长期数据需自行解决(如Thanos或Cortex接入,但会增加复杂度)。
- 单机磁盘容量限制,无法应对大规模指标增长。
-
维护成本高
- 需为每个集群单独配置存储、备份、保留策略,运维工作量随集群数量线性增长。
- Prometheus的高可用需额外配置(如双实例+负载均衡)。
-
查询性能差
- Grafana从多个Prometheus拉取数据再聚合,延迟较高,尤其在大范围时间跨度查询时。
瓶颈
- 本地存储容量:单个Prometheus实例的磁盘可能成为瓶颈,需定期清理或扩展。
- 查询效率:Grafana多数据源聚合查询速度慢,且可能因部分Prometheus响应慢导致整体超时。
对比总结
| 维度 | 方案一(Remote-Write + VMStorage) | 方案二(本地存储 + 多数据源) |
|---|---|---|
| 数据管理 | 集中存储,长期保留,易备份 | 分散存储,短期保留,备份复杂 |
| 查询性能 | 高效,支持跨集群聚合 | 低效,需手动聚合多数据源 |
| 扩展性 | 存储横向扩展,适合海量数据 | 受限于单机磁盘,扩展成本高 |
| 网络依赖 | 依赖稳定网络传输 | 无远程传输,网络开销低 |
| 运维复杂度 | 维护中心存储集群,Prometheus无状态化 | 需维护每个集群的Prometheus存储和配置 |
| 成本 | 中心存储资源成本高,但长期性价比更优 | 单集群成本低,但总量可能更高(重复开销) |
| 适用场景 | 中大型多集群环境,需全局监控和长期数据分析 | 小型或隔离集群,网络受限,短期监控需求 |
推荐选择
- 优先方案一:适合大多数企业场景,尤其是多集群、数据量大、需长期存储和全局分析的场景。VictoriaMetrics的扩展性和查询性能优势明显,且能降低运维负担。
- 考虑方案二:仅适用于集群数量少、数据量小、网络条件差或环境隔离严格的场景(如边缘计算)。
方案 1:Prometheus + Remote-Write 到 vmstorage(集中存储)
架构
• 各集群都部署 Prometheus,配置 remote_write 将数据写入集中存储(vmstorage)。
• Grafana 通过 vmstorage 查询数据。
优点
✅ 集中存储,数据统一管理
• vmstorage 作为集中存储,所有数据存放在一起,方便管理、扩展和备份。
• Grafana 只需要连接 vmstorage,而不需要管理多个 Prometheus 数据源。
✅ 支持长时间存储和查询优化
• Prometheus 本地存储受限于磁盘大小和保留策略,而 vmstorage 可以更长时间存储数据。
• vmstorage(VictoriaMetrics)在查询大规模数据时更优化,查询性能比 Prometheus TSDB 更好。
✅ 可扩展性强
• vmstorage 可以水平扩展(通过 vminsert + vmselect + vmstorage 分层架构),适用于大规模监控数据。
缺点
❌ Remote-Write 可能带来写入压力
• Prometheus 需要将数据批量写入 vmstorage,如果网络抖动或者写入速率过高,可能导致数据丢失或积压。
• 需要调优 remote_write 缓冲区 (queue_config) 以适应高吞吐。
❌ 集中存储单点风险
• vmstorage 作为单点,可能成为瓶颈。如果 vmstorage 挂了,所有集群的历史数据都无法访问。
• 需要高可用方案,例如多副本存储、备份策略。
❌ 跨区域网络开销
• 如果集群分布在不同区域,跨区域写入 vmstorage 可能有延迟和带宽成本。
方案 2:各集群 Prometheus 本地存储,Grafana 统一查询
架构
• 各个集群独立运行 Prometheus,并本地存储数据。
• Grafana 配置多个数据源,每个 Prometheus 作为独立的数据源。
优点
✅ 各集群完全独立,降低单点风险
• 每个集群的 Prometheus 自己存储数据,即使某个 Prometheus 挂了,其他集群不受影响。
• 网络问题不会影响其他集群的数据存储。
✅ 本地查询更快
• Prometheus 本地查询数据,比远程查询更快(避免 remote_read 可能带来的延迟)。
• 适用于数据量较小、查询需求不复杂的环境。
✅ 网络流量更少
• 监控数据不会跨集群传输,避免了 remote_write 带来的带宽消耗,适合跨数据中心场景。
缺点
❌ 存储管理分散
• 每个 Prometheus 自己存储数据,无法进行全局去重或存储优化。
• 需要为每个集群分配足够的磁盘空间,否则可能因为存储不足丢失数据。
❌ 查询复杂度增加
• Grafana 需要配置多个数据源,每次查询可能需要手动选择不同的数据源,或者使用 prometheus federation 进行部分聚合。
• 例如,想要跨多个集群计算某个服务的 QPS 之和时,需要在 Grafana 进行多个 Prometheus 查询合并。
❌ 数据保留受限
• Prometheus 本地存储数据通常只保留 15 天~30 天(受磁盘空间影响),不适合长期历史数据分析。
瓶颈对比
| 方案 | 存储瓶颈 | 查询瓶颈 | 网络开销 | 维护难度 | 可用性 |
|---|---|---|---|---|---|
| 方案 1:remote-write 到 vmstorage | vmstorage 可能成为写入瓶颈 | 查询时可能受集中存储压力影响,但优化后较好 | Remote-Write 可能带来带宽和延迟 | 需要集中管理 vmstorage | 需要 vmstorage 高可用,否则影响全局数据 |
| 方案 2:Prometheus 本地存储 | 各个 Prometheus 需要管理本地存储空间 | Grafana 查询多个数据源时可能较慢 | 无跨集群网络消耗 | 需要管理多个 Prometheus 数据源 | 各个集群独立,单点故障影响较小 |
适用场景
• 如果你希望全局数据统一存储,方便管理、长期存储历史数据,并优化查询性能,建议选择 方案 1(remote-write 到 vmstorage)。
• 如果你的集群相对独立,想要避免集中存储的单点问题,并且可以接受 Grafana 查询多个数据源的复杂性,建议选择 方案 2(本地存储)。
elastic 多版本部署
eck-operator
部署 eck-operator
- 如何部署 operaotr
- crds.yaml
- operator.yaml
- 默认部署在 elastic-system 下
- 更多 eck-operator 知识
部署 elastic
-
-
自定义 elastic 计算资源 +cpu、memory 、+jvm、+elastic config
-
自定义 pod 资源 + cpu、memory
-
node.processors # Elasticsearch 会自动检测处理器数量并根据该数量设置线程池设置,所以 elastic 要配置 cpu 的 limit,配置后 node.processors,会取用该值。如果不设置,则会使用节点的核心数

-
-
-
默认情况下,Elasticsearch 使用内存映射 (
mmap) 来高效访问索引,linux 默认值太低,会导致 Elasticsearch 无法正常工作,可能会导致内存不足异常# quickstart 默认是禁用的 node.store.allow_mmap: false # 禁用,会影响性能 # 生产环境建议配置 vm.max_map_count to 262144 # 我看产品是利用 initcontainer 设置的 node.store.allow_mmap unset vm.max_map_count=262144 可以直接在主机上设置内核设置,也可以通过必须具有特权的专用 init 容器或专用 Daemonset 进行设置
-
-
-
elastic 有三个配置文件: config_format
-
elasticsearch.yml用于配置 Elasticsearch -
jvm.options用于配置 Elasticsearch JVM 设置 -
log4j2.properties用于配置 Elasticsearch 日志记录
-
-
部署 logstash
elastic 部署方式
docker 方式
helm 部署 elastic
cr 方式部署 es 6.8.23
-
# 不支持 node.roles 的写法,7.x 才支持,示例: node.master: false node.data: false node.ingest: true -
elastic cr 编排文件示例
# 7.x nodeSets: - config: node.roles: - data - master - ingest - ml # 7 才开始支持 - data_cold - data_content - data_frozen - data_hot - data_warm - remote_cluster_client - transform # 6.x nodeSets: - config: node.master: true # 是否作为 Master 节点 node.data: true # 是否存储数据 node.ingest: true # 是否支持 Ingest 预处理 node.attr.data: hot cluster.remote.connect: false # 是否支持 es 集群远程集群连接 🛠 说明 1. node.master、node.data、node.ingest 取代 node.roles • node.master: true → 该节点可参与主节点选举 • node.data: true → 该节点可存储索引数据 • node.ingest: true → 该节点可用于预处理 pipeline • node.ml: true → 7.x 才有 ML 角色,6.x 可以去掉 2. 远程集群 (remote_cluster_client) 相关设置 • Elasticsearch 7.x: 需要 cluster.remote.connect: true • Elasticsearch 6.x: 远程集群连接在 node.data 角色的 Data 节点上进行,不需要 remote_cluster_client 3. 缺失的 data_hot, data_warm, data_cold, data_frozen • 在 7.x 及更早版本,没有 data_hot, data_warm, data_cold, data_frozen 这些角色,它们在 7.x 只是标签(node attributes),而不是角色。 • 你可以改用 node.attr 方式标记: node.attr.data: hot • 这样你仍然可以在 ILM(Index Lifecycle Management)策略中使用 data 节点进行分层存储。 -
- elastic6: docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.23 # 下载 ✅
- elastic8: docker pull docker.elastic.co/elasticsearch/elasticsearch:8.16.3 # 下载 ✅
-
elastic-6823 编排文件
apiVersion: elasticsearch.k8s.elastic.co/v1 kind: Elasticsearch metadata: name: elastic-6822 spec: version: 6.8.22 image: 10.29.14.196/elastic.m.daocloud.io/elasticsearch/elasticsearch:6.8.22 nodeSets: - name: elasticsearch count: 1 volumeClaimTemplates: - metadata: name: elasticsearch-data spec: accessModes: - ReadWriteOnce resources: requests: storage: 30Gi storageClassName: nfs-csi config: node.master: true node.data: true node.ingest: true node.attr.data: hot cluster.remote.connect: false processors: 2 podTemplate: spec: containers: - name: elasticsearch env: - name: ES_JAVA_OPTS value: -Xms2g -Xmx2g resources: requests: memory: 4Gi cpu: 1 limits: memory: 4Gi monitoring: logs: {} metrics: {} auth: {} http: service: metadata: {} spec: ports: - name: https port: 9200 protocol: TCP targetPort: 9200 type: ClusterIP tls: certificate: {} -
elastic-8163 cr 编排文件
apiVersion: elasticsearch.k8s.elastic.co/v1 kind: Elasticsearch metadata: name: elastic-8163 spec: version: 8.16.3 image: 10.29.14.196/elastic.m.daocloud.io/elasticsearch/elasticsearch:8.16.3 nodeSets: - name: data count: 3 volumeClaimTemplates: - metadata: name: elasticsearch-data spec: accessModes: - ReadWriteOnce resources: requests: storage: 30Gi storageClassName: nfs-csi config: node.roles: - data - master - ingest - ml - data_cold - data_content - data_frozen - data_hot - data_warm - remote_cluster_client - transform node.processors: 2 podTemplate: spec: containers: - name: elasticsearch env: - name: ES_JAVA_OPTS value: -Xms2g -Xmx2g resources: requests: memory: 4Gi cpu: 1 limits: memory: 4Gi initContainers: - command: - sh - -c - sysctl -w vm.max_map_count=262144 name: sysctl resources: {} securityContext: privileged: true runAsUser: 0 monitoring: logs: {} metrics: {} auth: {} http: service: metadata: {} spec: ports: - name: https port: 9200 protocol: TCP targetPort: 9200 type: ClusterIP tls: certificate: {}
elastic-prometheus-exporter
- metrics 监控,elastic 不同版本都是通用的,替换下对应的 matchLabels 和 elastic 的 svc 地址即可
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
jobLabel: node-exporter
operator.insight.io/managed-by: insight
release: insight-agent
name: elastic-8163-prometheus-exporter
namespace: default
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 30s
port: prometheus
scheme: http
scrapeTimeout: 30s
namespaceSelector:
any: true
selector:
matchLabels:
elasticsearch.k8s.elastic.co/exporter-cluster-name: elastic-8163
---
apiVersion: v1
kind: Service
metadata:
labels:
elasticsearch.k8s.elastic.co/exporter-cluster-name: elastic-8163
name: elastic-8163-prometheus-exporter
namespace: default
spec:
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: prometheus
port: 9114
protocol: TCP
targetPort: 9114
selector:
elasticsearch.k8s.elastic.co/exporter-cluster-name: elastic-8163
sessionAffinity: None
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mcamel-elasticsearch-cluster-exporter
name: elastic-8163-exporter
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: mcamel-elasticsearch-cluster-exporter
elasticsearch.k8s.elastic.co/exporter-cluster-name: elastic-8163
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: mcamel-elasticsearch-cluster-exporter
elasticsearch.k8s.elastic.co/exporter-cluster-name: elastic-8163
spec:
containers:
- command:
- /bin/elasticsearch_exporter
- --es.uri=https://elastic-8163-es-http.default.svc.cluster.local:9200
- --es.all
- --es.ssl-skip-verify
env:
- name: ES_USERNAME
value: elastic
- name: ES_PASSWORD
valueFrom:
secretKeyRef:
key: elastic
name: elastic-8163-es-elastic-user
image: 10.29.14.196/quay.m.daocloud.io/prometheuscommunity/elasticsearch-exporter:v1.5.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 9114
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
name: mcamel-elasticsearch-cluster-exporter
ports:
- containerPort: 9114
name: prometheus
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 9114
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 25m
memory: 64Mi
securityContext:
capabilities:
drop:
- SETPCAP
- MKNOD
- AUDIT_WRITE
- CHOWN
- NET_RAW
- DAC_OVERRIDE
- FOWNER
- FSETID
- KILL
- SETGID
- SETUID
- NET_BIND_SERVICE
- SYS_CHROOT
- SETFCAP
readOnlyRootFilesystem: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
fsGroup: 10000
runAsGroup: 10000
runAsNonRoot: true
runAsUser: 10000
terminationGracePeriodSeconds: 30
elastic 部署报错记录
- node.processors 参数错误
[2025-02-10T10:19:36,360][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [elastic-6822-es-elasticsearch-0] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalArgumentException: unknown setting [node.processors] please check that any required plugins are installed, or check the breaking changes documentation for removed settings
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124) ~[elasticsearch-cli-6.8.22.jar:6.8.22]
at org.elasticsearch.cli.Command.main(Command.java:90) ~[elasticsearch-cli-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:116) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:93) ~[elasticsearch-6.8.22.jar:6.8.22]
Caused by: java.lang.IllegalArgumentException: unknown setting [node.processors] please check that any required plugins are installed, or check the breaking changes documentation for removed settings
at org.elasticsearch.common.settings.AbstractScopedSettings.validate(AbstractScopedSettings.java:530) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.common.settings.AbstractScopedSettings.validate(AbstractScopedSettings.java:475) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.common.settings.AbstractScopedSettings.validate(AbstractScopedSettings.java:446) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.common.settings.AbstractScopedSettings.validate(AbstractScopedSettings.java:417) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.common.settings.SettingsModule.<init>(SettingsModule.java:148) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.node.Node.<init>(Node.java:374) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.node.Node.<init>(Node.java:266) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:212) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:212) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:333) ~[elasticsearch-6.8.22.jar:6.8.22]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:159) ~[elasticsearch-6.8.22.jar:6.8.22]
... 6 more
# 6.x 版本不支持这种写法,7.x 开始才支持的
- processors: 2 # 这才是 6 的写法
什么是 skywalking (数据来源 OpenAI) ?
介绍
- SkyWalking 是一个开源的应用性能监控系统
- 由 Apache 软件基金会孵化,并成为 Apache 孵化器的顶级项目
- SkyWalking 的目标是帮助开发人员监控、诊断和优化分布式系统的性能和健康状况
特性
- SkyWalking 提供了一种分布式追踪解决方案
- 可以追踪和监控分布式应用程序中的各个组件之间的调用和交互
- 通过插入特定的代理或 SDK 到应用程序中,来收集关于请求流经系统的详细信息,
- 包括服务间调用、
- 数据库访问
- 消息队列等
- 这些信息可以用于分析应用程序性能、识别瓶颈和故障,并提供可视化的监控仪表板和警报系统。
- SkyWalking 还提供了一些附加功能
- 应用程序拓扑图
- 性能指标收集
- 分布式日志跟踪等
- 它支持多种编程语言和框架,包括 Java、.NET、Node.js、Go、Python 等,可以适用于各种分布式系统和微服务架构。总之 SkyWalking 是一个用于监控和诊断分布式应用程序性能的开源工具,它可以帮助开发人员更好地理解和优化复杂的分布式系统。
核心组件
-
Collector:Collector 是 SkyWalking 的数据收集器
- 负责接收和处理来自应用程序的跟踪数据
- 可以通过配置多个实例以实现高可用性和负载均衡
-
Storage:Storage 组件用于接收和存储从 Collector 收集到的跟踪数据和指标数据
- 支持多种存储后端
- Elasticsearch、
- MySQL、
- H2 等
- 支持多种存储后端
-
UI:UI 组件提供了一个用户界面,用于展示和查询监控数据。可以通过 UI 组件查看应用程序的拓扑图、性能指标、调用链追踪等信息。
-
Probe:Probe 组件是用于与应用程序集成的代理或 SDK。它负责在应用程序中收集跟踪数据,并将其发送给 Collector 进行处理和存储。
-
除了这些核心组件之外,SkyWalking 还提供了一些可选的扩展组件和插件,用于增强功能和支持特定的场景
例如:
- Alarm:Alarm 组件提供了警报功能,可以基于自定义的规则和阈值触发警报,帮助用户及时发现和解决潜在的问题。
- Analysis:Analysis 组件提供了数据分析功能,可以对跟踪数据和指标数据进行统计和分析,帮助用户理解应用程序的性能状况和趋势。
- Plugin:Plugin 组件是一种可扩展机制,允许用户根据需要添加自定义的插件,以支持特定的框架、中间件或协议。
需要注意的是,SkyWalking 的组件可以根据版本和配置的不同而有所变化。以上列出的是一些常见的组件,具体的组件列表和功能可以在官方文档或项目的 GitHub 页面中找到。
Skywalking 部署
Docker
-
克隆项目到本地
root@worker01 ~]# git clone https://github.com/apache/skywalking.git 正克隆到 'skywalking'... remote: Enumerating objects: 280249, done. remote: Counting objects: 100% (1566/1566), done. remote: Compressing objects: 100% (711/711), done. remote: Total 280249 (delta 608), reused 1467 (delta 558), pack-reused 278683 接收对象中: 100% (280249/280249), 164.34 MiB | 6.83 MiB/s, done. 处理 delta 中: 100% (109846/109846), done. -
修改 .env 内镜像版本并部署
[root@worker01 ~]# cd skywalking/docker [root@worker01 docker]# cat .env ES_VERSION=7.4.2 OAP_IMAGE=apache/skywalking-oap-server:latest UI_IMAGE=apache/skywalking-ui:latest [root@worker01 docker]# docker-compose up -d -
检查组件状态
[root@worker01 docker]# docker-compose ps NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS elasticsearch docker.elastic.co/elasticsearch/elasticsearch-oss:7.4.2 "/usr/local/bin/dock…" elasticsearch 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 9300/tcp oap apache/skywalking-oap-server:latest "bash docker-entrypo…" oap 2 minutes ago Up About a minute (healthy) 0.0.0.0:11800->11800/tcp, :::11800->11800/tcp, 1234/tcp, 0.0.0.0:12800->12800/tcp, :::12800->12800/tcp ui apache/skywalking-ui:latest "bash docker-entrypo…" ui 2 minutes ago Up About a minute 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp
Kubernetes
-
克隆项目到本地
[root@master01 ~]# git clone https://github.com/apache/skywalking-kubernetes.git -
通过 –set 指定镜像版本并部署
[root@master01 ~]# cd skywalking-kubernetes/ [root@master01 skywalking-kubernetes]# helm install skywalking -n skywalking chart/skywalking --set oap.image.tag=9.4.0 --set ui.image.tag=9.4.0 --set oap.storageType=elasticsearch -f chart/skywalking/values.yaml NAME: skywalking LAST DEPLOYED: Fri Jun 2 14:23:10 2023 NAMESPACE: skywalking STATUS: deployed REVISION: 1 NOTES: ************************************************************************ * * * SkyWalking Helm Chart by SkyWalking Team * * * ************************************************************************ Thank you for installing skywalking-helm. Your release is named skywalking. Learn more, please visit https://skywalking.apache.org/ Get the UI URL by running these commands: echo "Visit http://127.0.0.1:8080 to use your application" kubectl port-forward svc/skywalking-skywalking-helm-ui 8080:80 --namespace skywalking # 已经更改为 NodePort 可忽略 ################################################################################# ###### WARNING: Persistence is disabled!!! You will lose your data when ##### ###### the SkyWalking's storage ES pod is terminated. ##### ################################################################################# -
自定义 values.yaml 参数
- OAP 服本书调整为 1 oap: name: oap image: repository: skywalking.docker.scarf.sh/apache/skywalking-oap-server tag: null # Must be set explicitly pullPolicy: IfNotPresent storageType: null ports: grpc: 11800 rest: 12800 replicas: 1 - UI Service 类型更改为 NodePort ui: name: ui replicas: 1 image: repository: skywalking.docker.scarf.sh/apache/skywalking-ui tag: null # Must be set explicitly pullPolicy: IfNotPresent nodeAffinity: {} nodeSelector: {} tolerations: [] service: type: NodePort - UI Deployment.containers.env.name.SW_OAP_ADDRESS 需要更改为 http://cluserip:12800,默认配置启动后 ui.log 提示连接 oap:12800 failed
UI 界面(9.4.0)


SkyWalking Metrics 索引异常排查报告
一、问题概述
2026 年 7 月 24 日,Java 应用重启后,SkyWalking UI 中无法正常看到原有服务及实例信息。
同时,SkyWalking OAP 持续出现以下告警:
Metric: service_cpm values size is not equal to duration points size,
metrics values size: 0, duration points size: 31
Metric: service_instance_cpm values size is not equal to duration points size,
metrics values size: 0, duration points size: 31
涉及的主要指标包括:
service_cpm
service_sla
service_apdex
service_resp_time
service_instance_cpm
service_instance_sla
service_instance_resp_time
从界面现象看,问题一度表现为 Java 应用重启后未成功注册到 SkyWalking。
二、问题发生前的变更
2026 年 7 月 23 日,为释放 Elasticsearch 存储空间,人工删除了部分 SkyWalking 历史索引。
删除的 Trace 索引包括:
sw_segment-20260721
sw_segment-20260722
删除的 Metrics 索引包括:
sw_metrics-all-20260717
sw_metrics-all-20260718
sw_metrics-all-20260719
sw_metrics-all-20260720
sw_metrics-all-20260721
sw_metrics-all-20260722
删除后,部分历史 Metrics 索引再次被创建,但索引内文档数为 0:
sw_metrics-all-20260720 docs.count=0
sw_metrics-all-20260721 docs.count=0
sw_metrics-all-20260722 docs.count=0
当前日期的 Metrics 索引仍在正常写入:
sw_metrics-all-20260723 docs.count=12438965 size=4.6GB
sw_metrics-all-20260724 docs.count=2524054 size=1GB
三、排查过程
3.1 Java Agent 加载正常
Java Agent 日志中可见:
SkyWalking agent version:
8.16.0-dominos-1.0.0-SNAPSHOT
Agent 启动后虽然短暂处于:
DISCONNECT
但随后正常选择 OAP Collector,并建立 gRPC 通道。
由此可以确认:
- Java Agent 已正常加载;
- Java 启动参数中的
-javaagent已生效; - Agent 插件初始化正常。
3.2 Agent 到 OAP 的通信链路正常
Agent 已成功连接 OAP:
skywalking-skywalking-helm-oap.skywalking.svc.cluster.local:11800
Agent 向 OAP 上报 Event 数据时,返回:
HTTP status: 200
grpc-status: 0
Agent 上报 JVM Metrics 时,同样返回:
HTTP status: 200
grpc-status: 0
其中:
grpc-status: 0
表示 gRPC 请求处理成功。
因此可以排除:
- Java Agent 未加载;
- OAP 地址配置错误;
- Kubernetes DNS 异常;
- Java Pod 到 OAP 11800 端口不通;
- OAP gRPC 服务不可用;
- Agent 上报被 OAP 拒绝。
结论:
Java Agent → OAP
链路正常。
3.3 当前 Metrics 写入正常
sw_metrics-all-20260724 已持续写入数据,说明以下链路正常:
Java Agent
↓
OAP 11800
↓
Metrics 聚合
↓
Elasticsearch
因此可以确认:
- 当前 Metrics 数据仍在持续写入;
- OAP 到 Elasticsearch 的存储链路正常;
- 问题不是 Metrics 全局停止写入;
- 问题不是 Java 应用真正无法上报。
3.4 当前时间查询仍返回空指标
本次在 SkyWalking UI 中查看的是当前时间范围,并未主动查询已删除日期的历史数据。
但 OAP 仍持续出现:
metrics values size: 0
duration points size: 31
这里的:
duration points size: 31
表示当前查询时间窗口被划分为 31 个采样点,并不代表查询了 31 天,也不能据此判断查询范围包含历史日期。
因此,本次告警不能简单解释为:
UI 查询了已经被删除的历史数据。
结合实际现象,更符合情况的解释是:
- 人工删除
sw_metrics-all-*索引后,OAP 对 Metrics 索引集合的识别或查询出现异常; - 即使查询的是当前时间,OAP 仍无法正常获得服务、实例及对应指标;
- 最终表现为服务列表消失、实例不可见以及当前指标查询为空。
3.5 OAP 出现 Alias 获取失败
OAP 日志中发现:
AliasClient - Failed to get indices by alias sw_metrics-all
该日志说明 OAP 在通过:
sw_metrics-all
获取关联 Metrics 索引时发生失败。
虽然没有单独删除 Alias,但删除 Elasticsearch Index 时,该 Index 与 Alias 的关联关系也会同步移除。
结合以下现象:
- 人工删除了多个
sw_metrics-all-*Index; - OAP 出现
Failed to get indices by alias sw_metrics-all; - 原有服务和实例在 SkyWalking UI 中消失;
- 部分历史 Index 后续被重新创建为空索引;
- 当前日期 Index 仍可正常写入;
可以判断,人工删除操作造成了 SkyWalking Metrics 索引集合及 Alias 查询状态的阶段性异常。
现有日志能够确认 Alias 获取曾失败,但不足以证明 Alias 被永久损坏。
四、根因分析
4.1 已确认事实
本次排查已确认:
- Java Agent 正常加载;
- Agent 到 OAP 的 gRPC 链路正常;
- Event 和 JVM Metrics 上报成功;
- OAP 返回
grpc-status: 0; - 当前日期 Metrics Index 持续写入;
- 异常发生前人工删除了多个
sw_metrics-all-*Index; - 删除后 OAP 出现:
Failed to get indices by alias sw_metrics-all
- 删除后原有服务和实例无法在 UI 中正常显示;
- 部分被删除的历史 Metrics Index 被重新创建为空索引。
4.2 根因判断
本次问题的直接诱因是:
人工删除 SkyWalking 自主管理的
sw_metrics-all-*历史 Index。
删除操作一方面造成历史 Metrics 数据永久丢失,另一方面影响了 OAP 对 sw_metrics-all 索引集合的识别和查询。
在此期间,OAP 曾无法通过 sw_metrics-all Alias 正常获取关联索引,导致 SkyWalking UI 无法正常加载原有服务、实例及当前指标信息。
因此,即使查询的是当前时间范围,也会出现:
metrics values size: 0
duration points size: 31
并表现为:
- 原有服务列表消失;
- Java 应用重启后看不到新实例;
- 当前服务指标为空;
- 界面上类似应用未注册。
4.3 更准确的故障描述
本次问题不应描述为:
Java 应用重启后无法注册 SkyWalking。
更准确的描述是:
Java Agent 已正常连接 OAP 并持续上报数据,但人工删除
sw_metrics-all-*Index 后,OAP 对 Metrics 索引集合及 Alias 的查询出现阶段性异常,导致 SkyWalking UI 无法正常展示原有服务、实例及当前指标,从界面表现上类似应用未注册。
4.4 故障链路
人工删除 sw_metrics-all-* Index
↓
历史 Metrics 数据丢失
↓
Index 与 Alias 的关联关系发生变化
↓
OAP 获取 sw_metrics-all 关联索引失败
↓
服务、实例及当前 Metrics 查询异常
↓
SkyWalking UI 中原有服务和实例消失
↓
当前时间查询返回 values size=0
↓
表现为 Java 应用未注册或无数据
五、处理方案
5.1 调整 Metrics TTL
SkyWalking OAP 配置文件中:
metricsDataTTL: ${SW_CORE_METRICS_DATA_TTL:7}
其中:
7
只是默认值。
OAP Deployment 已增加:
- name: SW_CORE_METRICS_DATA_TTL
value: "3"
因此实际生效配置为:
metricsDataTTL=3 天
增加该环境变量并完成 OAP Pod 滚动更新后,SkyWalking 已能够自动删除超过 3 天保留周期的 Metrics Index。
处理流程如下:
修改 OAP Deployment
↓
增加 SW_CORE_METRICS_DATA_TTL=3
↓
滚动更新 OAP Pod
↓
OAP 加载 metricsDataTTL=3
↓
SkyWalking TTL 任务执行
↓
自动删除超过保留周期的 Metrics Index
5.2 停止人工删除 SkyWalking Index
后续不再人工执行:
DELETE sw_metrics-all-*
也不建议使用:
DELETE sw*
SkyWalking 对 Elasticsearch Index 有自身的:
- Alias 管理;
- 时间分片管理;
- TTL 管理;
- Mapping 管理;
- 索引初始化和维护逻辑。
人工删除可能造成:
- 历史 Metrics 数据丢失;
- Alias 查询异常;
- 服务和实例列表异常;
- 空 Index 被重新创建;
- OAP 持续出现 MQE WARN。
5.3 历史数据缺失期间的查询建议
历史 Metrics 数据已经被人工删除,无法通过重新创建空 Index 恢复。
在历史数据缺失期间,SkyWalking UI 建议优先查看:
最近 15 分钟
最近 1 小时
最近 24 小时
用于确认当前服务、实例和指标是否恢复正常。
六、处理结果
当前状态如下:
Java Agent 正常
Agent → OAP 11800 正常
OAP gRPC 接收 正常
OAP → ES 当前 Metrics 写入 正常
当前 Metrics Index 正常增长
历史 Metrics 数据 部分已人工删除,无法直接恢复
Alias 获取 删除后曾出现阶段性失败
Metrics TTL 已调整为 3 天
历史 Index 清理 已由 SkyWalking 自动执行
Java 应用是否需要重启 不需要
七、后续措施
-
SkyWalking Metrics Index 统一通过
SW_CORE_METRICS_DATA_TTL管理,不再人工删除。 -
如需调整数据保留周期,统一修改 OAP Deployment 中的 TTL 环境变量。
-
索引清理前必须确认:
- Index 类型;
- Index 日期;
- 是否仍处于 SkyWalking TTL 管理范围;
- Alias 关联关系;
- 删除后对服务、实例、Metrics 和 Trace 查询的影响。
-
增加以下监控项:
- Metrics Index 每日增长量;
- 当前日期 Index 文档增长速率;
- OAP Alias 查询失败;
- OAP MQEVisitor WARN;
- Elasticsearch Bulk 写入失败;
- TTL 清理执行结果。
八、最终结论
本次异常不是 Java Agent 注册失败。Java Agent 到 OAP 的 gRPC 链路以及当前 Metrics 写入均正常。根因是人工删除 SkyWalking 管理的
sw_metrics-all-*Index 后,历史数据丢失,并造成 OAP 对sw_metrics-all索引集合及 Alias 的获取出现阶段性异常,最终导致 SkyWalking UI 无法正常展示原有服务、实例和当前指标。现已通过SW_CORE_METRICS_DATA_TTL=3将 Metrics 保留周期调整为 3 天,并验证 SkyWalking 能够自动清理超过保留周期的历史 Index。后续统一使用 SkyWalking TTL 机制管理索引生命周期。
什么是 NeuVector ?
NeuVector 是一款专门为容器安全而设计的安全平台,提供全面的容器安全防御和威胁检测。它使用了一系列高级技术,如深度学习和情境感知等,来识别和预防各种安全威胁,并在发现异常行为时进行及时报警和响应。
-
该平台特点
- 对容器内部对网络流量进行监控和分析
- 自动检测和阻止恶意行为和攻击,确保容器环境的安全性,漏洞管理等
- 对容器运行时防御、容器镜像扫描和安全策略管理
- 可视化的安全策略管理工具,使用户更好地管理和调整安全策略
-
组件
- Manager:为用户提供了统一的管理 UI,便于用户查看安全事件、管理安全解决方案、规则等
- Controller:Backend 服务器及控制器,管理如 Enforcer、Scanner 等其他组件,分发安全策略及调度扫描任务
- Scanner:用户执行漏洞扫描、基线扫描等任务
- Enforcer:一个轻量级的容器,用于拦截系统事件,执行安全策略等。通常以 Daemon set 运行再集群中的每个节点上
- Updater:用于更新 CVE 数据库
NeuVector 支持多种容器平台
- Docker
- Kubernetes
- OpenShift
NeuVector 安装
添加 NeuVector 的 repo 及检索版本
[root@master01 ~]# helm repo add neuvector https://neuvector.github.io/neuvector-helm/
"neuvector" has been added to your repositories
[root@master01 ~]# helm search repo neuvector/core
NAME CHART VERSION APP VERSION DESCRIPTION
neuvector/core 2.4.5 5.1.3 Helm chart for NeuVector's core services
[root@master01 ~]# helm search repo neuvector/core -l
NAME CHART VERSION APP VERSION DESCRIPTION
neuvector/core 2.4.5 5.1.3 Helm chart for NeuVector's core services
neuvector/core 2.4.4 5.1.3 Helm chart for NeuVector's core services
neuvector/core 2.4.3 5.1.2 Helm chart for NeuVector's core services
neuvector/core 2.4.2 5.1.1 Helm chart for NeuVector's core services
neuvector/core 2.4.1 5.1.0 Helm chart for NeuVector's core services
neuvector/core 2.4.0 5.1.0 Helm chart for NeuVector's core services
neuvector/core 2.2.5 5.0.5 Helm chart for NeuVector's core services
neuvector/core 2.2.4 5.0.4 Helm chart for NeuVector's core services
neuvector/core 2.2.3 5.0.3 Helm chart for NeuVector's core services
neuvector/core 2.2.2 5.0.2 Helm chart for NeuVector's core services
neuvector/core 2.2.1 5.0.1 Helm chart for NeuVector's core services
neuvector/core 2.2.0 5.0.0 Helm chart for NeuVector's core services
neuvector/core 1.9.2 4.4.4-s2 Helm chart for NeuVector's core services
neuvector/core 1.9.1 4.4.4 Helm chart for NeuVector's core services
neuvector/core 1.9.0 4.4.4 Helm chart for NeuVector's core services
neuvector/core 1.8.9 4.4.3 Helm chart for NeuVector's core services
neuvector/core 1.8.8 4.4.2 Helm chart for NeuVector's core services
neuvector/core 1.8.7 4.4.1 Helm chart for NeuVector's core services
neuvector/core 1.8.6 4.4.0 Helm chart for NeuVector's core services
neuvector/core 1.8.5 4.3.2 Helm chart for NeuVector's core services
neuvector/core 1.8.4 4.3.2 Helm chart for NeuVector's core services
neuvector/core 1.8.3 4.3.2 Helm chart for NeuVector's core services
neuvector/core 1.8.2 4.3.1 Helm chart for NeuVector's core services
neuvector/core 1.8.0 4.3.0 Helm chart for NeuVector's core services
neuvector/core 1.7.7 4.2.2 Helm chart for NeuVector's core services
neuvector/core 1.7.6 4.2.2 Helm chart for NeuVector's core services
neuvector/core 1.7.5 4.2.0 Helm chart for NeuVector's core services
neuvector/core 1.7.2 4.2.0 Helm chart for NeuVector's core services
neuvector/core 1.7.1 4.2.0 Helm chart for NeuVector's core services
neuvector/core 1.7.0 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.9 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.8 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.7 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.6 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.5 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.4 4.0.0 Helm chart for NeuVector's core services
neuvector/core 1.6.1 4.0.0 NeuVector Full Lifecycle Container Security Pla...
创建 namespace 及安装
[root@master01 ~]# kubectl create namespace neuvector
namespace/neuvector created
[root@master01 ~]# kubectl label namespace neuvector "pod-security.kubernetes.io/enforce=privileged"
namespace/neuvector labeled
[root@master01 ~]# helm install neuvector --namespace neuvector --create-namespace neuvector/core
NAME: neuvector
LAST DEPLOYED: Sat Jun 17 17:40:43 2023
NAMESPACE: neuvector
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Get the NeuVector URL by running these commands:
NODE_PORT=$(kubectl get --namespace neuvector -o jsonpath="{.spec.ports[0].nodePort}" services neuvector-service-webui)
NODE_IP=$(kubectl get nodes --namespace neuvector -o jsonpath="{.items[0].status.addresses[0].address}")
echo https://$NODE_IP:$NODE_PORT
[root@master01 ~]# NODE_PORT=$(kubectl get --namespace neuvector -o jsonpath="{.spec.ports[0].nodePort}" services neuvector-service-webui)
[root@master01 ~]# NODE_IP=$(kubectl get nodes --namespace neuvector -o jsonpath="{.items[0].status.addresses[0].address}")
[root@master01 ~]# echo https://$NODE_IP:$NODE_PORT
https://10.2x.16.x:30196
依赖镜像
docker.io/neuvector/controller:5.1.3
docker.io/neuvector/enforcer:5.1.3
docker.io/neuvector/manager:5.1.3
docker.io/neuvector/scanner:latest
登录UI
- 默认:admin/admin

报告

Gitlab 仓库安装 (centos7.9)
安装 docker
-
略,毛毛雨啦,详情参考 Install
-
docker 部署
-
创建 repo 目录来存放 gitlab 数据
mkdir /gitlab-data export GITLAB_HOME=/gitlab-data -
启动容器 dockerhub
sudo docker run --detach \ --hostname mawb.gitlab.com \ --publish 443:443 --publish 80:80 \ --name mawb.gitlab \ --restart always \ --volume $GITLAB_HOME/config:/etc/gitlab \ --volume $GITLAB_HOME/logs:/var/log/gitlab \ --volume $GITLAB_HOME/data:/var/opt/gitlab \ --shm-size 256m \ gitlab/gitlab-ce:14.8.6-ce.0 -
初始密码
docker exec -it $containerID /bin/cat /etc/gitlab/initial_root_password
-
-
允许 80、443 访问,并禁止 IP 访问
-
允许 80、443
- gitlab 使用 gitlab.rb 的形式来自定义 gitlab_server 配置 - 修改以下配置 [root@gitlab-repo-1 data]# pwd /gitlab-home/data [root@gitlab-repo-1 data]# cat config/gitlab.rb | grep -v '^#' | grep '[a-z]' external_url 'https://mawb.gitlab.com' # 域名访问,也可以 IP,会自动生成 nginx 配置 nginx['custom_nginx_config'] = "include /var/opt/gitlab/nginx/conf/http.conf;" # 自定义 nginx 配置(容器内路径),开启 80,所以修改 letsencrypt['enable'] = false # 禁用 letsencrypt letsencrypt['auto_renew'] = false # 禁用自动续签证书,这步可以不用 nginx['ssl_certificate'] = "/etc/gitlab/ssl/mawb.gitlab.com.crt" # pem、crt nginx['ssl_certificate_key'] = "/etc/gitlab/ssl/mawb.gitlab.com.key" # key -
禁止 IP 访问 disalble_IP_access
- 需要在 nginx 配置文件中加入以下配置 server { listen *:80 default_server; listen *:443 default_server; server_name _; return 403; ssl_certificate /etc/gitlab/ssl/mawb.gitlab.com.crt; ssl_certificate_key /etc/gitlab/ssl/mawb.gitlab.com.key; } -
自签证书 ssl
-
配置生效
- 容器内查看当前服务状态 root@10:~# gitlab-ctl status run: alertmanager: (pid 1753) 156934s; run: log: (pid 1092) 157346s run: gitaly: (pid 1824) 156918s; run: log: (pid 563) 157688s run: gitlab-exporter: (pid 1713) 156946s; run: log: (pid 1024) 157394s run: gitlab-kas: (pid 5119) 155210s; run: log: (pid 822) 157654s run: gitlab-workhorse: (pid 1699) 156947s; run: log: (pid 978) 157420s run: grafana: (pid 5137) 155209s; run: log: (pid 1486) 157047s run: logrotate: (pid 12675) 2906s; run: log: (pid 508) 157706s run: nginx: (pid 12501) 3007s; run: log: (pid 1000) 157416s run: postgres-exporter: (pid 1762) 156934s; run: log: (pid 1123) 157330s run: postgresql: (pid 595) 157673s; run: log: (pid 607) 157671s run: prometheus: (pid 1723) 156945s; run: log: (pid 1064) 157362s run: puma: (pid 5034) 155360s; run: log: (pid 922) 157449s run: redis: (pid 514) 157702s; run: log: (pid 525) 157699s run: redis-exporter: (pid 1716) 156946s; run: log: (pid 1045) 157377s run: sidekiq: (pid 7973) 5180s; run: log: (pid 938) 157438s run: sshd: (pid 32) 157754s; run: log: (pid 31) 157754s - 重新加载配置 gitlab-ctl reconfigure gitlab-ctl restart - 对 ningx 的修改,也可以单独重启 nginx gitlab-ctl restart nginx && gitlab-ctl status nginx -
重置 root 密码
- 进入容器内部 root@mawb:/# gitlab-rake "gitlab:password:reset[root]" Enter password: Confirm password: Password successfully updated for user with username root. - 重启容器即可 -
禁用 gitlab 中 prometheus 组件(gitlab.rb)
- 编辑 gitlab.rb 配置文件 vi gitlab.rb prometheus_monitoring['enable'] = false # 组件资源占用比较大, - 重新加载配置/重启也可以 gitlab-ctl reconfigure gitlab-ctl restart
-
使用 operator 部署 gitlab
operator 安装
kubectl create namespace gitlab-system
- gitlab-operator 地址
https://gitlab.com/gitlab-org/cloud-native/gitlab-operator/-/releases?after=eyJyZWxlYXNlZF9hdCI6IjIwMjUtMDEtMTYgMTQ6Mjc6MjAuMTM5NTk0MDAwICswMDAwIiwiaWQiOiIxNTU1NjE4OSJ9
- Install-operator
[root@controller-node-1 ~]# kubectl apply -f gitlab-operator.yaml
customresourcedefinition.apiextensions.k8s.io/gitlabs.apps.gitlab.com created
serviceaccount/gitlab-app-nonroot created
serviceaccount/gitlab-manager created
serviceaccount/gitlab-nginx-ingress created
serviceaccount/gitlab-prometheus-server created
clusterrole.rbac.authorization.k8s.io/gitlab-app-role-nonroot created
clusterrole.rbac.authorization.k8s.io/gitlab-metrics-auth-role created
clusterrole.rbac.authorization.k8s.io/gitlab-metrics-reader created
clusterrole.rbac.authorization.k8s.io/gitlab-manager-role created
clusterrole.rbac.authorization.k8s.io/gitlab-nginx-ingress created
clusterrole.rbac.authorization.k8s.io/gitlab-prometheus-server created
clusterrolebinding.rbac.authorization.k8s.io/gitlab-app-rolebinding-nonroot created
clusterrolebinding.rbac.authorization.k8s.io/gitlab-metrics-auth-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/gitlab-manager-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/gitlab-nginx-ingress created
clusterrolebinding.rbac.authorization.k8s.io/gitlab-prometheus-server created
role.rbac.authorization.k8s.io/gitlab-leader-election-role created
role.rbac.authorization.k8s.io/gitlab-nginx-ingress created
rolebinding.rbac.authorization.k8s.io/gitlab-leader-election-rolebinding created
rolebinding.rbac.authorization.k8s.io/gitlab-nginx-ingress created
service/gitlab-controller-manager-metrics-service created
service/gitlab-webhook-service created
deployment.apps/gitlab-controller-manager created
ingressclass.networking.k8s.io/gitlab-nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/gitlab-validating-webhook-configuration created
resource mapping not found for name: "gitlab-serving-cert" namespace: "gitlab-system" from "gitlab-operator.yaml": no matches for kind "Certificate" in version "cert-manager.io/v1"
ensure CRDs are installed first
resource mapping not found for name: "gitlab-selfsigned-issuer" namespace: "gitlab-system" from "gitlab-operator.yaml": no matches for kind "Issuer" in version "cert-manager.io/v1"
ensure CRDs are installed first
# 安装报错,它依赖 cert-manager 组件,估计是跟 https 有关系
# 再次安装过了
[root@controller-node-1 ~]# kubectl apply -f gitlab-operator.yaml
customresourcedefinition.apiextensions.k8s.io/gitlabs.apps.gitlab.com configured
serviceaccount/gitlab-app-nonroot unchanged
serviceaccount/gitlab-manager unchanged
serviceaccount/gitlab-nginx-ingress unchanged
serviceaccount/gitlab-prometheus-server unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-app-role-nonroot unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-metrics-auth-role unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-metrics-reader unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-manager-role unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-nginx-ingress unchanged
clusterrole.rbac.authorization.k8s.io/gitlab-prometheus-server unchanged
clusterrolebinding.rbac.authorization.k8s.io/gitlab-app-rolebinding-nonroot unchanged
clusterrolebinding.rbac.authorization.k8s.io/gitlab-metrics-auth-rolebinding unchanged
clusterrolebinding.rbac.authorization.k8s.io/gitlab-manager-rolebinding unchanged
clusterrolebinding.rbac.authorization.k8s.io/gitlab-nginx-ingress unchanged
clusterrolebinding.rbac.authorization.k8s.io/gitlab-prometheus-server unchanged
role.rbac.authorization.k8s.io/gitlab-leader-election-role unchanged
role.rbac.authorization.k8s.io/gitlab-nginx-ingress unchanged
rolebinding.rbac.authorization.k8s.io/gitlab-leader-election-rolebinding unchanged
rolebinding.rbac.authorization.k8s.io/gitlab-nginx-ingress unchanged
service/gitlab-controller-manager-metrics-service unchanged
service/gitlab-webhook-service unchanged
deployment.apps/gitlab-controller-manager unchanged
ingressclass.networking.k8s.io/gitlab-nginx unchanged
certificate.cert-manager.io/gitlab-serving-cert created
issuer.cert-manager.io/gitlab-selfsigned-issuer created
validatingwebhookconfiguration.admissionregistration.k8s.io/gitlab-validating-webhook-configuration configured
install-gitlab
apiVersion: apps.gitlab.com/v1beta1
kind: GitLab
metadata:
name: gitlab
spec:
chart:
version: "1.6.0"
values:
global:
hosts:
domain: mawb.gitlab.com
ingress:
configureCertmanager: true
certmanager-issuer:
email: weibing.ma@daocloud.io
gitlab 自定义 subpath
- 修改 gitlab.rb 配置文件
vi /etc/gitlab/gitlab.rb
external_url: http://192.168.0.110:32255/gitlab # 这里配置修改下即可,或者是不是有环境变量可以替换
http://192.168.0.110:32255/gitlab
http 协议 ip地址,这个也就是后续外部访问时的IP/域名、端口 、子路径就是 /gitlab,后续 gitlab 就会以该端口对外暴露
master 分支修改推送至 dev 分支
- 本意是修改 dev 分支的 code,修改完成后,发现 clone 错了分支,于是才会有后面的步骤
你可以按照以下步骤操作:
-
确认当前分支(你可能在
main或master):git branch如果当前在
main,你需要切换到dev。 -
切换到
dev分支(如果本地没有dev分支,需要先创建并追踪远程分支):git checkout -b dev origin/dev或者,如果本地已有
dev分支:git checkout dev git pull origin dev # 确保是最新的 -
将修改从
main复制到dev: 如果你的修改已经提交,但还在main分支,可以使用cherry-pick:# 我的还没 commit,直接后的后面的步骤git checkout dev git cherry-pick <commit-id>或者如果你还没有 commit,直接用
stash临时保存后切换:git stash git checkout dev git stash pop -
推送到远程
dev分支:git add . git commit -m "你的提交信息" git push origin dev
这样,你的修改就被提交到 dev 分支,而不会影响 main 分支。
helm 使用笔记
-
env
-
查看本地 helm client 环境变量配置
# 查看 helm env HELM_BIN="helm" HELM_BURST_LIMIT="100" HELM_CACHE_HOME="/root/.cache/helm" HELM_CONFIG_HOME="/root/.config/helm" HELM_DATA_HOME="/root/.local/share/helm" HELM_DEBUG="false" HELM_KUBEAPISERVER="" HELM_KUBEASGROUPS="" HELM_KUBEASUSER="" HELM_KUBECAFILE="" HELM_KUBECONTEXT="" HELM_KUBEINSECURE_SKIP_TLS_VERIFY="false" HELM_KUBETLS_SERVER_NAME="" HELM_KUBETOKEN="" HELM_MAX_HISTORY="10" HELM_NAMESPACE="default" HELM_PLUGINS="/root/.local/share/helm/plugins" HELM_REGISTRY_CONFIG="/root/.config/helm/registry/config.json" HELM_REPOSITORY_CACHE="/root/.cache/helm/repository" HELM_REPOSITORY_CONFIG="/root/.config/helm/repositories.yaml" # helm repo add 的 repo 都会保存在这个文件中 # 查看 repositories.yaml 文件 cat .config/helm/repositories.yaml apiVersion: "" generated: "0001-01-01T00:00:00Z" repositories: - caFile: "" certFile: "" insecure_skip_tls_verify: false keyFile: "" name: postgres-operator-ui-charts pass_credentials_all: false password: "" url: https://opensource.zalando.com/postgres-operator/charts/postgres-operator-ui username: "" - caFile: "" certFile: "" insecure_skip_tls_verify: false keyFile: "" name: elastic pass_credentials_all: false password: "" url: https://helm.elastic.co username: ""
-
-
repo
-
添加 elastic repo 仓库
helm repo add elastic https://helm.elastic.co -
查看 repo 列表
helm repo list -
查看 repo 中所有 chart
# 显示预发布版本 helm search repo elastic --devel # 按版本检索 helm search repo elastic --version ^8 helm search repo elastic --version ^6 # 显示 repo 中具体项目的版本, --versions 可以简写为 -l helm search repo elastic --versions
-
-
pull
-
下在某个版本的 chart
helm pull elastic/elasticsearch --version 7.16.2 # 默认下载最新版本 -
扩展
--untar # 下载后解压 --untardir # 解压到指定路径、默认 ./ --insecure-skip-tls-verify # 跳过 tls 证书 --plain-http # 使用 http
-
-
package
-
打包
# 重新打包为 tgz,主要是针对自定义 template 的场景 helm package ./elasticsearch
-
-
list
-
查看已安装的 release
# 查看所有 namespace 下已经部署的 release,包含 成功/失败、并按 date 排序 helm list -A -a -d
-
title: Harbor 部署与维护 author: bertreyking date: 2023-09-04 keywords: [harbor,docker-compose]
Harbor 部署与维护
下载离线介质
-
wget https://github.com/goharbor/harbor/releases/download/v2.9.0/harbor-offline-installer-v2.9.0.tgz
部署
-
run-installer-script 安装模式
- Just Harbor # 仅安装 Harbor - 默认
- Harbor with Notary # 带镜像签名工具,来保证镜像层在 pull、push、transfer 过程中的一致性和完整性
- Harbor with Clair # 带镜像漏洞扫描
- Harbor with Chart Repository Service # 带 Helm 支持的 Chart 仓库
- Harbor with two or all three of Notary, Clair, and Chart Repository Service # 基本全部打包安装
- Just Harbor sudo ./install.sh - 打包安装全部组件,不需要的可以去掉 --with-xxxxx 对应参数即可 sudo ./install.sh --with-notary --with-clair --with-chartmuseum -
注意事项
⚠️: harbor 默认部署时,会将容器内部端口通过 80、443 暴露需要,请确保节点中不会占用这两个端口,或者提前更改
docker-compose.yml文件proxy: image: goharbor/nginx-photon:v2.7.1 container_name: nginx restart: always cap_drop: - ALL cap_add: - CHOWN - SETGID - SETUID - NET_BIND_SERVICE volumes: - ./common/config/nginx:/etc/nginx:z - type: bind source: ./common/config/shared/trust-certificates target: /harbor_cust_cert networks: - harbor ports: - 80:8080 - 9090:9090 depends_on: - registry - core - portal - log logging: driver: "syslog" options: syslog-address: "tcp://localhost:1514" tag: "proxy"
维护
-
停止 harbor 组件
docker-compose down -v -
启动 harbor 组件
docker-compose up -d
访问
-
启动后通过浏览器访问
http://$ip也可以通过harbor.yml进行自定义 -
默认用户/密码
admin/Harbor12345
附录:
必要组件
- nfs-csi
- postgres
- redis
安装必要组件
安装 nfs-csi
安装 nfs-server
yum install -y nfs-utils # 所有机器都要安装,nfs-server 机器启动服务
mkdir -p /data/
vi /etc/exports
/data/ 10.2x.0.0/16(rw,sync,no_subtree_check,no_root_squash)
systemctl start nfs-server.service
systemctl enable nfs-server.service
exportfs
依赖镜像
docker pull k8s.m.daocloud.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
安装 nfs-csi 工作负载
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --version v4.7.0 --set image.nfs.repository=k8s.m.daocloud.io/sig-storage/nfsplugin --set image.csiProvisioner.repository=k8s.m.daocloud.io/sig-storage/csi-provisioner --set image.livenessProbe.repository=k8s.m.daocloud.io/sig-storage/livenessprobe --set image.nodeDriverRegistrar.repository=k8s.m.daocloud.io/sig-storage/csi-node-driver-registrar --set image.csiSnapshotter.repository=k8s.m.daocloud.io/sig-storage/csi-snapshotter --set image.externalSnapshotter.repository=k8s.m.daocloud.io/sig-storage/snapshot-controller --set externalSnapshotter.enabled=true
创建 storageclass
cat sc.yaml # 当有多个 nfs-server 时,创建新的 sc 并指定ip:path 即可,这点比 nfs-subdir 方便不少
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
annotations:
storageclass.kpanda.io/allow-volume-expansion: "true"
storageclass.kpanda.io/support-snapshot: "true"
storageclass.kubernetes.io/is-default-class: "true" # 按需是否默认吧
provisioner: nfs.csi.k8s.io
parameters:
server: 10.x.x.x # 前面所创建的 nfs-server 地址
share: /data
# csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume
# csi.storage.k8s.io/provisioner-secret-name: "mount-options"
# csi.storage.k8s.io/provisioner-secret-namespace: "default"
reclaimPolicy: Delete
volumeBindingMode: Immediate
mountOptions:
- nfsvers=3
创建 pvc、并验证 snapshot
# 创建 pvc
[root@node-1 ~]# cat nfs-pvc-test.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-csi
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
# 检查
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim Bound pvc-7d845fd1-a70b-46e6-8eed-b59a0230740c 1Mi RWX nfs-csi 3s
# 检查 storgaeclass
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi nfs.csi.k8s.io Delete Immediate false 8m26s
# 检查 csidriver
kubectl get csidrivers.storage.k8s.io
NAME ATTACHREQUIRED PODINFOONMOUNT STORAGECAPACITY TOKENREQUESTS REQUIRESREPUBLISH MODES AGE
nfs.csi.k8s.io false false false <unset> false Persistent 25m
# snapshot 编排文件
cat nfs-csi-snapshot.yaml
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-nfs-snapclass
driver: nfs.csi.k8s.io
deletionPolicy: Delete
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-nfs-snapshot
spec:
volumeSnapshotClassName: csi-nfs-snapclass
source:
persistentVolumeClaimName: test-claim-csi
# 创建 snapshot
kubectl apply -f nfs-csi-snapshot-pvc-test-claim-csi.yaml
volumesnapshot.snapshot.storage.k8s.io/test-nfs-snapshot created
# 检查 volumesnapshot
kubectl get volumesnapshot
NAME READYTOUSE SOURCEPVC SOURCESNAPSHOTCONTENT RESTORESIZE SNAPSHOTCLASS SNAPSHOTCONTENT CREATIONTIME AGE
test-nfs-snapshot true test-claim-csi 105 csi-nfs-snapclass snapcontent-462e5866-3c10-4201-8c5b-c3e5fd68af3b 13s 13s
# 到 nfs-server /data/ 目录下检查
cd /data/ && ll
total 0
drwxrwxrwx. 2 root root 21 May 9 15:30 default-test-claim-pvc-372c6ee4-c2fa-41e5-9e7d-a7b18e7c6efc
drwxrwxrwx. 2 root root 6 May 9 15:34 default-test-claim2-pvc-88fe2a10-60b6-47c6-b77a-b07cbe7e001e
drwxr-xr-x. 2 root root 6 May 9 17:01 pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739
drwxr-xr-x. 2 root root 61 May 9 17:09 snapshot-462e5866-3c10-4201-8c5b-c3e5fd68af3b
[root@controller-node-1 data]# ls pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739/
[root@controller-node-1 data]# ls snapshot-462e5866-3c10-4201-8c5b-c3e5fd68af3b/
pvc-8ceef78d-bdaa-4503-9012-4844b9ce3739.tar.gz
安装 postgres
安装 postgres-operator
# git 仓库
https://github.com/zalando/postgres-operator.git
# 添加 pg 的 helm repo
helm repo add postgres-operator-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operator
# 安装 pg-operator
helm install postgres-operator postgres-operator-charts/postgres-operator
# 添加 postgres-operator-ui helm repo
helm repo add postgres-operator-ui-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operator-ui
安装 postgres-operator-ui
# 安装 postgres-operator-ui
helm install postgres-operator-ui postgres-operator-ui-charts/postgres-operator-ui
# 检查
[root@tf1-dameile-master01 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
csi-nfs-controller-dd44dfcd8-x9286 4/4 Running 0 39m
csi-nfs-node-44d7n 3/3 Running 0 39m
csi-nfs-node-d2lxx 3/3 Running 0 39m
postgres-operator-6f4676896-7bpxp 1/1 Running 0 4m48s
postgres-operator-ui-5d459c969b-68qk2 0/1 ContainerCreating 0 3s
# operator-ui-svc
[root@tf1-dameile-master01 postgres-operator]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 22d
postgres-operator ClusterIP 10.233.1.227 <none> 8080/TCP 140m
postgres-operator-ui NodePort 10.233.20.199 <none> 80:30537/TCP 135m
# 如果镜像 pull 很慢,可以切换成国内镜像站
ghcr.io/zalando/postgres-operator:v1.13.0
ghcr.io/zalando/postgres-operator-ui:v1.13.0 # ghcr.io 替换为 ghcr.m.daocloud.io
通过 postgres-ui 安装 pg-cluster


检查 pg-cluster 状态、并创建 core 数据库
# 检查 pg 运行状态
kubectl get postgresqls.acid.zalan.do
NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS
pg-cluster01 acid 16 2 20Gi 100m 100Mi 60m Running
kubectl get pod
NAME READY STATUS RESTARTS AGE
csi-nfs-controller-dd44dfcd8-x9286 4/4 Running 0 3h47m
csi-nfs-node-44d7n 3/3 Running 0 3h47m
csi-nfs-node-d2lxx 3/3 Running 0 3h47m
pg-cluster01-0 1/1 Running 0 25m
pg-cluster01-1 1/1 Running 0 18m
# 检查 pg 密码、需要 base64 -d 解密
kubectl get secrets postgres.pg-cluster01.credentials.postgresql.acid.zalan.do
NAME TYPE DATA AGE
postgres.pg-cluster01.credentials.postgresql.acid.zalan.do Opaque 2 69m
# 创建 pg core db 给 harbor 使用
kubectl exec -it pg-pod /bin/bash
psql -U postgres
\list # 查看数据库列表
create database core;
安装 redis-sentinel
添加 redis 的 repo
helm repo add ot-helm https://ot-container-kit.github.io/helm-charts/
"ot-helm" has been added to your repositories
安装 redis-operator
# 安装
helm upgrade redis-operator ot-helm/redis-operator --install
# 替换为国内镜像源
ghcr.io/ot-container-kit/redis-operator/redis-operator:v0.19.0
ghcr.m.daocloud.io/ghcr.io/ot-container-kit/redis-operator/redis-operator:v0.19.0
helm 部署 redis 哨兵模式
helm upgrade redis-sentinel ot-helm/redis-sentinel --install
cr 编排文件部署
---
apiVersion: v1
kind: Secret
metadata:
name: redis-secret
data:
password: RGFvY2xvdWQtMTIzJTBB # redis 密码中不支持带有 @ 符号
type: Opaque
---
apiVersion: redis.redis.opstreelabs.in/v1beta2
kind: RedisReplication
metadata:
name: redis-replication
spec:
clusterSize: 3
kubernetesConfig:
image: quay.io/opstree/redis:v7.0.12
imagePullPolicy: IfNotPresent
redisSecret:
name: redis-secret
key: password
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-csi # 不写就会使用默认的 storageclass
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
redisExporter:
enabled: false
image: quay.io/opstree/redis-exporter:v1.44.0
podSecurityContext:
runAsUser: 1000
fsGroup: 1000
---
apiVersion: redis.redis.opstreelabs.in/v1beta2
kind: RedisSentinel
metadata:
name: redis-sentinel
spec:
clusterSize: 3
podSecurityContext:
runAsUser: 1000
fsGroup: 1000
redisSentinelConfig:
redisReplicationName: redis-replication
kubernetesConfig:
image: 'quay.io/opstree/redis-sentinel:v7.0.7'
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 101m
memory: 128Mi
limits:
cpu: 101m
memory: 128Mi
检查 redis 运行状态
kubectl get pod | grep redis
redis-operator-865fcf65ff-dt52n 1/1 Running 0 3h35m
redis-replication-0 1/1 Running 0 18m
redis-replication-1 1/1 Running 0 12m
redis-replication-2 1/1 Running 0 12m
redis-sentinel-sentinel-0 1/1 Running 0 109s
redis-sentinel-sentinel-1 1/1 Running 0 2m39s
redis-sentinel-sentinel-2 1/1 Running 0 4m18s
安装 harbor
添加 repo
# 添加 harbor repo
helm repo add harbor https://helm.goharbor.io
# 解压 harbor 到本地、而非在线安装
helm fetch harbor/harbor --untar
# 编辑 values.yaml
cd harbor && ll
总用量 248
-rw-r--r--. 1 root root 637 9月 29 10:51 Chart.yaml
-rw-r--r--. 1 root root 11357 9月 29 10:51 LICENSE
-rw-r--r--. 1 root root 193696 9月 29 10:51 README.md
drwxr-xr-x. 14 root root 220 9月 29 10:51 templates
-rw-r--r--. 1 root root 38747 9月 29 10:51 values.yaml
自定义 values.yaml 文件
# redis 配置段
redis:
type: external
external:
# support redis, redis+sentinel
# addr for redis: <host_redis>:<port_redis>
# addr for redis+sentinel: <host_sentinel1>:<port_sentinel1>,<host_sentinel2>:<port_sentinel2>,<host_sentinel3>:<port_sentinel3>
addr: "redis+sentinel: redis-sentinel-sentinel-headless.default.svc.cluster.local:26379" # 示例的写法貌似有问题,我后期手动更改了好多 configmap 和 secret,我后面删除了 redis+sentinel,upgrade 的时候不知道会不会覆盖我修改的配置,更新后检查一切正常
# The name of the set of Redis instances to monitor, it must be set to support redis+sentinel
sentinelMasterSet: "myMaster"
# The "coreDatabaseIndex" must be "0" as the library Harbor
# used doesn't support configuring it
# harborDatabaseIndex defaults to "0", but it can be configured to "6", this config is optional
# cacheLayerDatabaseIndex defaults to "0", but it can be configured to "7", this config is optional
coreDatabaseIndex: "0"
jobserviceDatabaseIndex: "1"
registryDatabaseIndex: "2"
trivyAdapterIndex: "5"
# harborDatabaseIndex: "6"
# cacheLayerDatabaseIndex: "7"
# username field can be an empty string, and it will be authenticated against the default user
username: ""
password: "Daocloud-123"
# If using existingSecret, the key must be REDIS_PASSWORD # 由于我们 redis-secret 里面的 key 不是它。所以这里我们用 password 的形式
existingSecret: ""
# postgres 配置段
database:
# if external database is used, set "type" to "external"
# and fill the connection information in "external" section
type: external
external:
host: "pg-cluster01.default.svc.cluster.local"
port: "5432"
username: "postgres"
password: "M5Al5QLf966WrJ6ql6Zf0kV27Zqj2vLSCtzOLv9du2pej4UyV24jUoNlM8n76XdU" # 这里 harbor-core 的 configmap 也自定义了 POSTGRESQL_PASSWORD
coreDatabase: "core"
# if using existing secret, the key must be "password"
existingSecret: ""
# "disable" - No SSL
# "require" - Always SSL (skip verification)
# "verify-ca" - Always SSL (verify that the certificate presented by the
# server was signed by a trusted CA)
# "verify-full" - Always SSL (verify that the certification presented by the
# server was signed by a trusted CA and the server host name matches the one
# in the certificate)
sslmode: "require" # 这里要改成 skip,否则 harbor-core 去连接 pg 时会报禁止该 pod 连接
# The maximum number of connections in the idle connection pool per pod (core+exporter).
# If it <=0, no idle connections are retained.
maxIdleConns: 100
# The maximum number of open connections to the database per pod (core+exporter).
# If it <= 0, then there is no limit on the number of open connections.
# Note: the default number of connections is 1024 for harbor's postgres.
maxOpenConns: 900
# trivy 配置段
trivy:
# enabled the flag to enable Trivy scanner
enabled: false # 启用后,他会自动关联 redis 的配置
# expose 配置段
expose:
# Set how to expose the service. Set the type as "ingress", "clusterIP", "nodePort" or "loadBalancer"
# and fill the information in the corresponding section
type: nodePort
# pvc 配置段
persistence:
enabled: true
resourcePolicy: "keep"
persistentVolumeClaim:
registry:
existingClaim: ""
storageClass: "nfs-csi"
subPath: ""
accessMode: ReadWriteOnce
size: 5Gi
annotations: {}
jobservice:
jobLog:
existingClaim: ""
storageClass: "nfs-csi"
subPath: ""
accessMode: ReadWriteOnce
size: 1Gi
annotations: {}
database:
existingClaim: ""
storageClass: "nfs-csi"
subPath: ""
accessMode: ReadWriteOnce
size: 1Gi
annotations: {}
redis:
existingClaim: ""
storageClass: "nfs-csi"
subPath: ""
accessMode: ReadWriteOnce
size: 1Gi
annotations: {}
trivy:
existingClaim: ""
storageClass: "nfs-csi"
subPath: ""
accessMode: ReadWriteOnce
size: 5Gi
annotations: {}
安装 habor
# 安装
helm install harbor ./
# 检查 pod
[root@tf1-dameile-master01 harbor]# kubectl get pod | grep harbor
harbor-core-75764b69f8-8qk25 1/1 Running 0 66m
harbor-jobservice-67579b7c5c-76h5n 1/1 Running 0 63m
harbor-nginx-86c7b46658-vfrxr 1/1 Running 0 104m
harbor-portal-5c6d79654c-kspsm 1/1 Running 0 3h11m
harbor-registry-67f9bbb55d-6n8k6 2/2 Running 0 85m
# 检查 svc
[root@tf1-dameile-master01 harbor]# kubectl get svc | grep harbor
harbor NodePort 10.233.41.73 <none> 80:30002/TCP,443:30003/TCP 4h12m
harbor-core ClusterIP 10.233.24.137 <none> 80/TCP 4h12m
harbor-jobservice ClusterIP 10.233.57.124 <none> 80/TCP 4h12m
harbor-portal ClusterIP 10.233.37.110 <none> 80/TCP 4h12m
harbor-registry ClusterIP 10.233.59.162 <none> 5000/TCP,8080/TCP 4h12m
更新 harbor
# get 并修改 externalURL
helm get values harbor -a > harbor-values.yaml
externalURL: https://10.29.14.36:30003
# 更新
helm upgrade harbor ./ -f harbor-values.yaml
Release "harbor" has been upgraded. Happy Helming!
NAME: harbor
LAST DEPLOYED: Fri Feb 14 16:25:09 2025
NAMESPACE: default
STATUS: deployed
REVISION: 3
TEST SUITE: None
NOTES:
Please wait for several minutes for Harbor deployment to complete.
Then you should be able to visit the Harbor portal at https://10.29.14.36:30003
For more details, please visit https://github.com/goharbor/harbor
访问 harbor


参考链接
- redis-operator
- redis-secret
- redis-sentienl
- pg-operator and operator-ui
- pg-operator-configure
- harbor-values
- harbor-docs
docker 多架构镜像构建
pull 镜像
- arm64
docker pull rancher/local-path-provisioner:v0.0.31 --platform linux/arm64
- amd64
docker pull rancher/local-path-provisioner:v0.0.31 --platform linux/amd64
tag 镜像
docker tag rancher/local-path-provisioner-amd64:v0.0.31 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31-amd
docker tag rancher/local-path-provisioner-arm64:v0.0.31 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31-arm
创建多架构 manifest
docker manifest create --insecure --amend 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31-arm 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31-amd
docker manifest inspect 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31
push 镜像
docker manifest push --insecure 154.39.81.129:5000/rancher/local-path-provisioner:v0.0.31
image-syncer 使用
1. 配置文件两种写法
1.1 认证和镜像清单合并
{
# auth: 所有源和目标镜像仓库 url 和 认证信息全部放入 auth 字典
"auth": {
"harbor.myk8s.paas.com:32080": {
"username": "admin",
"password": "xxxxxxxxx",
"insecure": true
},
"registry.cn-beijing.aliyuncs.com": {
"username": "acr_pusher@1938562138124787",
"password": "xxxxxxxx"
}
},
# 源仓库和目标仓库以 key:value 的定义
"images": {
# 同步 nginx 所有版本到默认的镜像仓库中,默认仓库在 cli 可以进行更改 (default:image-syncer)
"harbor.myk8s.paas.com:32080/library/nginx": "",
# 源仓库字段中不包含 tag 时,表示将该仓库所有 tag 同步到目标仓库,此时目标仓库不能包含 tag
"harbor.myk8s.paas.com:32080/library/nginx": "registry.cn-beijing.aliyuncs.com/library/nginx", # 同步所有 nginx 版本
# 源仓库字段中包含 tag 时,表示同步源仓库中的一个 tag 到目标仓库,如果目标仓库中不包含tag,则默认使用源 tag
"harbor.myk8s.paas.com:32080/library/nginx:latest": "registry.cn-beijing.aliyuncs.com/library/nginx", # 同步 nginx:latest 版本
# 源仓库字段中的 tag 可以同时包含多个(比如"url/library/nginx:v1,v2,v3"),tag之间通过 "," 隔开,此时目标仓库不能包含tag,并且默认使用原来的 tag
"harbor.myk8s.paas.com:32080/library/nginx:latest,v1,v2,v3": "registry.cn-beijing.aliyuncs.com/library/nginx" # 同步 nginx 4 个版本
}
}
1.2 认证和镜像清单分开 (批量生成镜像清单时较为方便)
auth.json
{
"harbor.myk8s.paas.com:32080": {
"username": "admin",
"password": "xxxxxxxxx",
"insecure": true
},
"registry.cn-beijing.aliyuncs.com": {
"username": "acr_pusher@1938562138124787",
"password": "xxxxxxxx"
}
},
images.json # 使用 images.yaml 更简单,直接换行追加即可
{
"harbor.myk8s.paas.com:32080/library/nginx": "",
"harbor.myk8s.paas.com:32080/library/nginx": "registry.cn-beijing.aliyuncs.com/library/nginx",
"harbor.myk8s.paas.com:32080/library/nginx:latest": "registry.cn-beijing.aliyuncs.com/library/nginx",
"harbor.myk8s.paas.com:32080/library/nginx:latest,v1,v2,v3": "registry.cn-beijing.aliyuncs.com/library/nginx"
}
2. 开始同步
# image-syncer
--config: 指定配置文件为harbor-to-acr.json,内容如上所述
--registry: 设置默认目标 registry为registry.cn-beijing.aliyuncs.com,
--namespace: 默认目标 namespace 为 image-syncer
--proc: 并发数为10,重试次数为10
--log: 日志输出到 log 文件下,不存在自动创建,默认将日志打印到 stdout
./image-syncer --proc=10 --config=./config.json --registry=registry.cn-beijing.aliyuncs.com --namespace=image-syncer --retries=3 --log=./log
./image-syncer --proc=10 --retries=3 --proc=10 --auth=./auth.json --images=./images.json --retries=10 --log=./log
其它站点文章
Jenkins 邮件通知
系统管理员邮箱配置
- 配置文件
jenkins.model.JenkinsLocationConfiguration.xml
<?xml version='1.1' encoding='UTF-8'?>
<jenkins.model.JenkinsLocationConfiguration>
<adminAddress>xxx管理系统 <xxx@163.com></adminAddress>
<jenkinsUrl>http://xxx-jenkins:80/</jenkinsUrl>
邮件通知配置
- 配置文件
hudson.tasks.Mailer.xml- 下面的配置邮箱是侧免密配置,不需要认证,其它环境不一定适配,可以到 jenkins > 系统管理 > 邮件通知中更改即可
<?xml version='1.1' encoding='UTF-8'?>
<hudson.tasks.Mailer_-DescriptorImpl plugin="mailer@457.v3f72cb_e015e5">
<defaultSuffix>@163.com</defaultSuffix>
<replyToAddress>no-reply@k8s.io</replyToAddress>
<smtpHost>smtp.163.com</smtpHost>
<useSsl>false</useSsl>
<useTls>false</useTls>
<smtpPort>25</smtpPort>
<charset>UTF-8</charset>
nexus 初尝试
-
docker 部署 nexus
docker run -d -p 8081:8081 --name nexus sonatype/nexus:oss -
浏览器访问
- http://10.29.14.190:8081/nexus
-
创建 hosted site 站点,可以当作一个文件站点使用,让用户 curl or wget 下载
- 略,登录后 admin/admin123、Repositories Add 添加即可
-
上传文件
mawb:Downloads kingskye$ curl -v --user 'admin:admin123' --upload-file cdap-data-paas.zip http://10.29.14.190:8081/nexus/content/sites/javarepo/cdap-data-paas.zip * Trying 10.29.14.190:8081... * Connected to 10.29.14.190 (10.29.14.190) port 8081 * Server auth using Basic with user 'admin' > PUT /nexus/content/sites/javarepo/cdap-data-paas.zip HTTP/1.1 > Host: 10.29.14.190:8081 > Authorization: Basic YWRtaW46YWRtaW4xMjM= > User-Agent: curl/8.7.1 > Accept: */* > Content-Length: 200194056 > Expect: 100-continue > < HTTP/1.1 100 Continue < * upload completely sent off: 200194056 bytes < HTTP/1.1 201 Created < Date: Fri, 28 Mar 2025 13:52:00 GMT < Server: Nexus/2.15.2-03 < X-Frame-Options: SAMEORIGIN < X-Content-Type-Options: nosniff < Accept-Ranges: bytes < Content-Security-Policy: sandbox allow-forms allow-modals allow-popups allow-presentation allow-scripts allow-top-navigation < X-Content-Security-Policy: sandbox allow-forms allow-modals allow-popups allow-presentation allow-scripts allow-top-navigation < Content-Length: 0 < * Connection #0 to host 10.29.14.190 left intact -
查看文件
- http://10.29.14.190:8081/nexus/content/sites/javarepo/ 浏览器访问,可以看到文件
nexus 使用场景
- 可以配置各种源的代理
- maven 源
- python pip 源
- linux 不通发行版的 sources
- docker registry
- site 站点
Ansible 常规使用
常用命令
ansible $hostlist -m shell -k -a 'hostname'
ansible $hostlist -m command -k -a 'hostname'
ansible $hostlist -m script -k -a /root/hostname.sh
ansible $hostlist -m copy -k -a 'src=/root/hostname.sh dest=/root/'
ansible 常用模块
- file # 创建文件
- shell # 在节点中执行 shell / command
- command # 在节点中执行 command
- copy # 拷贝文件到节点中
- script # 将 ansible 节点中脚本发送到被控节点并执行
- mail # 邮件发送
- raw # 支持管道
ansible-playbook 示例
- hosts: cal
gather_facts: no
tasks:
- name: CreateDir
file:
path: /root/testDir
state: directory
register: mk_dir
- debug: var=mk_dir.diff.after.path
- register: 表示将 file模块执行的结果注入到mk_dir里面.以json格式输出
- debug:
常用参数:
- var: 将某个任务执行的输出作为变量传递给debug模块,debug会直接将其打印输出
- msg: 输出调试的消息
- verbosity:debug的级别(默认是0级,全部显示)
cpu 上下文切换
什么是 cpu 上下文切换
- CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
上下文切换场景有哪些?
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
进程上下文切换(进程间切换)
- 进程的运行空间有 内核空间、用户空间 两种;其中用户空间,不能直接访问内存等其他硬件设备,必须通过系统调用载入到内核空间中才能访问内核空间的资源。
- 也就是说,进程既可以在用户空间运行,称之为进程的用户态,又可以在内核空间运行,称之为进程的内核态,两者的转变,是需要通过系统调用来完成。
- 比如查看文件,首先调用 open() 函数打开文件,其次调用 read() 函数读取文件内容,最后调用 write() 函数将内容打印到 stdout,最最后再调用 close() 函数关闭文件。
- 以上系统调用,均是在一个进程运行,所以系统的调用我们成为特权模式切换,而不是上下文切换,但实际上上下文切换也是无法避免的,也就是说在整个调用的过程中,必然会发生 CPU 的上下文切换。
上下文切换、系统调用的区别?
- 系统调用只是会调用不同函数完成进程的需求,而进程上下文切换需要保存当前进程内核状态和 cpu 寄存器,也会把该进程的虚拟内存,栈等其它保存下来,从而加载下一进程的内核态后,而且也要刷新进程的虚拟内存和用户栈,所以保存上下文以及恢复上下文的过程是有资源消耗的,在大量的进程上下文切换过程,肯定会大量的消耗系统资源,好在进程的切换大部分都是几十纳秒和数微秒级别,所以切换时间还是相当可观的。
- 既然知道了上下文切换可能会导致系统负载较高,那我们需要知道什么时候会发生上下文切换,进程的切换就会有 cpu 上下文的切换,那么只有在进程调度时才需要上下文切换,而 linux为 每个 cpu 维护了一个就绪队列,其中主要是正在运行和正在等待 cpu 的进程(活跃进程),它们会按照优先级和等待cpu的时间进行排序,然后选择最需要 cpu 的进程,也就是优先级高的,和等待cpu时间最长的进程来运行。
哪些场景触发进程调度呢?
- cpu 是时间片,会被划分多个时间片,轮流的分配给进程,当某个进程时间片耗尽时,进程会被挂起,切换到其他正在等待 cpu 的进程运行
- 进程在系统资源不足时,需要等到资源满足后才可以运行进程,此时进程也会被挂起,并由系统调度其他进程运行。
- 优先级搞得进程,较低的优先级进程会被挂起。
- 主动挂起的进程 如 sleep,时间到了之后也会重新调度。
- 硬件中断时,cpu 上的进程也会被中断挂起,转而执行内核中的中断服务进程。
线程上下文切换
- 线程是调度基本单位,进程是拥有资源的基本单位,切换过程与进程上下文件切换一致。
- 内核态的任务调度,实际上调度的对象就是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
- 进程只有一个线程时,可以理解两者没有什么区别。
- 当进程有多个线程时,进程就比线程多了虚拟内存,全局变量等资源,而多个线程之间,这些资源他们是共享的,且上下文切换时它们是不需要被修改的,而线程也是有自己的私有资源的,比如栈和寄存器,这些独有的资源,在上下文切换时也是要被保存的,那进程间多线程切换就比进程内线程间切换资源消耗的多。
中断上下文切换
- 为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
- 跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。
- 中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。
- 同理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
- 另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
总结
- CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们特别关注,但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降
分析工具
vmstat (分析内存/disk/中断)
- vmstat -d -w -t 2 4 #查看当前系统disk的状态
disk- -------------------reads------------------- -------------------writes------------------ ------IO------- -----timestamp-----
total merged sectors ms total merged sectors ms cur sec CST
sda 44106 44 4820857 4332196 11668585 62776 114526946 7925754 0 4724 2020-11-23 13:48:02
sdb 300269 26 250656146 140945580 226256 10519 2601600 1145455 0 1033 2020-11-23 13:48:02
sr0 0 0 0 0 0 0 0 0 0 0 2020-11-23 13:48:02
dm-0 41684 0 4756993 4361968 11731339 0 114522729 8059180 0 4784 2020-11-23 13:48:02
dm-1 131 0 6480 103 0 0 0 0 0 0 2020-11-23 13:48:02
dm-2 58058 0 4818750 20286135 236775 0 2601600 2394758 0 386 2020-11-23 13:48:02
sda 44106 44 4820857 4332196 11668612 62776 114527234 7925763 0 4724 2020-11-23 13:48:04
- vmstat 2 10 -w #查看当前系统内存的状态
procs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu--------
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 4850040 182236 1479240 0 0 38 17 1 11 11 6 82 0 0
0 0 0 4850184 182236 1479276 0 0 0 91 5993 8727 10 5 84 0 0
1 0 0 4849300 182236 1479312 0 0 0 79 8565 13358 10 7 83 0 0
2 0 0 4849192 182236 1479312 0 0 0 43 6021 9128 8 4 88 0 0
0 0 0 4847916 182236 1479332 0 0 0 107 8270 12498 17 8 75 0 0
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数
- b(Blocked)则是处于不可中断睡眠状态的进程数
- cs(context switch)是每秒上下文切换的次数
- in(interrupt)则是每秒中断的次数
- us(user)和 sy(system)列:这两列的 CPU 使用率
通过 us、sys、in 可以判断系统当前是否有大量的中断以及从中得出系统的就绪队列是否过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,
而上下文切换又导致了系统 CPU 的占用率升高
pidstat 一探究竟(上下文切换的真凶是谁)
- pidstat -w -t 1 1 #-w 显示进程上下文切换信息,自愿切换(cswch)和非自愿切换(nvcswch)/s,pid,uid,进程名、 -t 显示线程指标,默认仅显示进程
pidstat -w -t | awk '{if($6>40) print $0}'
02:13:29 PM UID TGID TID cswch/s nvcswch/s Command
02:13:29 PM 81 892 - 69.73 7.84 dbus-daemon
02:13:29 PM 81 - 892 69.73 7.84 |__dbus-daemon
02:13:29 PM 0 - 1543 502.17 0.79 |__kubelet
02:13:29 PM 0 - 1570 196.74 0.42 |__dockerd
02:13:29 PM 0 2877 - 68.78 0.33 kube-apiserver
02:13:29 PM 0 - 2877 68.78 0.33 |__kube-apiserver
02:13:29 PM 0 - 3013 782.50 0.18 |__kube-apiserver
02:13:29 PM 0 - 3014 68.41 0.32 |__kube-apiserver
02:13:29 PM 0 - 3015 73.18 0.35 |__kube-apiserver
02:13:29 PM 0 - 3016 41.45 0.19 |__kube-apiserver
02:13:29 PM 0 - 3068 68.00 0.32 |__kube-apiserver
02:13:29 PM 0 - 3009 261.39 0.35 |__etcd
02:13:29 PM 0 - 4592 321.63 0.11 |__calico-node
02:13:29 PM 0 - 5069 44.32 0.01 |__coredns
02:13:29 PM 0 - 5776 44.45 0.01 |__coredns
02:13:29 PM 0 - 6177 223.16 0.26 |__promtail
02:13:29 PM 0 - 16975 77.53 0.02 |__kube-controller
- 自愿上下文切换(cswch/s),是指进程无法获取所需资源,导致的上下文切换。 比如说 I/O、内存等系统资源不足时,就会发生自愿上下文切换
- 非自愿上下文切换(nvcswch/s),则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
- 通过pidstat 查看发现,进程+线程的上下文切换数量等于 vmstat 看到的cs总数,也就是说某个进程cpu冲高,是因为有大量的上下文切换引起的
- 再仔细看下 vmstat 输出可以发现也有大量的 in 中断,那么中断如何查看呢?
- pidstat 是查看进程级别,也就是用户态的信息,中断的话要看,/proc/interrupts 这个只读文件。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况
- cat /proc/interrupts
56: 1111142 3538019 167594 5684931 PCI-MSI-edge vmw_pvscsi
57: 115 0 61338897 0 PCI-MSI-edge ens192-rxtx-0
58: 7466477 2487 19776 18644726 PCI-MSI-edge ens192-rxtx-1
59: 178574 30670451 1453 3161194 PCI-MSI-edge ens192-rxtx-2
60: 15560739 2658091 5120 6380376 PCI-MSI-edge ens192-rxtx-3
61: 0 0 0 0 PCI-MSI-edge ens192-event-4
62: 20 0 115918 0 PCI-MSI-edge vmw_vmci
63: 0 0 0 0 PCI-MSI-edge vmw_vmci
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 1110114780 1148914792 1159639791 1150435420 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 Performance monitoring interrupts
IWI: 5708696 6109423 6135541 6016581 IRQ work interrupts
RTR: 0 0 0 0 APIC ICR read retries
RES: 452734633 446248773 437210738 426982733 Rescheduling interrupts
CAL: 2322698 1821284 2640630 1284817 Function call interrupts
TLB: 27516878 27649410 27662689 27530045 TLB shootdowns
- RES 列对应的重新调度的中断,中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行,所以由此得知,vmstat 看到的in 过高,也是因为有大量的中断进程在重新调度,所以系统cpu冲高,
是因为有大量的上下文切换与中断在重新调度引起的
结论
- pidstat:
-w 上下文切换 -u cpu状态
-t 显示线程级别信息如,cswch、nvcswch
- vmstat
-d disk信息, 默认仅输出内存相关信息如: cs、in
- cat /proc/interrupts
- 中断相关信息
- 自愿上下文切换变多了(cswch),说明进程都在等待资源,有可能发生了 I/O 等其他问题
- 非自愿上下文切换变多了(nvcswch),说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈
- 中断次数变多了(interrupts),说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型
cpu 平均负载性能分析
Load Average 具体指什么?
- 平均负载:
是指单位时间内,系统处于 可运行状态和不可中断状态的平均进程数,也就是说是平均活跃进程数,和 cpu 的使用率并没有直接的关系。
- 可运行状态:
正在使用 cpu 或正在等待 cpu 的进程,也就是我们经常使用 ps 看到的处于 R (Running 或 Runnable) 的进程.
- 不可中断状态的进程:
正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如常见的 等待硬件设备的i/o响应,也就是我们 ps 看到的 D 状态 (Uninterruptible Sleep 也成为 disk sleep) 的进程 。 其实不可中断状态 实际上就是系统对进程和硬件设备的一种保护机制从而来保证进程数据与硬件数据保持一致(如,当一个进程在读写数据时,如果此时中断 D 状态的进程,那么就可能会导致,进程读写的数据,和 disk 中的数据不一致)。
- 总结:
平均负载,其实可以理解为,当前系统中平均活跃进程数。
如何判断系统,当前负载是否正常呢?
- 当平均负载大于当前系统 cpu 核心数时,说明当前系统负载较高,部分进程没有请求到cpu资源。那么我们如何通过 uptime 的三个时间段的负载来评断当前系统的负载是否正常。
- uptime 反应的是系统,1分钟、5分钟、15分钟的平均活跃进程数(平均负载)
- 查询当前系统 cpu的核心数
cat /proc/cpuinfo | grep processor | wc -l
- uptime 三个时间段负载看
可能15分钟的负载较高,但是1分钟内的负载较低,说明负载在减少,反之说明 近1分钟负载较高,而且以上两种情况都有可能一直持续下去,所以高和低只能对当前来说,要判断系统是否达到了瓶颈,需要持续的进行观察。
那 cpu 的使用率又是怎么回事呢?
- 平均负载高是不是就意味着,cpu 使用率高,其实平均负载是指单位时间内,处于可运行状态和不可中断黄台的的进程数,所以平均负载,不仅包含了正在使用 cpu 的进程,还包括了等待 cpu 和等待 i/o 的进程。 而 cpu 的使用率统计的是 单位时间内 cpu 繁忙的情况,跟平均负载并一定完全对应。
- 密集型应用进程,使用大量 cpu 时会导致平均负载高,这是吻合的,如果 i/o 密集型进程,等待 i/o 导致的平均负载高,那么这时 cpu 使用率就不一定很高。
- 再比如,大量等待 cpu 的进程调度也会导致平均负载高,而此时 cpu 使用率也会高。
- 所以要看进程的类型去判断为什么平均负载高,是什么引起的 cpu / 平均负载高。
分析系统性能常用工具
执行 yum install sysstat # 安装系统状态检查的必备工具
- top # 系统自带
- uptime # 系统自带
- iostat
- mpstat # 常用的多核心 cpu 性能分析工具,查看 每个 cpu 的性能指标,以及所有 cpu 的平均指标
- pidstat # 常用的进程 性能分析工具,用来实时查看进程的 cpu,内存,i/o 以及上下文切换等性能指标
案例一 (cpu 引起负载高)
stress --cpu 1 --timeout 600 # 模拟一个 cpu 100% 的场景
watch -d uptime # -d 变化的地方会高亮显示,系统告警时可以用它查看系统状态
mpstat -P ALL 5 # 每 5s 打印下所有 cpu 状态
02:37:11 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
02:37:16 PM all 40.26 0.00 5.70 0.00 0.00 0.41 0.00 0.00 0.00 53.63
02:37:16 PM 0 48.55 0.00 5.60 0.00 0.00 0.21 0.00 0.00 0.00 45.64
02:37:16 PM 1 71.37 0.00 2.66 0.00 0.00 0.20 0.00 0.00 0.00 25.77
02:37:16 PM 2 20.83 0.00 7.08 0.00 0.00 0.62 0.00 0.00 0.00 71.46
02:37:16 PM 3 19.87 0.00 7.32 0.00 0.00 0.42 0.00 0.00 0.00 72.38
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 35.54 0.00 5.28 0.02 0.00 0.48 0.00 0.00 0.00 58.68
Average: 0 52.24 0.00 3.69 0.00 0.00 0.39 0.00 0.00 0.00 43.68
Average: 1 45.38 0.00 4.26 0.00 0.00 0.44 0.00 0.00 0.00 49.93
Average: 2 28.09 0.00 6.13 0.02 0.00 0.60 0.00 0.00 0.00 65.16
Average: 3 16.21 0.00 7.08 0.02 0.00 0.46 0.00 0.00 0.00 76.22
- 通过 mpstat 结果来看:
平均负载冲高,%usr 用户级别是有 cpu 使用率冲高导致,且 iowait 始终为0,说明不是 io 导致的平均负载冲高。
- 那么是谁引起的冲高呢,我们继续排查:
pidstat -u 5 10 # -u 打印进程 cpu 使用率报告,间隔 5s、打印 10 次
Linux 3.10.0-862.el7.x86_64 (k8s-master01) 11/19/2020 _x86_64_ (4 CPU)
02:45:04 PM UID PID %usr %system %guest %CPU CPU Command
02:45:09 PM 0 1 0.60 0.60 0.00 1.20 3 systemd
02:45:09 PM 0 9 0.00 0.20 0.00 0.20 0 rcu_sched
02:45:09 PM 0 4968 99.20 0.40 0.00 99.60 1 stress
02:45:09 PM 0 5031 0.20 0.20 0.00 0.40 2 coredns
02:45:09 PM 0 5707 0.20 0.20 0.00 0.40 1 coredns
02:45:09 PM 0 6148 0.60 1.20 0.00 1.79 1 promtail
02:45:09 PM 0 6408 0.20 0.20 0.00 0.40 1 docker-containe
02:45:09 PM 0 6506 0.00 0.40 0.00 0.40 0 pidstat
02:45:09 PM 0 7522 0.60 0.40 0.00 1.00 2 kube-scheduler
02:45:09 PM 0 7529 4.38 1.39 0.00 5.78 3 kube-controller
02:45:09 PM UID PID %usr %system %guest %CPU CPU Command
02:45:14 PM 0 1 0.40 0.40 0.00 0.80 3 systemd
02:45:14 PM 0 1667 0.20 0.20 0.00 0.40 2 docker-containe
02:45:14 PM 0 4968 99.60 0.20 0.00 99.80 1 stress
02:45:14 PM 0 5031 0.20 0.40 0.00 0.60 2 coredns
02:45:14 PM 0 5707 0.40 0.20 0.00 0.60 1 coredns
02:45:14 PM 0 6148 0.60 1.60 0.00 2.20 1 promtail
02:45:14 PM 0 6506 0.20 0.40 0.00 0.60 0 pidstat
02:45:14 PM 0 7464 0.00 0.20 0.00 0.20 2 docker-containe
02:45:14 PM 0 7522 0.40 0.20 0.00 0.60 3 kube-scheduler
02:45:14 PM 0 7529 4.80 1.40 0.00 6.20 3 kube-controller
02:45:14 PM 0 24069 0.20 0.20 0.00 0.40 1 watch
02:45:14 PM 0 30488 0.00 0.20 0.00 0.20 2 kworker/2:1
02:45:14 PM UID PID %usr %system %guest %CPU CPU Command
02:45:19 PM 1001 4761 0.20 0.00 0.00 0.20 2 dashboard
02:45:19 PM 0 4968 99.20 0.20 0.00 99.40 1 stress
02:45:19 PM 0 5031 0.20 0.20 0.00 0.40 2 coredns
02:45:19 PM 0 5707 0.40 0.20 0.00 0.60 1 coredns
02:45:19 PM 1001 5759 0.00 0.20 0.00 0.20 1 metrics-sidecar
02:45:19 PM 0 6148 0.80 1.20 0.00 2.00 1 promtail
02:45:19 PM 0 6506 0.00 0.20 0.00 0.20 0 pidstat
02:45:19 PM 0 7522 0.40 0.20 0.00 0.60 2 kube-scheduler
02:45:19 PM 0 7529 3.60 0.80 0.00 4.40 2 kube-controller
02:45:19 PM 0 24877 0.20 0.00 0.00 0.20 1 sshd
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 0 1 0.60 0.60 0.00 1.20 - systemd
Average: 0 9 0.00 0.13 0.00 0.13 - rcu_sched
Average: 0 24 0.00 0.07 0.00 0.07 - ksoftirqd/3
Average: 0 556 0.13 0.33 0.00 0.47 - systemd-journal
Average: 0 4838 0.00 0.07 0.00 0.07 - bird6
Average: 0 4968 99.33 0.27 0.00 99.60 - stress
Average: 0 5031 0.20 0.27 0.00 0.47 - coredns
Average: 0 5707 0.33 0.20 0.00 0.53 - coredns
Average: 1001 5759 0.00 0.07 0.00 0.07 - metrics-sidecar
Average: 0 6148 0.67 1.33 0.00 2.00 - promtail
- 通过 pidstat 的几次结果来看,有一个进程叫 stress 的进程 cpu 使用率持续 99%,那么就说明是该进程导致的平均负载以及 cpu 使用率冲高的罪魁祸首,拉出去枪毙 5 分钟。
案例二 (io 引起负载高)
stress -i 1 -t 600 # 启动一个 io 类型的进程,时长 600s
mpstat -P ALL 5 3 # 打印3次 cpu使用情况
03:05:06 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:05:11 PM all 7.35 0.05 64.72 0.10 0.00 0.47 0.00 0.00 0.00 27.32
03:05:11 PM 0 9.32 0.00 58.80 0.00 0.00 0.83 0.00 0.00 0.00 31.06
03:05:11 PM 1 6.19 0.00 69.69 0.21 0.00 0.21 0.00 0.00 0.00 23.71
03:05:11 PM 2 5.36 0.00 65.36 0.21 0.00 0.62 0.00 0.00 0.00 28.45
03:05:11 PM 3 8.52 0.00 65.07 0.21 0.00 0.21 0.00 0.00 0.00 25.99
03:05:11 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:05:16 PM all 10.24 0.00 63.43 0.00 0.00 0.51 0.00 0.00 0.00 25.82
03:05:16 PM 0 12.37 0.00 57.73 0.00 0.00 0.41 0.00 0.00 0.00 29.48
03:05:16 PM 1 11.27 0.00 66.39 0.00 0.00 0.41 0.00 0.00 0.00 21.93
03:05:16 PM 2 10.10 0.00 62.68 0.00 0.00 0.62 0.00 0.00 0.00 26.60
03:05:16 PM 3 7.02 0.00 66.74 0.00 0.00 0.62 0.00 0.00 0.00 25.62
03:05:16 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
03:05:21 PM all 8.51 0.00 65.08 0.05 0.00 0.41 0.00 0.00 0.00 25.95
03:05:21 PM 0 10.47 0.00 62.42 0.00 0.00 0.41 0.00 0.00 0.00 26.69
03:05:21 PM 1 7.20 0.00 69.34 0.00 0.00 0.41 0.00 0.00 0.00 23.05
03:05:21 PM 2 9.00 0.00 60.33 0.00 0.00 0.41 0.00 0.00 0.00 30.27
03:05:21 PM 3 7.60 0.00 68.38 0.00 0.00 0.21 0.00 0.00 0.00 23.82
通过 mpstat 可以看到,%sys 系统级别 cpu 利用达到 65,且 %iowait 也有小的变化,说明是我们起的 stress io 进程引起平均负载冲高,但是 %usr 并不是很高,说明 本次平均负载的冲高不是由 cpu 使用率冲高引起的。
pidstat -u 5 3 # 打印3次cpu使用情况进程相关
Average: 0 32008 0.20 50.70 0.00 50.90 - stress
Average: 0 32009 0.20 53.69 0.00 53.89 - stress
Average: 0 32010 0.20 52.89 0.00 53.09 - stress
Average: 0 32011 0.20 53.39 0.00 53.59 - stress
而通过 pidstat 也可以查看到,是我们起了多个 stress io 进程引起的平均负载冲高。
结论
1. 当 %usr 使用率冲高,是用户级别 <user> 的 cpu 利用率冲高,往往平均负载也会冲高,冲高的原因就是进程在持续请求 cpu 时间片。
2. 当 %sys 使用率冲高,是系统级别 <kernel> 的 cpu 利用率冲高,以及如果 %io 在不断变化,则说明引起平均负载冲高,不是 cpu 利用引起的。
cpu 性能分析工具总结:
- mpstat # 查看 cpu 状态(mpstat -P ALL \ sar -P ALL 前者数据更多)
- sar -P 1,3,5 # 查看指定 cpu 核心的历史负载(10分钟更新一次)
- pidstat # 查看进程状态
- iostat # 查看 disk io 状态,间隔 1s(-x 显示详细信息、-z 采样周期无变化数据不进行打印)
- sar -n DEV 1 # 查看网络状态 间隔 1s
- top -H # 查看利用较高的进程
- ps -aux | awk '{if( $3 > 30) print $0}' # 查看使用率 >30 的进程信息
root 17774 35.0 0.0 7312 96 pts/2 R+ 15:18 0:40 stress -i 8 -t 600
root 17775 34.5 0.0 7312 96 pts/2 R+ 15:18 0:39 stress -i 8 -t 600
root 17776 34.5 0.0 7312 96 pts/2 R+ 15:18 0:39 stress -i 8 -t 600
root 17777 34.8 0.0 7312 96 pts/2 D+ 15:18 0:40 stress -i 8 -t 600
root 17778 34.7 0.0 7312 96 pts/2 R+ 15:18 0:39 stress -i 8 -t 600
root 17779 34.4 0.0 7312 96 pts/2 R+ 15:18 0:39 stress -i 8 -t 600
root 17780 35.0 0.0 7312 96 pts/2 D+ 15:18 0:40 stress -i 8 -t 600
root 17781 34.7 0.0 7312 96 pts/2 D+ 15:18 0:39 stress -i 8 -t 600
bonding 配置
bond 模式
| Mode | Switch配置 |
|---|---|
| 0 - balance-rr | 需要启用静态的 Etherchannel(未启用 LACP 协商) |
| 1 - active-backup | 需要可自主端口 |
| 2 - balance-xor | 需要启用静态的 Etherchannel(未启用 LACP 协商) # 需要交换机配置 |
| 3 - broadcast | 需要启用静态的 Etherchannel(未启用 LACP 协商) |
| 4 - 802.3ad | 需要启用 LACP 协商的 Etherchannel # 需要交换机配置 |
| 5 - balance-tlb | 需要可自主端口 |
| 6 - balance-alb | 需要可自主端口 |
配置
检查网卡是否支持 mii 检查机制
# 判断网卡是否支持 mii、以及网卡是否连线
ethtool p5p1 | grep "Link detected:"
Link detected: yes
检查网卡对应关系,避免 bonding 时搞错网卡
# ethtool -p p5p1 # 此时网卡会拼命像你招手
手动配置 bonding
# nmcli con add type bond ifname bond0 bond.options "mode=802.3ad,miimon=100,lacp_rate=1” # 802.3ad or 4、lacp_rate=fast/1
Connection 'bond0' (5f739690-47e8-444b-9620-1895316a28ba) successfully added.
# nmcli con add type ethernet ifname ens3 master bond0
Connection 'bond-slave-ens3' (220f99c6-ee0a-42a1-820e-454cbabc2618) successfully added.
#nmcli con add type ethernet ifname ens7 master bond0
Connection 'bond-slave-ens7' (ecc24c75-1c89-401f-90c8-9706531e0231) successfully added.
脚本配置 bonding
# 脚本文件 create_bonding.sh
#!/bin/bash
echo '配置 bond'
nmcli con add type bond ifname bond0 bond.options "mode=802.3ad,miimon=100,lacp_rate=1"
nmcli con add type ethernet ifname $1 master bond0
nmcli con add type ethernet ifname $2 master bond0
sed -i 's/BOOTPROTO=dhcp/BOOTPROTO=none/g' /etc/sysconfig/network-scripts/ifcfg-bond-bond0
sed -i 's/ONBOOT=no/ONBOOT=yes/g' /etc/sysconfig/network-scripts/ifcfg-bond-bond0
echo IPADDR=$3 >> /etc/sysconfig/network-scripts/ifcfg-bond-bond0
echo PREFIX=24 >> /etc/sysconfig/network-scripts/ifcfg-bond-bond0
echo GATEWAY=$4 >> /etc/sysconfig/network-scripts/ifcfg-bond-bond0
echo DNS1=10.29.19.254 >> /etc/sysconfig/network-scripts/ifcfg-bond-bond0
cat /etc/sysconfig/network-scripts/ifcfg-bond-bond0
echo ' '
echo '检查 bond 信息'
cat /sys/class/net/bond0/bonding/miimon
cat /sys/class/net/bond0/bonding/lacp_rate
cat /sys/class/net/bond0/bonding/mode
echo '重启网络服务'
systemctl restart network
ip ro ls
echo ' '
echo '禁用 selinx、firewalld'
systemctl stop firewalld && systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 执行
# chmod +x create_bonding.sh
# ./create_bonding.sh p4p1 p5p1 10.29.19.110 10.29.19.254
lcap_rate 含义
**lacp_rate=\*value\***
指定链接合作伙伴应在 802.3ad 模式下传输 LACPDU 数据包的速率。可能的值有:
slow 或 0 # 默认设置。这规定合作伙伴应每 30 秒传输一次 LACPDU。
fast 或 1 # 指定合作伙伴应每 1 秒传输一次 LACPDU
禁止 NetworkManger 管理网卡设备
# vi /etc/NetworkManager/conf.d/99-unmanaged-devices.conf
[keyfile]
# 单个设备
unmanaged-devices=interface-name:enp1s0
# 多个设备
unmanaged-devices=interface-name:interface_1;interface-name:interface_2;
# systemctl reload NetworkManager
# nmcli device status
DEVICE TYPE STATE CONNECTION
enp1s0 ethernet unmanaged --
多网卡场景禁用非默认网关网卡中网关的配置
# vi ifcfg-enps10
DEFROUTE=no
参考文档
7.3. 使用 NetworkManager 命令行工具 nmcli 进行网络绑定
按 user 对文件系统及子目录进行限额
修改 fstab 在 os 启动 mount 文件系统时开启 fs_quota
[root@controller-node-1 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Fri Jul 2 13:57:38 2021
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
/dev/mapper/fs--quota-lv /data/ xfs defaults,usrquota,grpquota,prjquota 0 0
UUID=3ed67e9f-ad87-41ae-88c5-b38d000ca3f4 /boot xfs defaults 0 0
[root@controller-node-1 ~]# mount | grep data
/dev/mapper/fs--quota-lv on /data type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,prjquota,grpquota)
查看 data 挂载点是否开启 user、group、project 限制
[root@controller-node-1 ~]# xfs_quota -x -c "state" /data
User quota state on /data (/dev/mapper/fs--quota-lv)
Accounting: ON
Enforcement: ON
Inode: #67 (1 blocks, 1 extents)
Group quota state on /data (/dev/mapper/fs--quota-lv)
Accounting: ON
Enforcement: ON
Inode: #68 (1 blocks, 1 extents)
Project quota state on /data (/dev/mapper/fs--quota-lv)
Accounting: ON
Enforcement: ON
Inode: #68 (1 blocks, 1 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
限制用户所使用的子目录空间大小
- xfs_quota:可以对文件系统进行限制
- 如果对子目录进行限制,需要创建识别码、对应目录、名称,让 xfs_quota 知道关系图
创建、目录/项目识别码、对应目录、及名称
[root@controller-node-1 ~]# echo "30:/data/mawb/dir1" >> /etc/projects
[root@controller-node-1 ~]# echo "dir1quota:30" >> /etc/projid
配置限制
[root@controller-node-1 ~]# xfs_quota -x -c "project -s dir1quota"
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
Setting up project dir1quota (path /data/mawb/dir1)...
Processed 1 (/etc/projects and cmdline) paths for project dir1quota with recursion depth infinite (-1).
[root@controller-node-1 ~]# xfs_quota -x -c "print" /data
Filesystem Pathname
/data /dev/mapper/fs--quota-lv (uquota, gquota, pquota)
/data/mawb/dir1 /dev/mapper/fs--quota-lv (project 30, dir1quota)
[root@controller-node-1 ~]# xfs_quota -x -c "report -pbih" /data
Project quota on /data (/dev/mapper/fs--quota-lv)
Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 0 0 0 00 [------] 4 0 0 00 [------]
dir1quota 0 0 0 00 [------] 1 0 0 00 [------]
[root@controller-node-1 ~]# xfs_quota -x -c "limit -p bsoft=400M bhard=500M dir1quota" /data
[root@controller-node-1 ~]# xfs_quota -x -c "report -pbih" /data
Project quota on /data (/dev/mapper/fs--quota-lv)
Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 0 0 0 00 [------] 4 0 0 00 [------]
dir1quota 0 400M 500M 00 [------] 1 0 0 00 [------]
验证是否生效
[root@controller-node-1 ~]# dd if=/dev/zero of=/data/mawb/project.img bs=1M count=520
记录了520+0 的读入
记录了520+0 的写出
545259520字节(545 MB)已复制,0.298309 秒,1.8 GB/秒
[root@controller-node-1 ~]# dd if=/dev/zero of=/data/project.img bs=1M count=520
记录了520+0 的读入
记录了520+0 的写出
545259520字节(545 MB)已复制,0.425858 秒,1.3 GB/秒
[root@controller-node-1 ~]# dd if=/dev/zero of=/data/mawb/dir1/project.img bs=1M count=520
dd: 写入"/data/mawb/dir1/project.img" 出错: 设备上没有空间
记录了501+0 的读入
记录了500+0 的写出
524288000字节(524 MB)已复制,4.45889 秒,118 MB/秒
[root@controller-node-1 ~]# xfs_quota -x -c "report -pbih" /data
Project quota on /data (/dev/mapper/fs--quota-lv)
Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 1.0G 0 0 00 [------] 6 0 0 00 [------]
dir1quota 500M 400M 500M 00 [7 days] 2 0 0 00 [------]
进阶用法
[root@controller-node-1 ~]# xfs_quota -x -c "limit -u bsoft=200M bhard=300M maweibing" /data
[root@controller-node-1 ~]# xfs_quota -x -c 'report -h' /data
User quota on /data (/dev/mapper/fs--quota-lv)
Blocks
User ID Used Soft Hard Warn/Grace
---------- ---------------------------------
root 1.0G 0 0 00 [0 days]
maweibing 0 200M 300M 00 [------]
Group quota on /data (/dev/mapper/fs--quota-lv)
Blocks
Group ID Used Soft Hard Warn/Grace
---------- ---------------------------------
root 1.0G 0 0 00 [------]
Project quota on /data (/dev/mapper/fs--quota-lv)
Blocks
Project ID Used Soft Hard Warn/Grace
---------- ---------------------------------
#0 1.0G 0 0 00 [------]
dir1quota 0 400M 500M 00 [------]
[maweibing@controller-node-1 ~]$ dd if=/dev/zero of=/data/mawb/dir1/project.img bs=1M count=520
dd: 写入"/data/mawb/dir1/project.img" 出错: 超出磁盘限额
记录了301+0 的读入
记录了300+0 的写出
314572800字节(315 MB)已复制,0.201772 秒,1.6 GB/秒
[maweibing@controller-node-1 ~]$ dd if=/dev/zero of=/data/mawb/dir1/project.img bs=1M count=100
记录了100+0 的读入
记录了100+0 的写出
104857600字节(105 MB)已复制,0.314926 秒,333 MB/秒
[maweibing@controller-node-1 root]$ dd if=/dev/zero of=/data/mawb/project.img bs=1M count=500
dd: 写入"/data/mawb/project.img" 出错: 超出磁盘限额
记录了201+0 的读入
记录了200+0 的写出
209715200字节(210 MB)已复制,0.758228 秒,277 MB/秒
[maweibing@controller-node-1 root]$ dd if=/dev/zero of=/data/mawb/project.img bs=1M count=100
记录了100+0 的读入
记录了100+0 的写出
104857600字节(105 MB)已复制,0.399685 秒,262 MB/秒
结论
- 目录权限还是在 root 用户下设置
- 按用户/组限制的话,只能对文件系统,不能对某个子目录
- 按文件系统限制的话,/data/目录下的所有目录都不能大于 hard 的限制
- 按项目限制的话,可以对子目录限制,但无法对用户限制
chrony 时钟同步
chrony 与 ntp 之前的区别
chronyd 可以优于 ntpd:
chronyd可以正常工作,其中对时间参考的访问是间歇性的,而ntpd需要定期轮询时间引用才能正常工作。chronyd网络较长时间拥塞也能表现良好chronyd通常可以更快准确地同步时钟chronyd能够快速适应时钟速率的突然变化chronyd可以调整较大范围内 Linux 系统上的时钟速率,即使在时钟中断或不稳定的机器上运行。例如,在某些虚拟机上:chronyd使用较少的内存
总之一句话,chrony 就是牛逼
chrony 配置
chronyd 和 chronyc 区别
chronyd守护进程chronyc监控和控制chronyd的client端
chronyd 配置
-
配置文件 - 18.4. 为不同的环境设置 chrony chrony.conf(5) Manual Page
# server 端 [root@10-29-26-144 ~]# cat /etc/chrony.conf driftfile /var/lib/chrony/drift commandkey 1 keyfile /etc/chrony.keys # 用于指定包含用于 NTP 数据包身份验证的 ID 密钥对的文件的位置 initstepslew 10 ntp1.aliyun.com # 步进的方式,来修正时钟,不建议使用,该配置会检查误差是否超过10s,如果是通过 后面的 client1、3、6 来修正 server 端的时钟 local stratum 8 manual # 启用 chronyc 中 使用 settime 命令来修改时间 allow 10.29.0.0/16 # 允许以下网段访问 # server 端启动后报,修正 initstepslew 指定的同步源即可修复 root@10-29-26-144 ~]# systemctl status chronyd ● chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2023-11-13 15:04:24 CST; 2s ago Docs: man:chronyd(8) man:chrony.conf(5) Process: 274162 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS) Process: 274159 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS) Main PID: 274161 (chronyd) CGroup: /system.slice/chronyd.service └─274161 /usr/sbin/chronyd Nov 13 15:04:24 10-29-26-144 systemd[1]: Starting NTP client/server... Nov 13 15:04:24 10-29-26-144 chronyd[274161]: chronyd version 3.4 starting (+CMDMON +NTP +REFCLOCK +RTC +PRIVDROP +SCFILTER +SIGND +ASYNCDNS +SECHASH +IPV6 +DEBUG) Nov 13 15:04:24 10-29-26-144 chronyd[274161]: commandkey directive is no longer supported Nov 13 15:04:24 10-29-26-144 chronyd[274161]: Could not resolve address of initstepslew server client1 Nov 13 15:04:24 10-29-26-144 chronyd[274161]: Could not resolve address of initstepslew server client3 Nov 13 15:04:24 10-29-26-144 chronyd[274161]: Could not resolve address of initstepslew server client6 Nov 13 15:04:24 10-29-26-144 chronyd[274161]: Frequency 0.000 +/- 1000000.000 ppm read from /var/lib/chrony/drift Nov 13 15:04:24 10-29-26-144 systemd[1]: Started NTP client/server. Hint: Some lines were ellipsized, use -l to show in full. # client 端 [root@controller-node-1 ~]# cat /etc/chrony.conf server 10.29.26.144 iburst driftfile /var/lib/chrony/drift logdir /var/log/chrony log measurements statistics tracking keyfile /etc/chrony.keys commandkey 24 local stratum 10 initstepslew 20 master allow 10.29.26.144 # 检查 (fina.daocloud.io=10.29.26.144) [root@controller-node-1 ~]# chronyc sources -v 210 Number of sources = 1 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* fina.daocloud.io 8 6 37 20 +1225ns[+1181us] +/- 159us
chrony 使用
chrony 跟踪
~]$ chronyc tracking
Reference ID : CB00710F (foo.example.net)
Stratum : 3
Ref time (UTC) : Fri Jan 27 09:49:17 2017
System time : 0.000006523 seconds slow of NTP time
Last offset : -0.000006747 seconds
RMS offset : 0.000035822 seconds
Frequency : 3.225 ppm slow
Residual freq : 0.000 ppm
Skew : 0.129 ppm
Root delay : 0.013639022 seconds
Root dispersion : 0.001100737 seconds
Update interval : 64.2 seconds
Leap status : Normal
chrony 同步源
~]$ chronyc sources
210 Number of sources = 3
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
#* GPS0 0 4 377 11 -479ns[ -621ns] +/- 134ns
^? a.b.c 2 6 377 23 -923us[ -924us] +/- 43ms
^+ d.e.f 1 6 377 21 -2629us[-2619us] +/- 86ms
M
这表示源的模式。^ 表示服务器,= 表示对等,# 代表本地连接的参考时钟
S
"*" 表示当前同步的 chronyd 的源
"+" 表示可接受的源与所选源结合使用
"-" 表示合并算法排除的可接受的源
"?" 表示丢失了哪个连接或者数据包没有通过所有测试的源
"x" 表示 chronyd 认为是 假勾号( 时间与大多数其他来源不一致
"~" 表示时间似乎有太多变化的来源。
"?" 条件也会在启动时显示,直到从中收集了至少三个样本
LastRx
显示了在多久前从源中获取了最后的样本
Last sample
显示本地时钟和最后一个测量源之间的偏差。方括号中的数字显示了实际测量的误差 ns(代表 nanoseconds)、us(代表 microseconds)、ms(代表 milliseconds)或 s (代表秒)后缀
方括号左边的数字显示了原来的测量,经过调整以允许应用本地时钟
+/- 指示符后的数字显示了测量中的错误裕度。正偏差表示本地时钟在源前面
~]$ chronyc sources -v
手动调整时钟
~]# chronyc makestep # 如果使用了 rtcfile 指令,则不应该手动调整实时时钟
linux 下解析顺序及 nameserver 配置
1.linux主机内解析的顺序
取决与 /etc/nsswitch.conf 配置文件中hosts顺序
hosts: files dns myhostname
说明:
#files 表示先去解析 /etc/hosts 文件中的记录,其实就类似于直接用 ip 访问后端应用 node1-web >> node2-data
#dns 表示去解析 /etc/resolv.confg 中的 dns 地址,由 dns 去正向和反向解析对应的记录,解析后转发至后端应用 node1-web >> dns_server(node2-data 记录) >> node2-data
#myhostname 类似于 127.0.0.1,有点自己 ping 自己的意思
2.nameserver 如何配置更改
方法一:无需重启网络服务直接生效
vi /etc/resolv.conf
nameserver 1.1.1.1
nameserver 2.2.2.2
重启网络服务后可能会丢失,怎么才不会丢失呢? 更改 /etc/sysconfig/network-scripts/ifcfg-ens2f0 配置文件新增会更改PEERDNS=no,这样重启网络服务就不会有影响了
方法二:需要重启网络服务
vi /etc/sysconfig/network-scripts/ifcfg-ens2f0
DNS1=1.1.1.1
DNS2=1.1.1.2
说明:
PEERDNS=no 实际是禁用使用dhcp_server 所下发的dns配置,禁用后,重启网络不会更改/etc/resolv.conf下的dns配置(但前提是网卡配置文件不要配置dns)
PEERDNS=yes 生产一般都是静态配置文件,不会使用dhcp,所以yes的话,重启网络服务也不会更改/etc/resolv.conf下的dns配置
其实无论 yes/no, 只要在/etc/resolv.conf文件下追加的dns-server是有效的,均配置即生效
-
shell 脚本利用 echo 命令输出颜色自定义(linux终端下,体验很好,但需要将结果导出为文本,不建议使用)
-
格式/示例: echo -e “\033[字背景颜色;文字颜色m字符串\033[0m” echo -e “\033[41;36m something here \033[0m”
-
注解: 其中41代表背景色, 36代表字体颜色
1. 背景颜色和字体颜色之间是英文的;
2. 字体颜色后面有 m
3. 字符串前后可以没有空格,如果有的话,输出也是同样有空格
4. \033[0m 为控制项
- 字体颜色
echo -e "\033[30m 黑色字 \033[0m"
echo -e "\033[31m 红色字 \033[0m"
echo -e "\033[32m 绿色字 \033[0m"
echo -e "\033[33m 黄色字 \033[0m"
echo -e "\033[34m 蓝色字 \033[0m"
echo -e "\033[35m 紫色字 \033[0m"
echo -e "\033[36m 天蓝字 \033[0m"
echo -e "\033[37m 白色字 \033[0m"
- 背景颜色
echo -e "\033[40;37m 黑底白字 \033[0m"
echo -e "\033[41;37m 红底白字 \033[0m"
echo -e "\033[42;37m 绿底白字 \033[0m"
echo -e "\033[43;37m 黄底白字 \033[0m"
echo -e "\033[44;37m 蓝底白字 \033[0m"
echo -e "\033[45;37m 紫底白字 \033[0m"
echo -e "\033[46;37m 天蓝底白字 \033[0m"
echo -e "\033[47;30m 白底黑字 \033[0m"
- 控制选项
\033[0m 关闭所有属性
\033[1m 设置高亮度
\033[4m 下划线
- 参考连接 自定义输出颜色-不同的用法
jq 进阶
格式化 json 文件
命令:
cat allip | jq -r .
cat allip | jq -r '[select(any(.;.state=="acquired"))|.tenant_name,.cidr,.pod_name] | @tsv' | grep -v ^$ | awk '/monitoring/'
输出:
monitoring 10.6. grafana-6468c88748-xgc68
monitoring 10.6. kube-state-metrics-6d98cc688f-drc5r
monitoring 10.6. prometheus-operator-7f7b8b587b-76bf6
monitoring 10.6. kube-metrics-exporter-789954cdf9-gq8g5
说明:
- select(): 查询 json 数据中符合要求的, == ,!= , >= , <= 等其它
- any(condition): 布尔值数组作为输入,即 true/false,数据为真,则返回 true
- any(generator; condition): generator-json 数据按层级划分 ,condition 条件
取最大值、列表元素 <=10 个
cat /tmp/i_cpu_data.json | jq -r '[.values[][1]]|@json' | jq max -r
取最大值
cat /tmp/i_cpu_data.json | awk 'BEGIN {max = 0} {if ($1+0 > max+0) max=$1} END {print max}'
格式化数据,按 csv 格式输出
bash getadminrole_userlist.sh | jq -r '["User","Type","ID"],(.items[] | [.name,.type,.id]) | @csv'
"User","Type","ID"
"admin","user","b5ec0e22-bfbc-414c-83b3-260c0dca21d2"
说明:
["User","Type","ID"]:定义 title
(.items[] | [.name,.type,.id]):按 dict/list 对数据检索
| @csv:导出为 csv 格式
输出示例如下:
curl http://10.233.10.18:9090/api/v1/targets?state=active | jq -r '["targets","endpoint","health"],(.data.activeTargets[] | [.scrapePool,.scrapeUrl,.health]) | @tsv'
targets endpoint health
serviceMonitor/ingress-nginx-lb01/ingress-nginx-lb01-controller/0 http://10.233.74.103:10254/metrics up
serviceMonitor/insight-system/insight-agent-etcd-exporter/0 http://10.233.74.110:2381/metrics up
serviceMonitor/insight-system/insight-agent-fluent-bit/0 http://10.233.74.119:2020/api/v1/metrics/prometheus up
serviceMonitor/insight-system/insight-agent-fluent-bit/0 http://10.233.84.205:2020/api/v1/metrics/prometheus up
serviceMonitor/insight-system/insight-agent-kube-prometh-apiserver/0 https://10.29.26.199:6443/metrics up
serviceMonitor/insight-system/insight-agent-kube-prometh-coredns/0 http://10.233.74.127:9153/metrics up
serviceMonitor/insight-system/insight-agent-kube-prometh-coredns/0 http://10.233.84.219:9153/metrics up
参考链接
Linux 文件查找与清理
查找大文件
find / -type f -size +500M -print0 | xargs -0 ls -lrth
find / -type f -size +500M -print | xargs ls -lrth
find / -type f -size +500M -print | xargs /bin/rm -rf
查找大目录
df -h --max-depth=2
查找并mv到指定目录
find /logs/xxxx/ -mtime +30 -name "*.log" -exec mv {} /logs/tmp_backup/xxxx \;
- 访问时间戳(atime):表示最后一次访问文件的时间。
- 修改时间戳 (mtime):这是文件内容最后一次修改的时间。
- 更改时间戳(ctime):指上次更改与文件相关的某些元数据的时间。
指定目录深度,查找删除60天前文件
find /logs/xxxx/appname -maxdepth 10 -name *.tar -mtime +60 -type f -delete
iptables 开启/禁用端口
命令:iptables
参数:
- -A 添加一条 input 规则, INPUT 进、OUTPUT 出
- -p 指定协议类型,如 tcp / udp
- -s 源地址
- -d 目标地址
- --dport 目标端口
- --sport 与 dport 相反为源端口
- -j 决定是接受还是丢掉数据包,ACCEPT 表示接受,DROP 表示丢掉相关数据包
示例1:(接受任何节点 ssh 会话,需要添加 2 条规则,进出都开启)
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
示例2:(禁止某主机访问节点的 ssh端口)
iptables -A INPUT -p tcp -s 192.168.1.x -j DROP
示例3:(禁止节点与 某主机的 22 端口进行通信)
iptables -A OUTPUT -p tcp -d 192.168.1.x --dport 22 -j DROP
示例4:(删除规则)
iptables -D OUTPUT -p tcp -d 192.168.1.x --dport 22 -j DROP
iptables -L -n --line-number
iptables -D INPUT 2
其他资料 SNAT、DNAT
TcpDump 使用方法
tcpdump 常用参数
[root@k8s-master01 ~]# tcpdump --help
tcpdump version 4.9.2
libpcap version 1.5.3
OpenSSL 1.0.2k-fips 26 Jan 2017
Usage: tcpdump [-aAbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ]
[ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ]
[ -i interface ] [ -j tstamptype ] [ -M secret ] [ --number ]
[ -Q|-P in|out|inout ]
[ -r file ] [ -s snaplen ] [ --time-stamp-precision precision ]
[ --immediate-mode ] [ -T type ] [ --version ] [ -V file ]
[ -w file ] [ -W filecount ] [ -y datalinktype ] [ -z postrotate-command ]
[ -Z user ] [ expression ]
-i ens192 #指定网络接口设备
-t #对抓取所有包不加时间戳 (-tt、-ttt、-tttt 加上不同的时间戳,如秒、年/月/日/时/分/秒)
-s0 #抓取的数据报不会被截断,便于后续进行分析
-n #抓取的包以IP地址方式显示,不进行主机名解析 (-nn 抓取的包如ssh,已22 的形式进行显示)
-v #输出较详细的数据 (-vv、-vvv 同理)
-w #将数据重定向到文件中,而非标准输出
tcpdump 表达式
!
and
or
示例:(and)
[root@k8s-master01 ~]# tcpdump tcp -nn -i ens192 -t -s0 and dst 10.6.203.63 and dst port 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [S], seq 3113679214, win 29200, options [mss 1460,sackOK,TS val 3908715180 ecr 0,nop,wscale 7], length 0
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [.], ack 3504717432, win 229, options [nop,nop,TS val 3908715195 ecr 2496275413], length 0
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [.], ack 22, win 229, options [nop,nop,TS val 3908717316 ecr 2496277534], length 0
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [P.], seq 0:10, ack 22, win 229, options [nop,nop,TS val 3908721874 ecr 2496277534], length 10
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [.], ack 41, win 229, options [nop,nop,TS val 3908721875 ecr 2496282093], length 0
IP 10.6.203.60.54956 > 10.6.203.63.22: Flags [F.], seq 10, ack 42, win 229, options [nop,nop,TS val 3908721879 ecr 2496282096], length 0
示例:(or)当有多个dst地址时,可以使用or来进行同时抓取
[root@k8s-master01 ~]# tcpdump tcp -nn -i ens192 -s0 and dst 10.6.203.63 or dst 10.6.203.64 and dst port 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
12:13:28.961250 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [S], seq 1321753332, win 29200, options [mss 1460,sackOK,TS val 3908829347 ecr 0,nop,wscale 7], length 0
12:13:28.961857 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [.], ack 1921664081, win 229, options [nop,nop,TS val 3908829348 ecr 4223571043], length 0
12:13:28.988597 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [.], ack 22, win 229, options [nop,nop,TS val 3908829375 ecr 4223571069], length 0
12:13:30.143741 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [P.], seq 0:11, ack 22, win 229, options [nop,nop,TS val 3908830530 ecr 4223571069], length 11
12:13:30.144396 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [.], ack 41, win 229, options [nop,nop,TS val 3908830531 ecr 4223572225], length 0
12:13:30.146677 IP 10.6.203.60.33874 > 10.6.203.64.22: Flags [F.], seq 11, ack 42, win 229, options [nop,nop,TS val 3908830533 ecr 4223572227], length 0
12:13:31.676547 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [S], seq 2733737364, win 29200, options [mss 1460,sackOK,TS val 3908832063 ecr 0,nop,wscale 7], length 0
12:13:31.677639 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [.], ack 963419704, win 229, options [nop,nop,TS val 3908832064 ecr 2496392281], length 0
12:13:31.712209 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [.], ack 22, win 229, options [nop,nop,TS val 3908832098 ecr 2496392316], length 0
12:13:33.055319 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [P.], seq 0:8, ack 22, win 229, options [nop,nop,TS val 3908833441 ecr 2496392316], length 8
12:13:33.056220 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [.], ack 41, win 229, options [nop,nop,TS val 3908833442 ecr 2496393660], length 0
12:13:33.056626 IP 10.6.203.60.55726 > 10.6.203.63.22: Flags [F.], seq 8, ack 42, win 229, options [nop,nop,TS val 3908833443 ecr 2496393660], length 0
示例:(!) 排除src/dst地址为10.6.203.64/10.6.203.63 为22的数据包
[root@k8s-master01 ~]# tcpdump tcp -nn -i ens192 -t -s0 and ! dst 10.6.203.63 and ! src 192.168.170.20 and dst port 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [S], seq 2539166541, win 29200, options [mss 1460,sackOK,TS val 3915719486 ecr 0,nop,wscale 7], length 0
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [.], ack 253672407, win 229, options [nop,nop,TS val 3915719487 ecr 4230461180], length 0
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [.], ack 22, win 229, options [nop,nop,TS val 3915719518 ecr 4230461211], length 0
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [P.], seq 0:5, ack 22, win 229, options [nop,nop,TS val 3915731003 ecr 4230461211], length 5
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [P.], seq 5:10, ack 22, win 229, options [nop,nop,TS val 3915731850 ecr 4230472697], length 5
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [.], ack 41, win 229, options [nop,nop,TS val 3915731850 ecr 4230473544], length 0
IP 10.6.203.60.50800 > 10.6.203.64.22: Flags [F.], seq 10, ack 42, win 229, options [nop,nop,TS val 3915731851 ecr 4230473544], length 0
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [S], seq 631664675, win 29200, options [mss 1460,sackOK,TS val 3915742485 ecr 0,nop,wscale 7], length 0
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [.], ack 3229258316, win 229, options [nop,nop,TS val 3915742498 ecr 1630199670], length 0
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [.], ack 22, win 229, options [nop,nop,TS val 3915743861 ecr 1630201039], length 0
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [P.], seq 0:5, ack 22, win 229, options [nop,nop,TS val 3915748354 ecr 1630201039], length 5
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [P.], seq 5:7, ack 22, win 229, options [nop,nop,TS val 3915748478 ecr 1630205533], length 2
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [.], ack 41, win 229, options [nop,nop,TS val 3915748480 ecr 1630205658], length 0
IP 10.6.203.60.38270 > 10.6.203.62.22: Flags [F.], seq 7, ack 42, win 229, options [nop,nop,TS val 3915748480 ecr 1630205658], length 0
tcpdump 按大小、数量抓包
tcpdump tcp -i eth0 -t -s0 -nn and dst port 8080 or src port 8080 -C 100 -W 100 -w xxx_$(date +"%H-%M-%S").pacp
-C :限制大小,单位是 M
-W :限制数量,自动覆盖前期的数据
tcpdump 参数详解
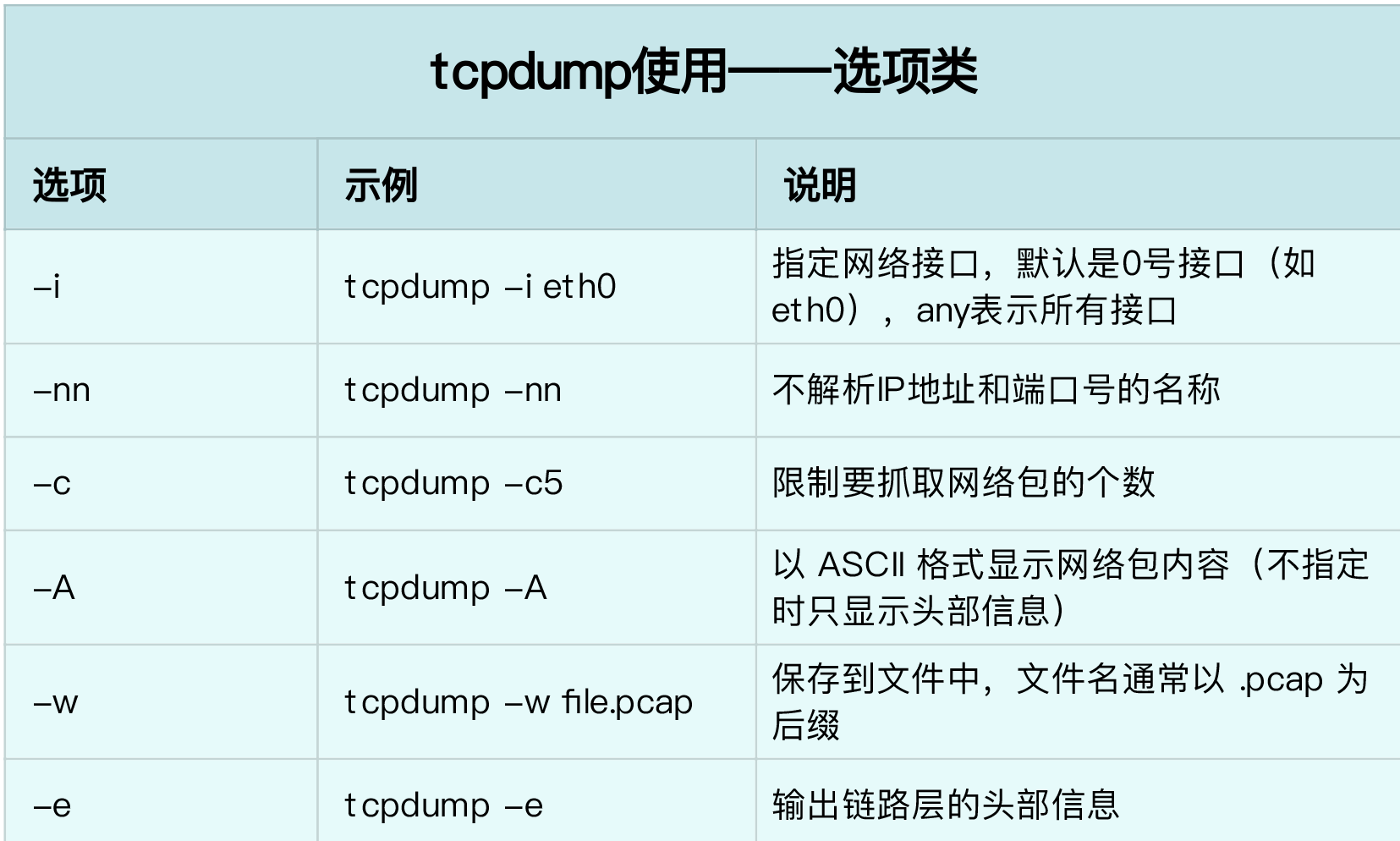
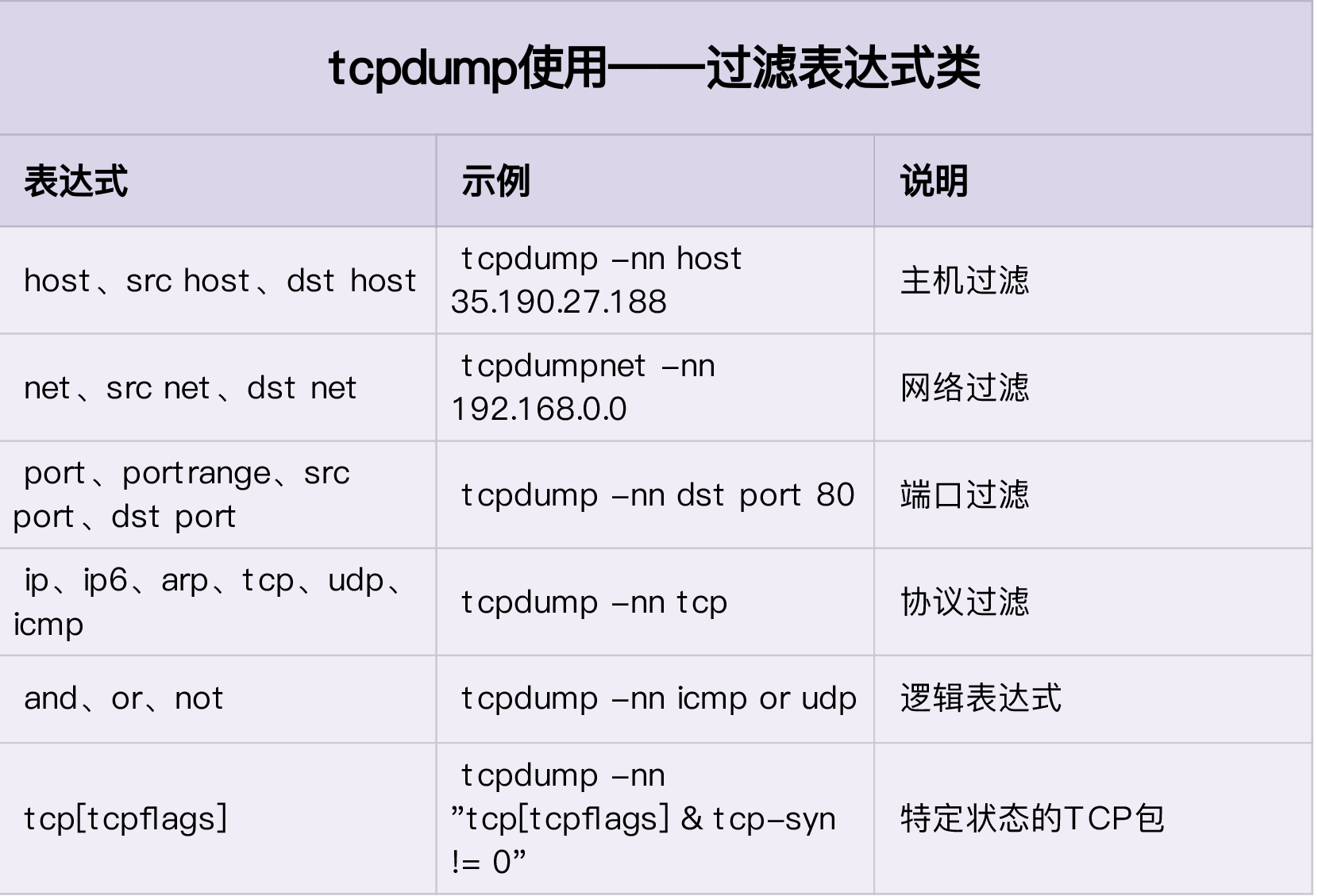
Shell 使用
条件判断
特殊变量
条件测试 (数据来源 OpenAI)
在 shell 中,[] 是用于条件测试的一种运算符。以下是常见的在方括号中使用的判断:
- 字符串比较:可以使用 == 或 != 运算符来检查两个字符串是否相等或不相等,例如 [ “str1” == “str2” ]
- 数值比较:可以使用 -eq、-ne、-gt、-lt、-ge 或 -le 来检查两个数值是否相等、不相等、大于、小于、大于等于或小于等于,例如 [ “num1” −eq “num2” ]
- 文件或目录检查:可以使用 -e、-f、-d、-r、-w 或 -x 来检查文件或目录是否存在、是否为普通的文件、是否为目录、是否可读、是否可写或是否可执行,例如 [ -e “/path/to/file” ]
- 逻辑操作符:可以使用 && 或 || 运算符来实现逻辑与和逻辑或操作,例如 [ “var1” == “foo” ] && [ “var2” == “bar” ]
- 模式匹配:可以使用 *、? 和 [] 来进行模式匹配和通配符扩展,例如 [ “$filename” == *.txt ]
请注意,在方括号内部的每个条件都应该用空格隔开,并且整个表达式应该用方括号包裹起来。
特殊变量 (数据来源 OpenAI)
在 shell 脚本中,$# 是一个特殊变量,用于获取命令行参数的数量。具体来说,它表示在执行脚本时传递给该脚本的参数的数量,不包括脚本名称本身。
例如,假设您编写了一个名为 test.sh 的脚本,并执行以下命令:
./test.sh foo bar baz
在 test.sh 中,您可以使用 $1、$2、$3 等变量分别获取 “foo”、“bar” 和 “baz” 这三个参数的值,而 $# 变量则将返回 3,即命令行参数的数量。
下面是一个示例脚本,演示如何使用 $# 变量:
#!/bin/bash
if [ $# -eq 0 ]; then
echo "Usage: $0 <arg1> <arg2> ..."
else
echo "You have provided $# command line argument(s)."
fi
# test
该脚本检查是否提供了命令行参数。如果没有,则输出用法信息;否则,它将输出参数数量的消息。注意,在上述脚本中,$0 变量用于获取脚本名称本身。
统计目录大小及文件数
脚本
#!/bin/bash
# Check if a directory is provided as an argument
if [ $# -eq 0 ]; then
echo "Usage: $0 <directory>"
exit 1
fi
# Array to store directory information
declare -a dir_info
# Function to calculate the size of a directory
calculate_directory_size() {
local dir=$1
local level=$2
# Calculate the size of the directory (excluding subdirectories)
size=$(du -sh $dir | awk '{print $1}')
# Count the number of files in the directory (excluding subdirectories)
file_count=$(find $dir -maxdepth 1 -type f | wc -l)
# Store directory information in the array
dir_info+=("Level $level: Directory: $dir, Size: $size, Files: $file_count")
# Check if the maximum recursion level is reached
if [ $level -lt 5 ]; then
# Iterate over subdirectories
for subdir in $(find $dir -maxdepth 1 -mindepth 1 -type d); do
# Recursively calculate the size of subdirectories
calculate_directory_size "$subdir" $((level + 1))
done
fi
}
# Main script
target_directory=$1
calculate_directory_size "$target_directory" 1
# Sort and display directory information
IFS=$'\n' sorted_info=($(sort <<<"${dir_info[*]}"))
unset IFS
for info in "${sorted_info[@]}"; do
echo "$info"
done
自定义容器内路由
通过容器查找其 PID
docker inspect --format '{{ .State.Pid }}' $container_id
制作软链接
ln -s /proc/$pid/ns/net /var/run/netns/$pid
增删改查容器内明细路由
- ip netns 方法
cd /var/run/netns
ip netns exec $pid
ip netns exec $pid route -n
ip netns exec $pid ip route add 10.114.0.0/24 via 10.142.2.1
ip netns exec $pid route -n
ip netns exec $pid ip route delete 10.114.0.0/24 via 10.142.2.1
ip netns exec $pid route -n
- nsenter 方法
nsenter -t $pid -n ip route add 10.114.0.0/24 via 10.142.2.1
nsenter -t $pid -n routne -n
ip-netns vs nsenter
ip netns:进程网络命名空间管理工具
- ip netns list # 显示所有 netns 列表
- ip netns monitor # 监控 netns 的创建和删除事件
- ip netns add xxx # 创建
- ip netns delete xxx # 删除
- ip netns pids xxx. # 查找所有跟此 netns 有关联的进程 pid (思考:如果有残留的容器netns,是不是也可用这个方法查找)
nsenter:不同 namespace 下运行程序
-t # 进程 pid
-n, --net[=file]
Enter the network namespace. If no file is specified, enter
the network namespace of the target process. If file is
specified, enter the network namespace specified by file.
通过 pid 查找 container_ID
场景
我的问题是,节点负载很高(cpu/mem),一时半会定位不到问题所在,且监控层面看到文件句柄数很高18w+,因此通过 pidstat 查看下进程利用率(内存相关),因为之前出现过主机内存 90+% 的利用率居高不下
命令
# 查找占用 40g 以上的虚拟内存的 pid
# pidstat -rsl 1 3 | awk 'NR>1{if($7>40000000) print}'
# pidstat -rsl 1 3 | awk 'NR>1{if($7>10000) print}'
# output
11时42分28秒 UID PID minflt/s majflt/s VSZ RSS %MEM StkSize StkRef Command
11时42分30秒 0 2738052 1.54 0.00 1254560 484040 3.99 136 24 kube-apiserver --advertise-address=10.29.15.79 --allow-privileged=true --anonymous-auth=True --apiserver-count=1 --audit-log-ma
平均时间: UID PID minflt/s majflt/s VSZ RSS %MEM StkSize StkRef Command
平均时间: 0 2738052 1.54 0.00 1254560 484040 3.99 136 24 kube-apiserver --advertise-address=10.29.15.79 --allow-privileged=true --anonymous-auth=True --apiserver-count=1 --audit-log-ma
# lsof -p $PID | wc -l # 可以使用 lsof 来统计该 pid 的文件句柄数集信息,我的环境是打开了 8w+,kill 掉其主进程后内存和 cpu利用有所降低,之所以有 8w+,是因为其中一部分文件删除后没有自动释放掉导致
# 通过 pid 查找其是否有 ppid
# ps -elF | grep 2738052 | grep -v grep
# output
4 S root 2738052 2737683 18 80 0 - 313640 futex_ 451296 5 1月02 ? 15:09:26 kube-apiserver --advertise-address=10.29.15.79 --allow-privileged=true --anonymous-auth=True --apiserver-count=1 --audit-log-maxage=30 --audit-log-maxbackup=1 --audit-log-maxsize=100 --audit-log-path=/var/log/audit/kube-apiserver-audit.log --audit-policy-file=/etc/kubernetes/audit-policy/apiserver-audit-policy.yaml --authorization-mode=Node,RBAC --bind-address=0.0.0.0 --client-ca-file=/etc/kubernetes/ssl/ca.crt --default-not-ready-toleration-seconds=300 --default-unreachable-toleration-seconds=300 --enable-admission-plugins=NodeRestriction --enable-aggregator-routing=False --enable-bootstrap-token-auth=true --endpoint-reconciler-type=lease --etcd-cafile=/etc/kubernetes/ssl/etcd/ca.crt --etcd-certfile=/etc/kubernetes/ssl/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/ssl/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --event-ttl=1h0m0s --kubelet-client-certificate=/etc/kubernetes/ssl/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/ssl/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalDNS,InternalIP,Hostname,ExternalDNS,ExternalIP --profiling=False --proxy-client-cert-file=/etc/kubernetes/ssl/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/ssl/front-proxy-client.key --request-timeout=1m0s --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/ssl/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-issuer=https://kubernetes.default.svc.cluster.local --service-account-key-file=/etc/kubernetes/ssl/sa.pub --service-account-lookup=True --service-account-signing-key-file=/etc/kubernetes/ssl/sa.key --service-cluster-ip-range=10.233.0.0/18 --service-node-port-range=30000-32767 --storage-backend=etcd3 --tls-cert-file=/etc/kubernetes/ssl/apiserver.crt --tls-private-key-file=/etc/kubernetes/ssl/apiserver.key
# ps -elF | grep 2737683 | grep -v grep
# output
0 S root 2737683 1 0 80 0 - 178160 futex_ 13124 5 1月02 ? 00:03:22 /usr/local/bin/containerd-shim-runc-v2 -namespace k8s.io -id fd272ecbe1bf56fb5fbff41130437e5c4b5b444dab2e315a19ed846dc1eacd42 -address /run/containerd/containerd.sock
4 S 65535 2737744 2737683 0 80 0 - 245 sys_pa 4 2 1月02 ? 00:00:00 /pause
4 S root 2738052 2737683 18 80 0 - 313640 futex_ 487444 5 1月02 ? 15:09:52 kube-apiserver --advertise-address=10.29.15.79 --allow-privileged=true --anonymous-auth=True --apiserver-count=1 --audit-log-maxage=30 --audit-log-maxbackup=1 --audit-log-maxsize=100 --audit-log-path=/var/log/audit/kube-apiserver-audit.log --audit-policy-file=/etc/kubernetes/audit-policy/apiserver-audit-policy.yaml --authorization-mode=Node,RBAC --bind-address=0.0.0.0 --client-ca-file=/etc/kubernetes/ssl/ca.crt --default-not-ready-toleration-seconds=300 --default-unreachable-toleration-seconds=300 --enable-admission-plugins=NodeRestriction --enable-aggregator-routing=False --enable-bootstrap-token-auth=true --endpoint-reconciler-type=lease --etcd-cafile=/etc/kubernetes/ssl/etcd/ca.crt --etcd-certfile=/etc/kubernetes/ssl/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/ssl/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --event-ttl=1h0m0s --kubelet-client-certificate=/etc/kubernetes/ssl/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/ssl/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalDNS,InternalIP,Hostname,ExternalDNS,ExternalIP --profiling=False --proxy-client-cert-file=/etc/kubernetes/ssl/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/ssl/front-proxy-client.key --request-timeout=1m0s --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/ssl/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-issuer=https://kubernetes.default.svc.cluster.local --service-account-key-file=/etc/kubernetes/ssl/sa.pub --service-account-lookup=True --service-account-signing-key-file=/etc/kubernetes/ssl/sa.key --service-cluster-ip-range=10.233.0.0/18 --service-node-port-range=30000-32767 --storage-backend=etcd3 --tls-cert-file=/etc/kubernetes/ssl/apiserver.crt --tls-private-key-file=/etc/kubernetes/ssl/apiserver.key
# ps -ejH | grep -B 10 2738052 # 打印进程树
# output
2737683 2737683 1163 ? 00:03:24 containerd-shim
2737744 2737744 2737744 ? 00:00:00 pause
2738052 2738052 2738052 ? 15:17:02 kube-apiserver
# 结论
pid 2738052 是由 ppid 2737683 启动,而 2737683 是 containerd-shim 的 pid,因此 2738052 是 containerd-shim 的线程,也就是由它启动的 container
确认容器
# nerdctl ps | awk 'NR>1{print $1}' | while read line;do echo -n "ContainerID: " $line; echo " Pid: " `nerdctl inspect $line --format="{{.State.Pid}}"`;done
# output
ContainerID: 001c06d37aa3 Pid: 3894654
ContainerID: 10948947ffe2 Pid: 3190
ContainerID: 12e473bf2092 Pid: 2738736
ContainerID: 2036c51b2eb1 Pid: 2638619
ContainerID: 31f6916a4d19 Pid: 2144173
ContainerID: 3e7aaa92e14d Pid: 946163
ContainerID: 40290d1314b0 Pid: 2737814
ContainerID: 41ef80123273 Pid: 2738052
ContainerID: 422a631fa706 Pid: 4151
ContainerID: 4bf701e368e1 Pid: 2737820
ContainerID: 535448e5cdd0 Pid: 2638612
ContainerID: 5ea9dbdedc25 Pid: 4711
ContainerID: 5f17a1c82e2a Pid: 2565
ContainerID: 68ddb09e71ba Pid: 4962
ContainerID: 69cf228ae17d Pid: 4054
ContainerID: 74d39157ea3c Pid: 2738680
ContainerID: 77cf2b283806 Pid: 5056
ContainerID: 7acb0441a3ad Pid: 2737689
ContainerID: 821dcae2eaca Pid: 1023468
ContainerID: 88060b9b98da Pid: 2448
ContainerID: 9179c60702c4 Pid: 2647586
ContainerID: 91ea0bcd6c1f Pid: 2737993
ContainerID: 95b54dbb14d0 Pid: 2286
ContainerID: 9cc402cb9ca2 Pid: 2716
ContainerID: 9dab08f90039 Pid: 946124
ContainerID: ade4806bb944 Pid: 2518
ContainerID: aee2b96ee5d9 Pid: 2544
ContainerID: b3519e63725c Pid: 2737695
ContainerID: b5bd53932069 Pid: 2295
ContainerID: b816d668b027 Pid: 3962
ContainerID: c8198ad4cc28 Pid: 2543
ContainerID: d27c2a0c9a22 Pid: 1021592
ContainerID: e9bdb4ad0fd6 Pid: 2350
ContainerID: f41fa9aee395 Pid: 2737656
ContainerID: f56f55af0af3 Pid: 4065
ContainerID: fd272ecbe1bf Pid: 2737744
# grep 2738052
# outout
ContainerID: 41ef80123273 Pid: 2738052
# nerdctl ps | grep 41ef80123273
# output
41ef80123273 k8s-gcr.m.daocloud.io/kube-apiserver:v1.24.7 "kube-apiserver --ad…" 3 days ago Up k8s://kube-system/kube-apiserver-master01/kube-apiserver
# kubectl get pod -o wide --all-namespaces | grep kube-apiserver-master01
# output
kube-system kube-apiserver-master01 1/1 Running 11 (3d9h ago) 67d 10.29.15.79 master01 <none> <none>
总结
- pidstat -rsl 1 3 | awk ‘NR>1{if($7>40000000) print}’
-r 查看 pid 占用的内存信息,虚拟内存/实际使用内存/占总内存的百分比
-s 查看 pid 占用的内存堆栈
-l 显示详细的 command
- ps -elF | grep $PID
-e 所有进程
-L 显示线程,带有 LWP 和 NLWP 列,结合 -f 使用
-l 通常是输出格式的控制
-F 按指定格式打印进程/线程,信息更完整,结合 -el
-elF 可以找到其线程的 ppid,我的环境中一次就定位到 pid,说明 pod 没有其它的主进程或者更多的线程,而像业务 pod,一般都是用 shell 脚本拉起主进程,而主进程再启动更多的线程,如果要定为就是多次使用 ps -elF 进行 ppid 的查询,并最后通过 ppid 来找到该线程/进程是哪个容器和 pod 产生的
-efL 可以精确的统计每个进程的线程数
-ejH # 打印进程树、更直观
使用 TC 模拟容器内网络延迟
场景
- 模拟跨地域级别的请求,通过广域网的形式无法满足需求,因此使用 tc 来模拟请求链路上的延迟
前提
- 基础镜像需要安装 iproute、nmap-ncat
sh-4.2# yum install -y iproute nmap-ncat
sh-4.2# tc
Usage: tc [ OPTIONS ] OBJECT { COMMAND | help }
tc [-force] [-OK] -batch filename
where OBJECT := { qdisc | class | filter | action | monitor | exec }
OPTIONS := { -s[tatistics] | -d[etails] | -r[aw] | -p[retty] | -b[atch] [filename] | -n[etns] name |
-nm | -nam[es] | { -cf | -conf } path }
sh-4.2# nc
Ncat: You must specify a host to connect to. QUITTING.
sh-4.2# nc -vz 10.2x.16.2x 22
Ncat: Version 7.50 ( https://nmap.org/ncat )
Ncat: Connected to 10.2x.16.2x:22.
Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
sh-4.2# nc -vz 10.2x.16.2x 22
Ncat: Version 7.50 ( https://nmap.org/ncat )
Ncat: Connected to 10.2x.16.2x:22.
Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
配置规则
临时配置
- 添加规则,为了效果更明显这里我们设置为设置 100ms
[root@worker02 ~]# docker inspect `docker ps | grep centos | awk '{print $1}'` --format={{.State.Pid}}
299938
[root@worker02 ~]# nsenter -t 299938 -n tc qdisc add dev eth0 root handle 1: prio
[root@worker02 ~]# nsenter -t 299938 -n tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip dst 10.2x.16.2x/32 match ip dport 22 0xffff flowid 2:1
[root@worker02 ~]# nsenter -t 299938 -n tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip dst 10.2x.16.2x/32 match ip dport 22 0xffff flowid 2:1
[root@worker02 ~]# nsenter -t 299938 -n tc qdisc add dev eth0 parent 1:1 handle 2: netem delay 100ms
- 查看规则是否添加成功
[root@worker02 ~]# nsenter -t 299938 -n tc -s qdisc show dev eth0
qdisc prio 1: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 2: parent 1:1 limit 1000 delay 100.0ms
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
[root@worker02 ~]# nsenter -t 299938 -n tc -s filter show dev eth0
filter parent 1: protocol ip pref 1 u32 chain 0
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800: ht divisor 1
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800::800 order 2048 key ht 800 bkt 0 flowid 2:1 not_in_hw (rule hit 0 success 0)
match 0a1d101b/ffffffff at 16 (success 0 )
match 00000016/0000ffff at 20 (success 0 )
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800::801 order 2049 key ht 800 bkt 0 flowid 2:1 not_in_hw (rule hit 0 success 0)
match 0a1d1021/ffffffff at 16 (success 0 )
match 00000016/0000ffff at 20 (success 0 )
- 验证规则是否生效
# 验证 dst+port 的响应时长
[root@worker02 ~]# nsenter -t 299938 -n nc -vz 10.2x.16.2x 22
Ncat: Version 7.50 ( https://nmap.org/ncat )
Ncat: Connected to 10.2x.16.2x:22.
Ncat: 0 bytes sent, 0 bytes received in 0.11 seconds.
[root@worker02 ~]# nsenter -t 299938 -n nc -vz 10.2x.16.2x 22
Ncat: Version 7.50 ( https://nmap.org/ncat )
Ncat: Connected to 10.2x.16.2x:22.
Ncat: 0 bytes sent, 0 bytes received in 0.12 seconds.
# 验证非 dst+port 的响应时长
[root@worker02 ~]# nsenter -t 299938 -n nc -vz 10.2x.16.2x 22
Ncat: Version 7.50 ( https://nmap.org/ncat )
Ncat: Connected to 10.2x.16.2x:22.
Ncat: 0 bytes sent, 0 bytes received in 0.01 seconds.
# 再次查看匹配 tc filter 规则,发现已经匹配成功
[root@worker02 ~]# nsenter -t 299938 -n tc -s filter show dev eth0
filter parent 1: protocol ip pref 1 u32 chain 0
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800: ht divisor 1
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800::800 order 2048 key ht 800 bkt 0 flowid 2:1 not_in_hw (rule hit 15 success 5)
match 0a1d101b/ffffffff at 16 (success 5 )
match 00000016/0000ffff at 20 (success 5 )
filter parent 1: protocol ip pref 1 u32 chain 0 fh 800::801 order 2049 key ht 800 bkt 0 flowid 2:1 not_in_hw (rule hit 10 success 5)
match 0a1d1021/ffffffff at 16 (success 5 )
match 00000016/0000ffff at 20 (success 5 )
- 删除策略
tc -s qdisc del dev eth0 root
持久化配置
在 k8s 环境中,推荐使用 initContaiers 的 sidecar 模式来实现,yaml 如下:
kind: Deployment
apiVersion: apps/v1
metadata:
name: centos-centos
namespace: default
labels:
dce.daocloud.io/app: centos
spec:
replicas: 1
selector:
matchLabels:
dce.daocloud.io/component: centos-centos
template:
metadata:
name: centos-centos
creationTimestamp: null
labels:
dce.daocloud.io/app: centos
dce.daocloud.io/component: centos-centos
annotations:
dce.daocloud.io/parcel.egress.burst: '0'
dce.daocloud.io/parcel.egress.rate: '0'
dce.daocloud.io/parcel.ingress.burst: '0'
dce.daocloud.io/parcel.ingress.rate: '0'
dce.daocloud.io/parcel.net.type: calico
dce.daocloud.io/parcel.net.value: 'default-ipv4-ippool,default-ipv6-ippool'
spec:
initContainers:
- name: init-centos-tc
image: '10.2x.14x.1x/base/centos:7.9.2009'
command:
- /bin/sh
args:
- '-c'
- >-
yum install -y iproute nmap-ncat && tc qdisc add dev eth0 root
handle 1: prio && tc filter add dev eth0 parent 1:0 protocol ip
prio 1 u32 match ip dst 10.2x.16.2x/32 match ip dport 22 0xffff
flowid 2:1 && tc filter add dev eth0 parent 1:0 protocol ip prio 1
u32 match ip dst 10.2x.16.3x/32 match ip dport 22 0xffff flowid
2:1 && tc qdisc add dev eth0 parent 1:1 handle 2: netem delay
100ms
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
containers:
- name: centos-centos
image: '10.2x.14x.1x/base/centos:7.9.2009'
command:
- sleep
args:
- '3600'
resources:
requests:
cpu: '0'
memory: '0'
lifecycle: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: Always
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
imagePullSecrets:
- name: centos-centos-10.2x.14x.1x
schedulerName: default-scheduler
dnsConfig:
options:
- name: single-request-reopen
value: ''
- name: ndots
value: '2'
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
参考文档
TroubleShooting 事件记录
文件系统
意外断电导致系统启动失败
报错
- 环境: centos 7.9
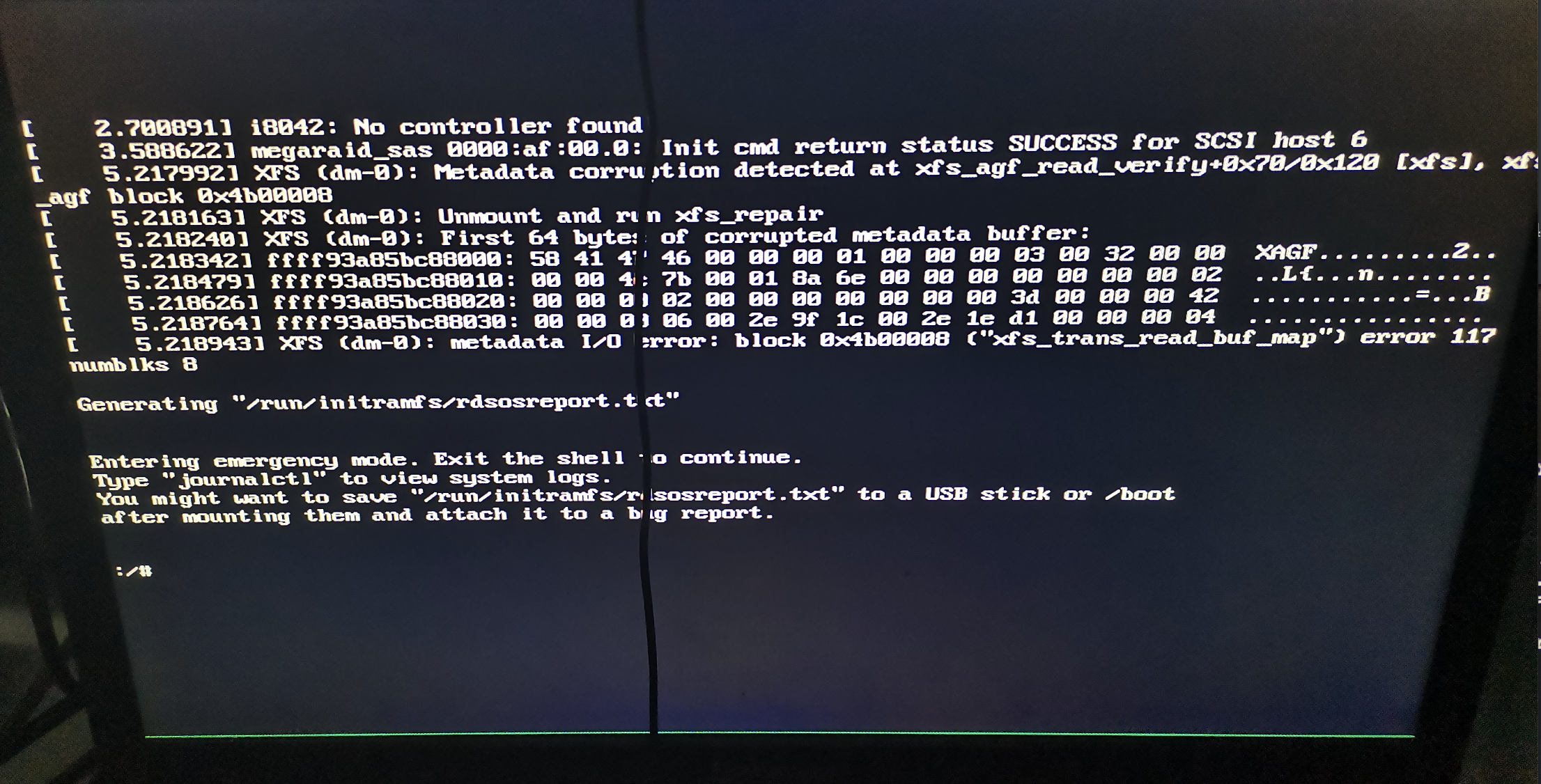
排查
- 根据图片看,系统已经入应急恢复模式,重启无法解决自行恢复,且文件系统是 xfs
- 查看先前系统所有配置的文件系统
# 检查机器硬件是否因断电导致损坏
- 机器运行正常
# 查看 /etc/fstab 文件,发现在该模式下,能看的只有 cat /etc/fstab.empty
cat /etc/fstab.empty # 为空
# 查看 /dev/sd* 设备
ls -l /dev/sd* # 发现有 3 个 sda 磁盘的分区 (sda1~3)
# 查看 /dev/mapper/ 目录下是否文件各文件系统
centos-root
centos-swap
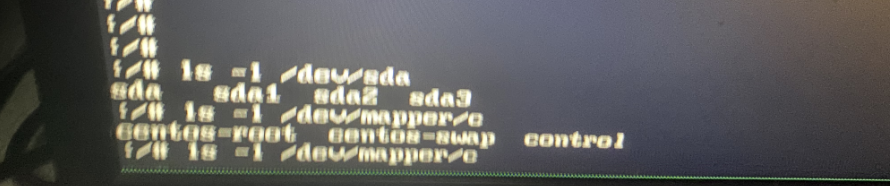
结论
- 根据查到的磁盘设备和文件系统,怀疑是 centos-root 根分区导致,因启动启动需要加载该分区下的配置,一次启动失败 (断电当时应用系统仍在写数据,导致该分区产生脏数据)
- 对于重要数据建议先备份再进行修复 [Backing Up and Restoring XFS File Systems][Backing Up and Restoring XFS File Systems]
修复
- 使用 xfs_repair 修复文件系统
xfs_repair /dev/mapper/centos-root
- 修复后重启,系统启动正常
- 建议备份下 /etc/fstab、及 lsblk 信息,再有此类文件可以清楚的看到之前分区表信息
参考链接
- Repairing an XFS File System
- Running repairs on XFS Filesystems [Backing Up and Restoring XFS File Systems]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/storage_administration_guide/xfsbackuprestore
break、continue、pass 语句、else 子句
介绍
- break 语句,可以用于跳出最近的 for / while 循环.
- else 子句,循环遍历所有元素/条件为假,才执行 else ;与 break 同时出现,则未执行 break 语句时,才会执行 else.
- pass 语句,相当于占位符,实际程序此时不执行任何操作.
code 示例:
print('学习1: 循环的 else 语句在未运行 break 时执行; 和 try ... else 类似,它是在子句未触发异常时执行')
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, 'equals', x, '*', n // x)
break
else:
print(n, 'is a prime number')
学习1: 循环的 else 语句在未运行 break 时执行,和 try ... else 类似,它是在子句未触发异常时执行
2 is a prime number
3 is a prime number
4 equals 2 * 2
5 is a prime number
6 equals 2 * 3
7 is a prime number
8 equals 2 * 4
9 equals 3 * 3
print('')
print('学习2: 利用 else 子句在循环最后打印结束语句')
test = ['test1', 'test2', 'test3']
for test_index in range(0, len(test)):
print(test[test_index])
else:
print('循环结束!!!')
学习2: 利用 else 子句在循环最后打印结束语句
test1
test2
test3
循环结束!!!
print('')
print('学习3: continue 子句, 进行匹配并打印出不匹配的')
for n in range(2, 8):
if n == 2:
print(n, '= 2')
continue
print(n)
学习3: continue 子句, 进行匹配并打印出不匹配的
2 = 2
3
4
5
6
7
print('')
print('学习4: pass 子句, 不执行任何操作,仅是语法需要这个语句, 相当于占位符')
number = [1, 2, 3, 4, 10]
for n in range(0, len(number)):
if number[n] != 10:
pass
else:
print(number[n])
学习4: pass 子句, 不执行任何操作,仅是语法需要这个语句, 相当于占位符
10
读写文件
open 函数使用
- 基础用法
open(str,mode,encodeing)
f = open('file1', 'a+')
f.wirte('this is test file1') # 只能是 str,记得用 str()、jsom.dumps() 方法转换下
print(f.read())
f.cloes()
print(f.closed)
- 进阶用法-会自动关闭文件
with open('file2', 'a+') af file:
file.wirte('thisi is test file2') # 只能是 str,记得用 str()、jsom.dumps() 方法转换下
fiLe.wirte('\n') # 多行时进行换行追加
- 文件读取
f.read() # 读取文件内容
f.readline() # 从文件中读取单行数据;字符串末尾保留换行符,多行时使用 for 遍历
for line in f:
print(line,end='')
open 函数读写模式
- mode
- r : 表示文件只能读取(default)
- w : 表示只能写入(现有同名文件会被覆盖)
- a : 表示打开文件并追加内容,任何写入的数据会自动添加到文件末尾
- r+ : 表示打开文件进行读写
docker SDK 的 简单使用
DockerClient 实例
- 导入 docker 库
import docker
1. 使用环境变量
client = docker.from_env()
2. 实例化 dockerClient
client = docker.Dockerclien(base_url="unix:/var/run/docker.sock", timeout=180, max_pool_size=200)
参数解读
- timeout(int):180 超时时间
- base_url: -- 2.dockerClient
- unix://var/run/docker.sock
- tcp://127.0.0.1:1234
- max_pool_size(int): 180 最大连接数
Login 函数
client.login(username='xxxx', password='xx@xxxxx', registry='x.x.x.x', reauth=True)
参数解读:
- reauth(bool): 说是可以覆盖 dockerClient 主机的认证信息,我尝试了几次并没覆盖
Pull 函数
1. 先登陆,后 pull
client.login(username='xxxx', password='xx@xxxxx', registry='x.x.x.x', reauth=True)
client.images.pull('x.x.x.x/xxxx/xxxx', tag='latest')
2. 直接带上认证信息进行 pull
auth = {
'username': 'xxxx',
'password': 'xx@xxxx'
}
client.images.pull('x.x.x.x/xxxx/xxxx', tag='latest',auth_config=auth)
参数解读:
- auth_config(dict): 定义一个 dict 类型的认证信息
- tag(str):如果不写,默认 latest
- all(bool): True 下载所有 tag
代码示例
import docker
client = client = docker.Dockerclien(base_url="unix:/var/run/docker.sock", timeout=180, max_pool_size=200)
auth = {
'username': 'xxxx',
'password': 'xx@xxxx'
}
# 使用 try ... except 进行处理和抛出异常
try:
client.images.pull('x.x.x.x/xxxx/xxxx', tag='latest',auth_config=auth)
except Exception as err:
print(err.__dice__)
部署遇到的问题
- docker sdk 作为容器的生命周期管理工具被 flask/diango 调用 push/pull/run 操作时,如果我们是 container 部署在 docker 主机上,需要将 docker.sock 文件挂载到容器内部、网络模式建议 host 模式,可以避免一些网络问题。也可以尝试使用 docker in docker 的方式
参阅文档
Request 使用
导入 reqeusts 模块
import requests
定义环境变量
- auth 信息
auth = ('admin', 'xxxxxxx')
- api 接口
url = ‘http://x.x.x.x/apis/apps/v1beata1/deployments’
使用 get 方法获取数据
- 定义 requests.get 方便变量
r = requests.get(url,auth)
- 打印 status_code
print(r.status.code)
配置管理
是指在编写Python代码时,为了提高灵活性和可配置性,通常会从环境变量或配置文件中获取应用程序的设置和参数。
-
配置管理是一种常见的软件开发实践
- 配置与代码逻辑分离,以便在不修改代码的情况下进行配置更改
- 通过获取环境变量或读取配置文件,可以动态调整应用程序的行为,而无需对代码进行更改
-
环境变量:可以方便的从操作系统或执行环境中获取配置信息,使得配置可以在不同的部署环境中进行自定义
-
配置文件:则提供了一种结构化和易于管理的方式来存储和组织配置选项
无论是获取环境变量还是读取配置文件,配置管理的目标是提供一种灵活、可维护和可配置的方式来管理应用程序的设置和参数。这使得应用程序更具适应性,并允许在不同环境中轻松配置和部署应用程序。
Python 获取环境变量 (OpenAI)
在Python中,你可以使用不同的方法来获取环境变量。下面是几种常见的方法:
- 使用
os模块:os模块提供了一种获取环境变量的简单方法。你可以使用os.environ字典来获取当前进程的所有环境变量,并使用变量名作为键来访问相应的值。例如:
import os
# 获取单个环境变量
value = os.environ.get('VAR_NAME')
# 打印所有环境变量
for var, value in os.environ.items():
print(f'{var}: {value}')
- 使用
os.getenv()函数:os模块还提供了getenv()函数,它可以直接获取指定环境变量的值。例如:
import os
value = os.getenv('VAR_NAME')
- 使用
environ模块:environ模块是os模块的一部分,可以直接从中导入。它提供了与os.environ相同的功能。例如:
from os import environ
value = environ.get('VAR_NAME')
这些方法都可以根据你的需求来选择使用。无论使用哪种方法,确保在访问环境变量之前,首先了解环境变量的存在与否,以及其命名方式。
python 解析和读取配置文件(OpenAI)
配置文件是一种常见的管理应用程序配置选项的方式。在Python中,有多种方法可以读取和解析配置文件。下面是一些常用的配置文件处理方法:
-
INI 文件:INI 文件是一种常见的配置文件格式,它由节(section)和键值对(key-value pairs)组成。Python中的
configparser模块提供了读取和解析 INI 文件的功能。示例 INI 文件(config.ini):
[Database] host = localhost port = 5432 username = myuser password = mypasswordimport configparser # 创建 ConfigParser 对象 config = configparser.ConfigParser() # 读取配置文件 config.read('config.ini') # 获取配置项的值 host = config.get('Database', 'host') port = config.getint('Database', 'port') username = config.get('Database', 'username') password = config.get('Database', 'password') -
JSON 文件:JSON 文件是一种常用的数据交换格式,也可以用作配置文件。Python内置的
json模块提供了读取和解析 JSON 文件的功能。示例 JSON 文件(config.json):
{ "Database": { "host": "localhost", "port": 5432, "username": "myuser", "password": "mypassword" } }import json # 读取配置文件 with open('config.json') as f: config = json.load(f) # 获取配置项的值 host = config['Database']['host'] port = config['Database']['port'] username = config['Database']['username'] password = config['Database']['password'] -
YAML 文件:YAML 是一种人类可读的数据序列化格式,也常用于配置文件。Python中的
pyyaml库可以用于读取和解析 YAML 文件。示例 YAML 文件(config.yaml):
Database: host: localhost port: 5432 username: myuser password: mypasswordimport yaml # 读取配置文件 with open('config.yaml') as f: config = yaml.safe_load(f) # 获取配置项的值 host = config['Database']['host'] port = config['Database']['port'] username = config['Database']['username'] password = config['Database']['password']
这些方法都可以根据你的需求来选择使用。选择适合你项目的配置文件格式,并使用相应的库来读取和解析配置文件。
如何写 Restful API 设计文档
编写 Flask API 的设计文档可以帮助开发人员和团队成员更好地理解和使用你的 API。下面的一些建议和内容,可以帮助你编写一个较完善的设计文档
介绍
- 简要介绍你的 API,包括其目的、功能和主要特点
- 提供使用示例或场景,一遍用户可以更好的理解 API 的用途
端点和路由
- 列出所有可用的端点和路由,以及每个端点的功能和预期行为
- 对于每个端点,包括 HTTP 方法(GET、POST、PUT 等)、URL路径和参数
- 如果有权限或身份验证要求,请提供相关信息
请求和响应
- 详细说明每个请求的有限载荷(Payload)格式和参数
- 对于 POST、PUT 等方法,指定请求的有效载荷格式和数据类型
- 对于每个响应,指定响应的状态码、数据格式、示例响应
错误处理
- 列出可能的错误情况和响应的状态码
- 对于每个错误情况,提供说明和示例响应,以及可能的解决方法
身份验证和权限
- 如果 API 需要身份验证和权限控制,请提供相关信息和说明
- 列出所有使用的身份验证方法(例如 JWT、OAuth)和授权机制
示例代码
- 提供 API 示例代码片段
- 说明如何发起请求,处理响应和处理错误
限制和性能
- 如果有任何限制或性能指标(如:请求速率、并发连接说、超时时间),请在文档中说明
常见问题和注意事项
- 理出常见文件和注意事项,帮助用户更好的使用 API
- 提供常见问题的解答或这项相关的文档资源
版本控制
-
如果计划对 API 进行版本控制,请提供 版本控制 的策略的方法
- API自带版本模式(Api 多个版本的形式,让用户自行选择使用)
- 兼容性版本模式 (Api 版本不变,通过内在 code 实现兼容性)
API 是与 Client 端链接的枢纽。打破旧的连接,就需要新版本。选择策略、制定计划、与 API 使用者沟通,这才是版本控制的最终目的
附录
- 在文档的末尾,提供额外的信息,如:术语表、参考文献或其他相关资源
总结
当编写 Flask API 的设计文档时,确保文档清晰、易于理解,并提供足够的示例和说明。这将帮助开发人员快速上手和正确使用你的 API